
-
:一个布尔值,指定是否需要计算截距项。如果为
False,那么不会计算截距项。当 ,
 时, 可以设置
时, 可以设置 fit_intercept=False。intercept_scaling:一个浮点数,用于缩放截距项的正则化项的影响。当采用
fit_intercept时,相当于人造一个特征出来,该特征恒为1,其权重为 。在计算正则化项的时候,该人造特征也被考虑了。为了降低这个人造特征的影响,需要提供
intercept_scaling。tol:一个浮点数,指定判断迭代收敛与否的阈值。
LinearRegression是线性回归模型,它的原型为:fit_intercept:一个布尔值,指定是否需要计算截距项。normalize:一个布尔值。如果为True,那么训练样本会在训练之前会被归一化。copy_X:一个布尔值。如果为True,则会拷贝X。n_jobs:一个整数,指定计算并行度。
模型属性:
coef_:权重向量。intercept_: 值。
值。
模型方法:
fit(X,y[,sample_weight]):训练模型。predict(X):用模型进行预测,返回预测值。score(X,y[,sample_weight]):返回模型的预测性能得分。
1.2 Ridge
Ridge类实现了岭回归模型。其原型为:class sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True, normalize=False,copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None)
alpha: 值,用于缓解过拟合。max_iter: 指定最大迭代次数。tol:一个浮点数,指定判断迭代收敛与否的阈值。solver:一个字符串,指定求解最优化问题的算法。可以为:'auto':根据数据集自动选择算法。'svd':使用奇异值分解来计算回归系数。'cholesky':使用scipy.linalg.solve函数来求解。'sparse_cg':使用scipy.sparse.linalg.cg函数来求解。'lsqr':使用scipy.sparse.linalg.lsqr函数求解。它运算速度最快,但是可能老版本的
scipy不支持。'sag':使用Stochastic Average Gradient descent算法求解最优化问题。
