
-
- 从经验中学习:避免了人工指定计算机学习所需的所有知识。
- 层次化的概念:计算机通过从简单的概念来构建、学习更复杂的概念。
如果绘制一张图来展示这些概念的关系,那么这张图是一个深度的层次结构,因此称这种方法为深度学习。
计算机需要获取大量的
"常识"才能以人工智能的方式行动,如:树叶是绿色的、乒乓球比足球小。这些
"常识"大部分是主观的和直观的,因此很难以正式的方式表达。一个问题是:如何将这些"常识"传给计算机。有两种方式将知识传递给计算机:
知识库(
knowledge base):通过形式化语言硬编码关于真实世界的知识,计算机使用逻辑推理自动推理这些硬编码的知识。最出名的知识库项目是
Cyc,但这些项目都没有取得重大成功。机器学习:
AI系统通过从原始数据中提取模式来获得知识,并作出看起来"智能"的决策。如:通过朴素贝叶斯算法分离正常的电子邮件和垃圾邮件。
传统机器学习算法严重依赖于数据的表达方式(
representation)。如:对病人的诊断中,AI系统并不是直接接触病人,而是由医生告诉AI系统关于病人的一些信息(如身高、体重等)。这些信息称作特征(feature)。传统机器学习算法在三个层面上严重依赖于数据的表达方式:
- 传统机器学习算法无法确定需要哪些特征。如:是直接给身高和体重,还是给出肥胖系数?
- 传统机器学习算法也无法确定这些特征的方式。如:是否将特征离散化?
- 某些信息,传统的机器学习算法无法学习。如:给出一份核磁共振的影像,由于每一个像素点与诊断结果相关性非常微小,因此传统机器学习算法无法学习。
这种对数据的表达方式的依赖是计算机科学甚至生活中的一般现象。
如:生活中人们很容易对阿拉伯数字进行算术运算,但是对于罗马数字的算术运算更费时间。
下图的线性分类任务中:左图采用笛卡尔坐标系,右图采用极坐标系。
可以看到数据的不同表达方式(坐标系的不同)导致左图难以线性分类,右图可以容易的线性分类。
特征设计的一个解决方案是:通过机器学习来发现特征。即:不仅学习
representation到输出的映射(即模型),也学习representation本身 。这称作表达学习(reprensentation learning)。往往比人为设计的特征的性能要好得多。
允许
AI系统快速适应新任务,用最少的人工干预。对于简单任务它可以在几分钟内学到一组好的特征,对于复杂任务可以在几小时到几个月的时间内学到一组好的特征。
在复杂任务中,人工设计特征需要消耗大量的人力和时间。
在设计特征或者学习特征时,一个良好的准则是:将能够解释数据的那些变化因子分离。
通常这些因子不是直接观察到的量,而是影响那些能够直接观察到的量。如:在语音识别中,变化因子就是:讲话者的年龄、性别、口音、讲话的单词等。在汽车相关的图片识别中,变化因子就是:汽车的位置、汽车的颜色、观察角度等。
在变化因子分离的过程中,有两个问题:
大多数因子仅仅影响观察到的数据的某个部分,因此需要分解这些影响数据的因子,提取我们关心的因子。
从原始数据中提取某些高级的、抽象的特征可能非常困难,这使得提取这种特征几乎和解决原始问题一样难。
如:说话者的口音只能用接近人类的、抽象的概念来表达。
深度学习在学习特征时采用的解决方案是:高级特征以低级特征来表示。即:通过组合简单的概念(
concept)来构建复杂的概念。如下所示的图片识别任务中,如果直接学习从一组像素到物体的映射很困难。深度学习通过将所需的复杂映射分解成一系列嵌套的简单映射来解决该问题。每个映射由模型的不同层来描述:
