
-
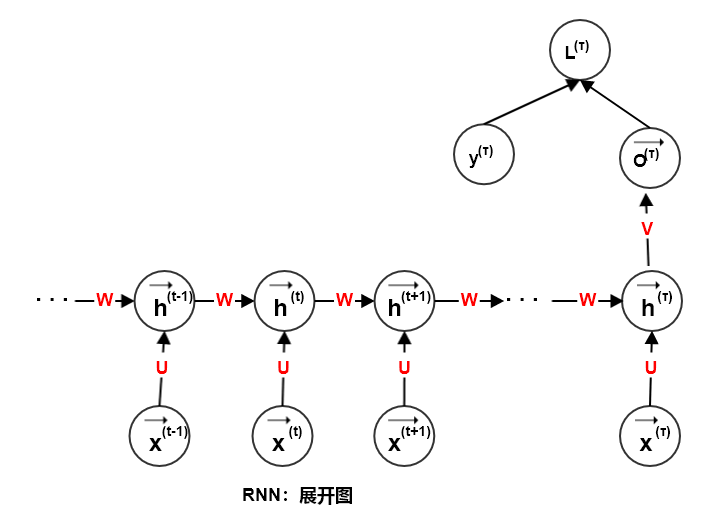
对于有限的时间步 ,应用
 次定义可以展开这个图:
次定义可以展开这个图:利用有向无环图来表述:

假设 为
 时刻系统的外部驱动信号,则动态系统的状态修改为: 。
时刻系统的外部驱动信号,则动态系统的状态修改为: 。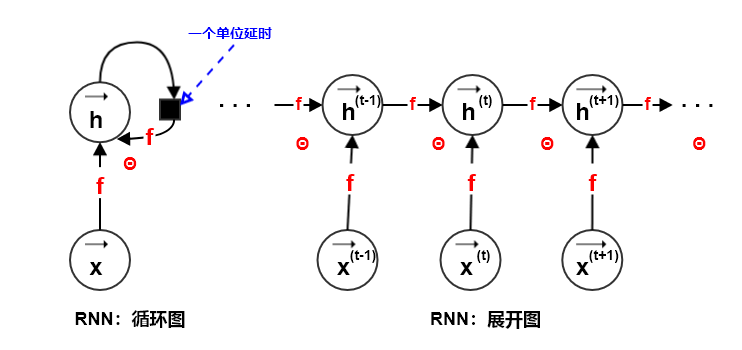
当训练根据过去预测未来时,网络通常要将 作为过去序列信息的一个有损的
representation。- 这个
representation一般是有损的,因为它使用一个固定长度的向量 来表达任意长的序列 。
来表达任意长的序列 。 - 根据不同的训练准则,
representation可能会有选择地保留过去序列的某些部分。如attention机制。
- 这个
网络的初始状态
 的设置有两种方式:
的设置有两种方式:固定为全零。这种方式比较简单实用。
这种情况下,模型的反向梯度计算不需要考虑 ,因为
全零导致对应参数的梯度贡献也为 0 。使用上一个样本的最后一个状态,即: 。
这种场景通常是样本之间存在连续的关系(如:样本分别代表一篇小说中的每个句子),并且样本之间没有发生混洗的情况。此时,后一个样本的初始状态和前一个样本的最后状态可以认为保持连续性。
另外注意:模型更新过程中
展开图的两个主要优点:
- 无论输入序列的长度
 如何,学得的模型始终具有相同的输入大小。因为模型在每个时间步上,其模型的输入 都是相同大小的。
如何,学得的模型始终具有相同的输入大小。因为模型在每个时间步上,其模型的输入 都是相同大小的。 - 每个时间步上都使用相同的转移函数
 ,因此需要学得的参数 也就在每个时间步上共享。
,因此需要学得的参数 也就在每个时间步上共享。
这些优点直接导致了:
- 使得学习在所有时间步、所有序列长度上操作的单个函数 成为可能。
- 允许单个函数 泛化到没有见过的序列长度。
- 学习模型所需的训练样本远少于非参数共享的模型(如前馈神经网络)。
- 无论输入序列的长度
基于图展开和参数共享的思想,可以设计不同模式的循环神经网络。根据输入序列的长度,
RNN网络模式可以划分为:输入序列长度为0、输入序列长度为1、输入序列长度为 。
。设样本集合为 ,其中每个样本为:
- 对于输入序列长度大于1的样本,
 ,其中 为第
,其中 为第  个样本的序列长度。
个样本的序列长度。
设样本对应的真实标记集合为 ,其中每个样本的标记为:
对于输出序列长度为1的样本,
 。对应的网络输出为: 。
。对应的网络输出为: 。对于输出序列长度大于1的样本,
 ,其中 为第 个样本的序列长度。
,其中 为第 个样本的序列长度。对应的网络输出为: 。
设真实标记
 为真实类别标签,网络的输出 为预测为各类别的概率分布(经过
为真实类别标签,网络的输出 为预测为各类别的概率分布(经过 softmax归一化的概率)。则该样本的损失函数为:
其中 为第
个时间步的损失函数。通常采用负的对数似然作为损失函数,则有:其中
 为类别的数量, 为
为类别的数量, 为  的第 个分量,
的第 个分量,  为示性函数:
为示性函数:如果将真实类别
 标记扩充为概率分布 ,其中真实的类别
标记扩充为概率分布 ,其中真实的类别  位置上其分量为 1,而其它位置上的分量为 0。则 就是真实分布
位置上其分量为 1,而其它位置上的分量为 0。则 就是真实分布  和预测分布 的交叉熵:
和预测分布 的交叉熵:
数据集的经验损失函数为:
.
- 对于输入序列长度大于1的样本,
1.2.1 零长度输入序列
输入序列长度为
0:此时网络没有外部输入,网络将当前时刻的输出作为下一个时刻的输入(需要提供一个初始的输出作为种子)。如文本生成算法:首先给定 作为种子,然后通过
时刻为止的单词序列来预测 时刻的单词;如果遇到某个输出为停止符,或者句子长度达到给定阈值则停止生成。在这个任务中,任何早期输出的单词都会对它后面的单词产生影响。
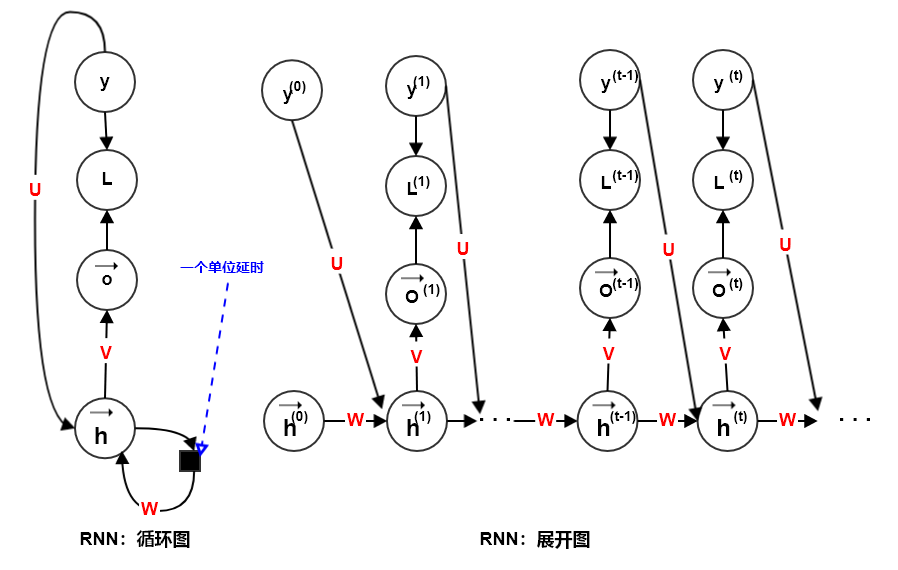
在零长度输入序列的 网络中,过去的输出序列 通过影响
 来影响当前的输出 ,从而解耦
来影响当前的输出 ,从而解耦  和 。
和 。该模型的数学表示为:

其中 表示模型第
步输出 的第  个分量。
个分量。单个样本的损失为:
更新方程:

其中输出到隐状态的权重为 ,隐状态到输出的权重为
 ,隐状态到隐状态的权重为 ,
,隐状态到隐状态的权重为 , 为输入偏置向量和输出偏置向量。
为输入偏置向量和输出偏置向量。
1.2.2 单长度输入序列
输入序列长度为
1:模型包含单个 作为输入。此时有三种输入方式:输入 作为每个时间步的输入、输入 作为初始状态
作为每个时间步的输入、输入 作为初始状态  、以及这两种方式的结合。
、以及这两种方式的结合。输入 作为每个时间步的输入:
模型的数学表示:

单个样本的损失:
更新方程:

其中输入到隐状态的权重为 ,输出到隐状态的权重为
 ,隐状态到输出的权重为 ,隐状态到隐状态的权重为
,隐状态到输出的权重为 ,隐状态到隐状态的权重为  , 为输入偏置向量和输出偏置向量。
, 为输入偏置向量和输出偏置向量。
输入
作为初始状态 :模型的数学表示:

单个样本的损失:
更新方程:

.
在图注任务中,单个图像作为模型输入,模型生成描述图像的单词序列。图像就是输入
,它为每个时间步提供了一个输入。通过图像和 时刻为止的单词序列来预测  时刻的单词。
时刻的单词。输出 有两个作用:用作
时刻的输入来预测 ;用于 时刻计算损失函数 。-
零输入
RNN的初始输出 是需要给定的,而这里的初始状态 是给定的。
是需要给定的,而这里的初始状态 是给定的。
1.2.3 多长度输入序列
多长度输入序列的
RNN包含了多输出&隐-隐连接RNN、多输出&输出-隐连接RNN、单输出&隐-隐连接RNN等网络类型。多输出&隐-隐连接循环网络:每个时间步都有输出,并且隐单元之间有循环连接。该网络将一个输入序列映射到相同长度的输出序列。
模型的数学表示:

更新方程:
其中输入到隐状态的权重为
,隐状态到输出的权重为 ,隐状态到隐状态的权重为 , 为输入偏置向量和输出偏置向量。
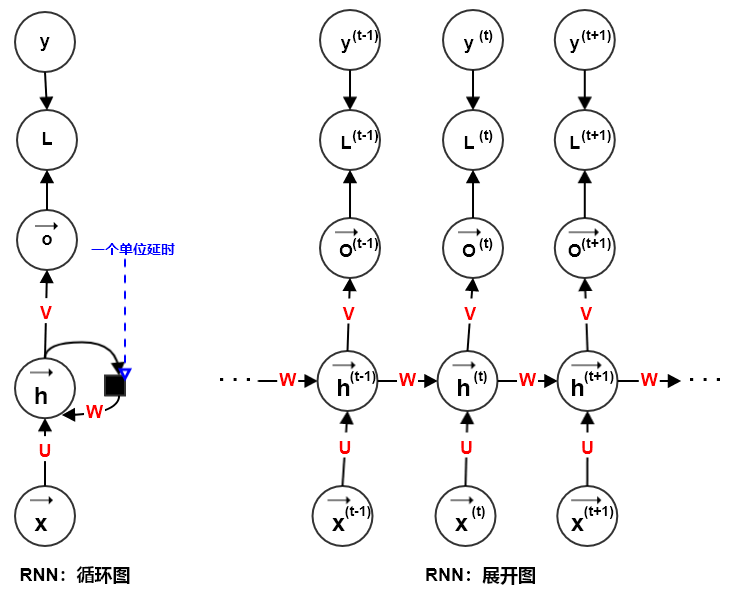
多输出&输出-隐连接循环网络:每个时间步都有输出,只有当前时刻的输出和下个时刻的隐单元之间有循环连接。该网络将一个输入序列映射到相同长度的输出序列。
模型的数学表示:
单个样本的损失:

更新方程:
其中输入到隐状态的权重为
,隐状态到输出的权重为 ,输出到隐状态的权重为 , 为输入偏置向量和输出偏置向量。
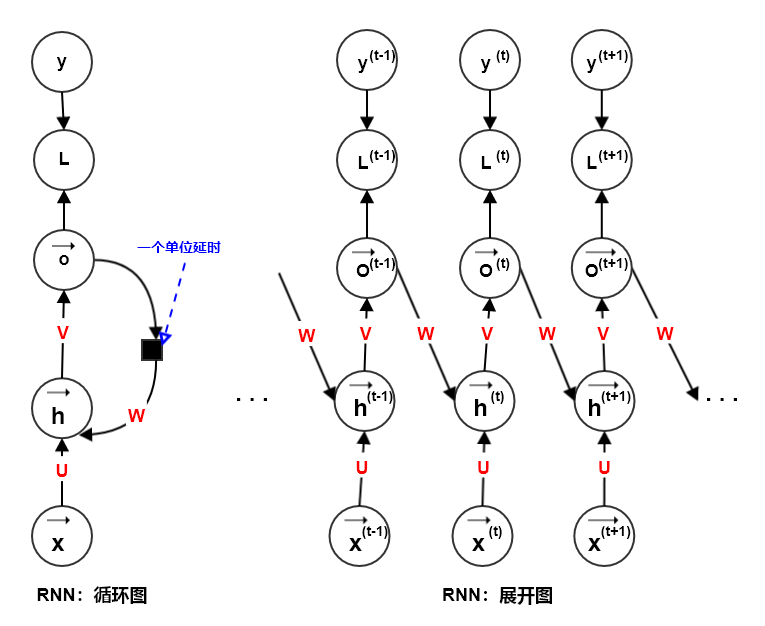
循环网络:隐单元之间存在循环连接,但是读取整个序列之后产生单个输出。
单输出&隐-隐连接RNN将一个输入序列映射到单个输出。模型的数学表示:
单个样本的损失:

更新方程:
其中输入到隐状态的权重为
,隐状态到输出的权重为 ,隐状态到隐状态的权重为 , 为输入偏置向量和输出偏置向量。
多输出&输出-隐连接循环网络比较于多输出&隐-隐连接循环网络,该网络的表达能力更小。多输出&隐-隐连接循环网络可以选择将其想要的关于过去的任何信息放入隐状态 中,并且通过 传播到未来。
传播到未来。多输出&输出-隐连接循环网络中只有输出 会被传播信息到未来。通常 的维度远小于 ,并且缺乏过去的重要信息。
的维度远小于 ,并且缺乏过去的重要信息。
多输出&输出-隐连接循环网络虽然表达能力不强,但是更容易训练:通过使用前一个时间步的真实标记 来代替输出 ,使得每个时间步可以与其他时间步分离训练,从而允许训练期间更多的并行化。
来代替输出 ,使得每个时间步可以与其他时间步分离训练,从而允许训练期间更多的并行化。
对于输入序列长度为零或者为
1的RNN模型,必须有某种办法来确定输出序列的长度。有三种方法来确定输出序列的长度:当输出是单词时,可以添加一个特殊的标记符。当输出遇到该标记符时,输出序列终止。
此时需要改造训练集,对训练数据的每个输出序列末尾手工添加这个标记符。
-
- 这种办法更普遍,适用于任何
RNN。 - 该二元输出单元通常使用单元,被训练为最大化正确地预测到每个序列结束的对数似然。
- 这种办法更普遍,适用于任何
在模型中引入一个额外的输出单元,该输出单元预测输出序列的长度
 本身。
本身。- 其原理是基于条件概率: 。