random_state:用于设定随机数生成器,它在solver=sag时使用。其它参数参考
LinearRegression。
模型属性:
coef_:权重向量。intercept_: 值。n_iter_:实际迭代次数。
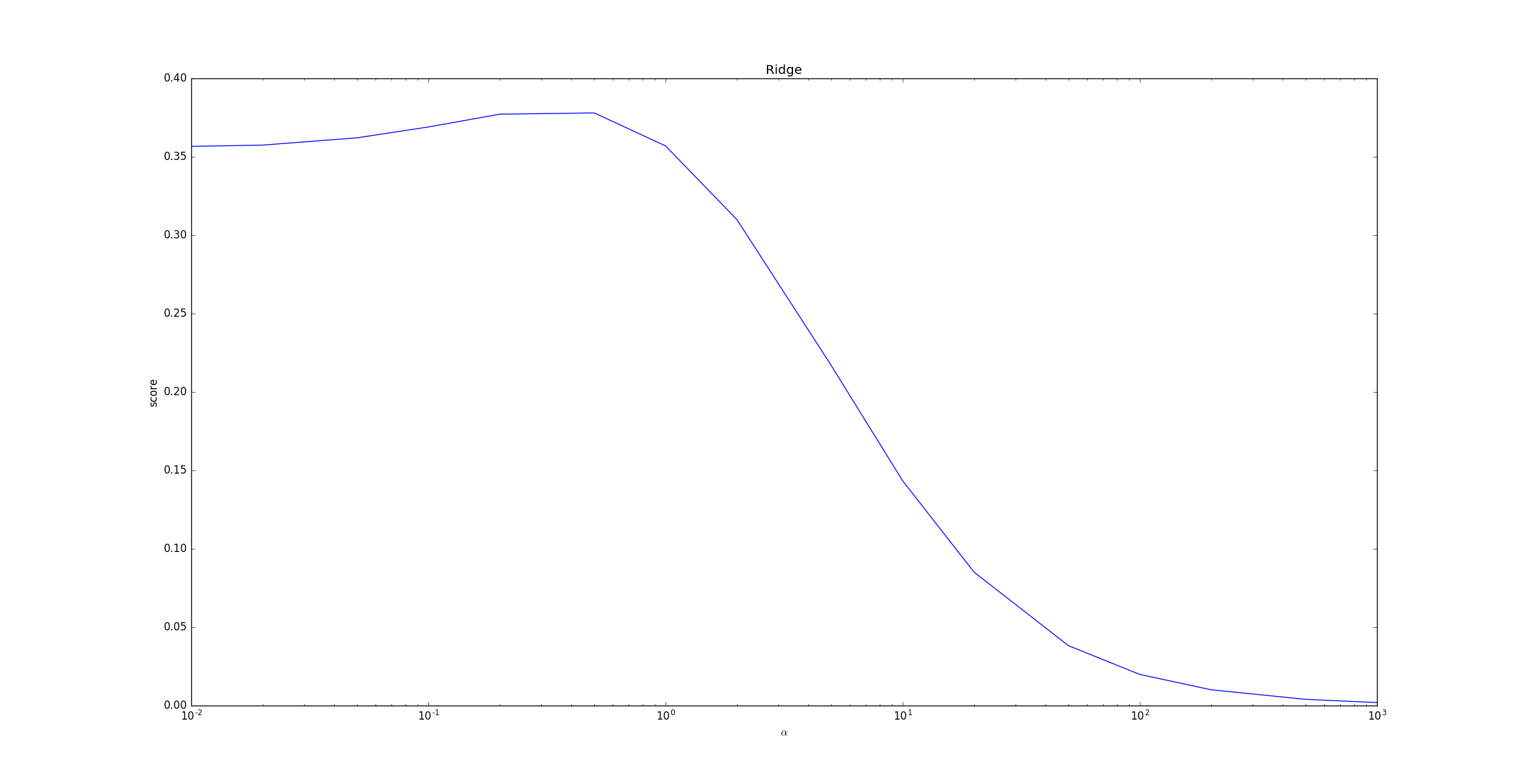
下面的示例给出了不同的 值对模型预测能力的影响。
当
 超过
超过 1之后,随着 的增长,预测性能急剧下降。这是因为
较大时,正则化项 影响较大,模型趋向于简单。极端情况下当
 时, 从而使得正则化项
时, 从而使得正则化项 ,此时的模型最简单。
,此时的模型最简单。但是预测预测性能非常差,因为对所有的未知样本,模型都预测为同一个常数 。
Lasso类实现了Lasso回归模型。其原型为:alpha: 值,用于缓解过拟合。precompute:一个布尔值或者一个序列。是否提前计算Gram矩阵来加速计算。warm_start:是否从头开始训练。:一个布尔值。如果为
True,那么强制要求权重向量的分量都为正数。selection:一个字符串,可以为'cyclic'或者'random'。它指定了当每轮迭代的时候,选择权重向量的哪个分量来更新。'random':更新的时候,随机选择权重向量的一个分量来更新'cyclic':更新的时候,从前向后依次选择权重向量的一个分量来更新
- 其它参数参考
Ridge。
模型属性:参考
Ridge。模型方法: 参考
LinearRegression。下面的示例给出了不同的
值对模型预测能力的影响。当 超过
1之后,随着 的增长,预测性能急剧下降。原因同Ridge中的分析。
1.4 ElasticNet
ElasticNet类实现了ElasticNet回归模型。其原型为:class sklearn.linear_model.ElasticNet(alpha=1.0, l1_ratio=0.5, fit_intercept=True,normalize=False, precompute=False, max_iter=1000, copy_X=True, tol=0.0001,warm_start=False, positive=False, random_state=None, selection='cyclic')
alpha: 值 。l1_ratio: 值 。- 其它参数参考
Lasso。
模型属性:参考
Lasso。模型方法:参考
Lasso。下面的示例给出了不同的
值和 值对模型预测能力的影响。随着