可见层为输入,因为它包含了能够观察到的变量。
第一层隐层:描述了边(
edge)的概念。通过比较相邻像素的亮度,则容易地识别边缘。第二层隐层:描述了角(
corner)和轮廓(contour)的概念。通过识别边的集合,则容易识别角。第三层隐层:描述了特定物体整体(如:人物)的概念(物体由特定的角/等高线集合组成)。通过识别轮廓和角的特点集合,则容易识别物体整体。
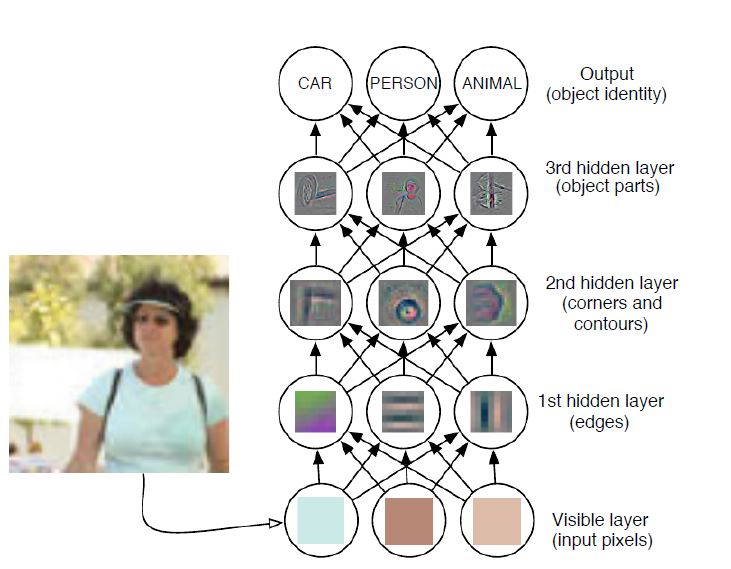
深度学习的一个经典案例是多层感知机(
multilayer perceptron:MLP)。深度学习的两个观点:
一个观点是:深度学习就是学习数据正确的
representaion,正如多层感知机所描述的。另一个观点是:深度学习让计算机学习一个多步计算程序:
- 更深层的网络可以按顺序地执行更多的指令。
- 序列越深的指令功能越强大,因为序列后面的指令可以参考序列前期指令的结果。
根据这种观点:每一层的中,并非所有的信息都对应了输入数据的特征信息,它还存储了辅助多步计算程序执行的状态信息:类似于计数器或者指针,它与输入的内容无关,但是有助于模型的组织处理过程。
深度学习的“深度”有两种度量方式。
第一种度量方式为:框架中必须执行的顺序指令的数量。
可以视为通过流程图的最长路径的长度,该流程图描述了如何根据输入来计算模型的输出。但是提供不同的函数单元,同一个模型可能具有不同的深度。
下图给出的是
logistic regression模型的深度。其中输出 , 为
为sigmoid函数。- 左图中:将加法、乘法、
sigmoid函数作为基本运算单元,则模型深度为 3。 - 右图中:将
logistic regression模型本身作为基本运算单元,则模型深度为 1 。
- 左图中:将加法、乘法、
第二种度量方式为:概念
concept图的深度。流程图的深度可能远远大于概念图本身,因为如果给定了复杂概念,则简单的概念可以得到更好的理解。
如:一个面部识别应用中,如果一只眼睛在阴影中,那么
AI最初只能看到一只眼睛。在检测到面部的存在后,AI可以推断出第二只眼睛很可能存在。此时概念图只有两层:眼睛为第一层、面部为第二层。但是此时计算概念图的流程图可能为
 层,其中 是对每个概念进行修正的次数。
层,其中 是对每个概念进行修正的次数。
对于模型的深度并没有一个标准的值,也没有说哪种度量方式是合适的。
- 究竟模型的深度值为多少才能称作“深”,也没有标准答案。
- 通常深度学习被认为是涉及大量的概念
concept的模型的学习。
深度是机器学习的一种,它是一种特定类型的机器学习,通过学习将世界表示为层次化嵌套的概念。
每个概念都由一些更简单的概念定义,更抽象的特征由不那么抽象的特征来计算。
下图给出了深度学习的隶属关系:深度学习 < 特征学习 < 机器学习 < 人工智能
AI。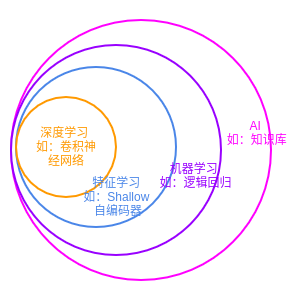
-
- 规则学习:硬编码知识。计算机所以无法、也不需要从数据中学习知识。
- 经典的机器学习:人工设计特征。计算机从数据中学习到了 “特征 —>
label” 之间的映射。 - 特征学习:机器从数据中自动学习到特征,然后学习到了 “特征 —>
label” 之间的映射。 - 深度学习:机器从数据中自动学习到了多层特征(深层特征由浅层特征来表达),然后学习到了 “特征 —> ” 之间的映射。