的增大,预测性能下降。因为正则化项为: 影响的是性能下降的速度,因为这个参数控制着 之间的比例 。
影响的是性能下降的速度,因为这个参数控制着 之间的比例 。
LogisticRegression实现了对数几率回归模型。其原型为:penalty:一个字符串,指定了正则化策略。- 如果为
'l2', 则为 正则化。
正则化。 - 如果为
'l1',则为 正则化。
- 如果为
dual:一个布尔值。- 如果为
True,则求解对偶形式(只在penalty='l2'且solver='liblinear'有对偶形式)。 - 如果为
False,则求解原始形式。
- 如果为
C:一个浮点数。它指定了罚项系数的倒数。如果它的值越小,则正则化项越大。class_weight:一个字典或者字符串'balanced',指定每个类别的权重。- 如果为字典:则字典给出了每个分类的权重。如
{class_label: weight}。 - 如果为字符串
'balanced':则每个分类的权重与该分类在样本集中出现的频率成反比。 - 如果未指定,则每个分类的权重都为
1。
- 如果为字典:则字典给出了每个分类的权重。如
solver:一个字符串,指定了求解最优化问题的算法。可以为下列的值:'lbfgs':使用L-BFGS拟牛顿法。'liblinear':使用liblinear。'sag':使用Stochastic Average Gradient descent算法。
注意:
- 对于规模小的数据集,
'liblinear'比较适用;对于规模大的数据集,'sag'比较适用。 'newton-cg'、'lbfgs'、'sag'只处理penalty='l2'的情况。
multi_class:一个字符串,指定对于多分类问题的策略。可以为:- :采用
one-vs-rest策略。 'multinomial':直接采用多分类logistic回归策略。
- :采用
- 其它参数参考
ElasticNet。
模型属性:参考
ElasticNet。模型方法:
fit(X,y[,sample_weight]):训练模型。predict(X):用模型进行预测,返回预测值。score(X,y[,sample_weight]):返回模型的预测性能得分。predict_log_proba(X):返回一个数组,数组的元素依次是X预测为各个类别的概率的对数值。predict_proba(X):返回一个数组,数组的元素依次是X预测为各个类别的概率值。
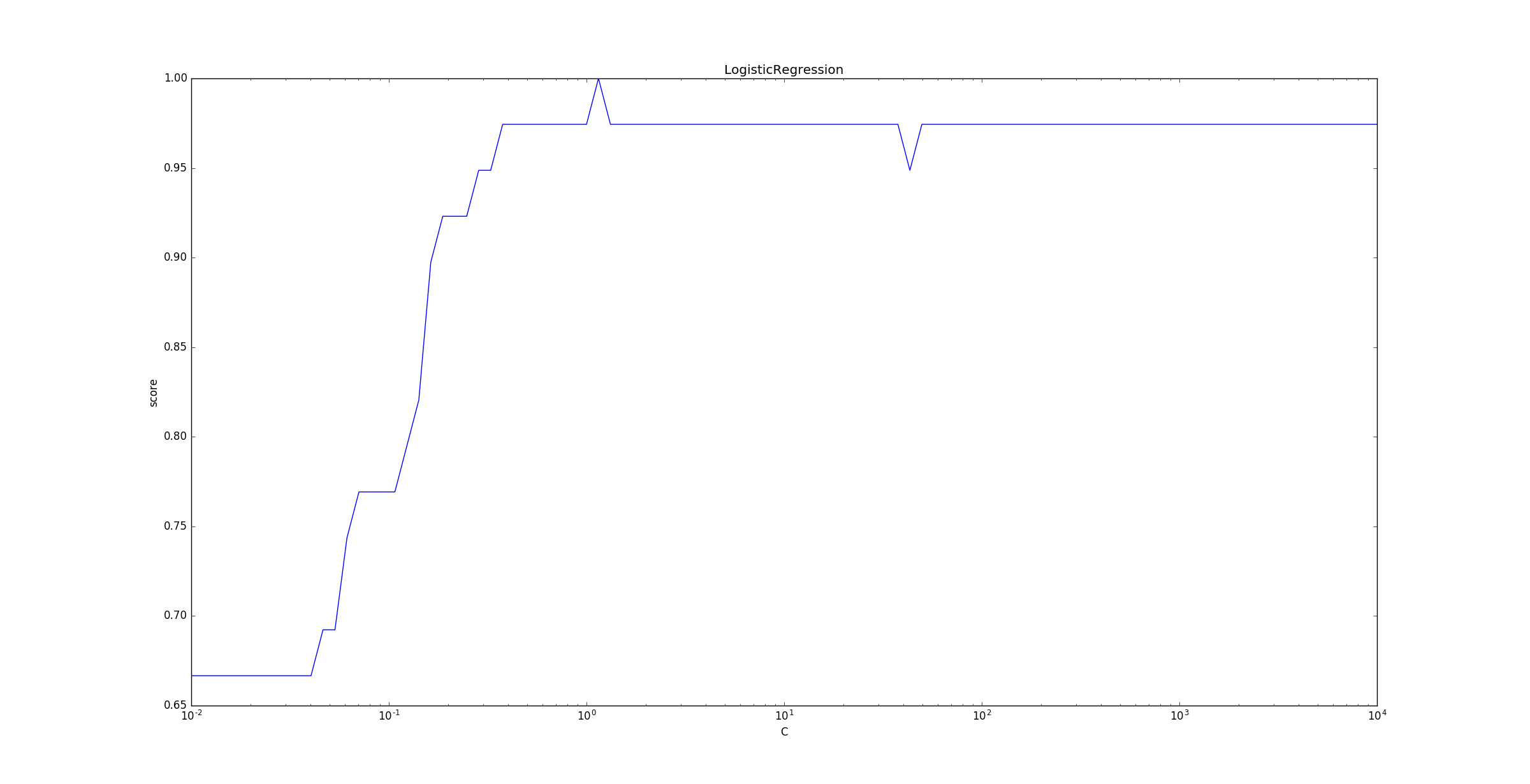
下面的示例给出了不同的
C值对模型预测能力的影响。C是正则化项系数的倒数,它越小则正则化项的权重越大。随着
C的增大(即正则化项的减小),LogisticRegression的预测准确率上升。当
C增大到一定程度(即正则化项减小到一定程度),LogisticRegression的预测准确率维持在较高的水准保持不变。
1.5 LinearDiscriminantAnalysis
类
LinearDiscriminantAnalysis实现了线性判别分析模型。其原型为:class sklearn.discriminant_analysis.LinearDiscriminantAnalysis(solver='svd',shrinkage=None, priors=None, n_components=None, store_covariance=False, tol=0.0001)
solver:一个字符串,指定求解最优化问题的算法。可以为:'svd':奇异值分解。对于有大规模特征的数据,推荐用这种算法。'lsqr':最小平方差算法,可以结合shrinkage参数。'eigen':特征值分解算法,可以结合shrinkage参数。
shrinkage:字符串'auto'或者浮点数或者None。该参数只有在
solver='lsqr'或者'eigen'下才有意义。当矩阵求逆时,它会在对角线上增加一个小的数 ,防止矩阵为奇异的。其作用相当于正则化。- 字符串
'auto':根据Ledoit-Wolf引理来自动决定 的大小。
的大小。 None:不使用shrinkage参数。- 一个
0到1之间的浮点数:指定 的值。
- 字符串
priors:一个数组,数组中的元素依次指定了每个类别的先验概率。如果为
None则认为每个类的先验概率都是等可能的。n_components:一个整数,指定了数据降维后的维度(该值必须小于n_classes-1)。store_covariance:一个布尔值。如果为True,则需要额外计算每个类别的协方差矩阵 。
。
模型属性:
coef_:权重向量。intercept_: 值。covariance_:一个数组,依次给出了每个类别的协方差矩阵。means_:一个数组,依次给出了每个类别的均值向量。xbar_:给出了整体样本的均值向量。- :实际迭代次数。

