
-
单词的
embedding有两种方式:- 基于无监督学习的文本
embedding通用性更强,可应用于各种类型的任务中。典型的无监督文本embedding方法包括SkipGram、Paragraph Vector等。 - 基于监督学习的文本
embedding效果更好,因为它可以充分利用task-specific的标记信息。典型的监督学习方法有CNN神经网络。
无监督文本
embedding方法具有很多优点:- 首先,深度神经网络,尤其是
CNN,在训练中需要大量的计算。 - 其次,
CNN网络通常需要大量的标记数据,而这在很多任务中是不现实的。 - 最后,
CNN的训练需要对很多超参数进行调优,这对专家而言非常耗时、对非专家而言甚至不可行。
但是和监督学习相比,无监督文本
embedding方法在task-specific上的预测效果较差。原因是这些文本embedding在学习文本embedding过程中没有利用任务中的任何标记信息。 - 基于无监督学习的文本
论文
《PTE:Predictive Text Embedding through Large-scale Heterogeneous Text Networks》提出了Predictive Text Embedding:PTE方法,它同时具有无监督文本embedding计算量小、标记数据需求低、无需复杂调参的优点,同时也利用了task-specific标记信息。PTE是一种半监督学习方法,它可以从有限的标记数据和大量的未标记数据中共同学习单词的有效低维representation。PTE首先通过word-word、word-doc、word-label不同level级别的共现构建一个大规模的异质文本网络Heterogeneous Text Network,然后将该异质网络嵌入到低维向量空间。PTE通过在低维向量空间中保持顶点之间的二阶邻近度来学习顶点的embedding。这种低维
embedding不仅保留了单词和文档之间的语义关系,还对task-specific具有很好的预测能力。一旦学到单词的
embedding,我们可以将句子/文档中单词embedding的均值作为句子/文档的embedding。我们在真实语料库上进行广泛实验,结果表明:
- 在各种文本分类任务中,
PTE的文本embedding都远远优于最新的无监督embedding方法 - 在和
CNN的对比中,PTE在长文本上效果更好、在短文本上效果和CNN相差无几。但是PTE计算效率更高、可以有效应用大规模未标记数据,并且对模型的超参数敏感性较低。
- 在各种文本分类任务中,
监督学习方法和无监督学习方法的主要区别在于如何在学习阶段利用标记信息和未标记信息。在
representation learning阶段:无监督学习不包含任何标记信息,仅在学到数据的
representation之后,才使用标记信息来训练下游的分类器。监督学习直接在学习过程中使用标记信息。
另外,监督学习也可以间接地使用未标记数据:通过无监督方法来预训练单词的
embedding。
和这两种方式相比,
PTE通过半监督方法来学习文本embedding:在学习阶段直接利用少量的标记数据和大量的未标记数据。DeepWalk和LINE均为无监督学习方法,它们只能处理同质网络。PTE扩展了LINE方法从而能够处理异质网络,并且能够融合监督信息。
PTE的基本思想是:在学习文本embedding时同时考虑标记数据和未标记数据。为了达到该目的,我们采用统一的表达形式来对这两种类型的数据进行编码。为此,我们提出了三种不同类型的网络,它们分别捕获了不同级别
level的单词共现信息 :word-word共现网络: 网络 ,其中 为词表集合, 为单词之间的边的集合。定义单词
为词表集合, 为单词之间的边的集合。定义单词  之间的权重 为:给定窗口大小的上下文窗口中,单词
之间的权重 为:给定窗口大小的上下文窗口中,单词  和 之间的共现次数。
和 之间的共现次数。 捕获了局部上下文中单词的共现信息,即
捕获了局部上下文中单词的共现信息,即word级别的信息。word-doc共现网络:网络 ,其中 为文档集合, 为单词和文档之间的链接。定义单词文档
为文档集合, 为单词和文档之间的链接。定义单词文档  之间的权重 为:单词 出现在文档 中的次数。
之间的权重 为:单词 出现在文档 中的次数。 是一个二部图,它捕获了文档中单词的共现的信息,即
是一个二部图,它捕获了文档中单词的共现的信息,即 doc级别的信息。word-label共现网络:网络 ,其中 为标签集合, 为单词和标签之间的链接。定义单词标签
为标签集合, 为单词和标签之间的链接。定义单词标签  之间的权重 为:单词 出现在类别为 的所有文档中的总次数。
之间的权重 为:单词 出现在类别为 的所有文档中的总次数。 也是一个二部图,它捕获了相同标签中单词的共现信息,即
也是一个二部图,它捕获了相同标签中单词的共现信息,即 label级别的信息。
定义异质文本网络
Heterogeneous Text Network为 的组合,它们捕获了不同级别的单词共现,并且同时包含了标记信息和未标记信息。异质文本网络也可以泛化为:集成不同
level信息的网络,如word-word网络、word-sentence网络、word-paragraph网络、word-doc网络、doc-label网络、word-label网络等。但是论文中我们仅以三种典型的网络为例。并且,我们重点关注word网络,以便将word嵌入到低维空间中。然后我们可以通过聚合word的embedding来计算其它文本单元(如sentence,paragraph,doc)的表示。给定大量为标记数据和部分已标记数据的文本数据,
Predictive Text Embedding:PTE问题的目标是:通过将数据集合构成的异质文本网络嵌入到低维向量空间中,从而学习单词的低维表示。由于异质文本网络由三个二部图组成,因此我们首先介绍单个二部图的
embedding方法。我们复用LINE模型来学习二部图的embedding,基本思想是:假设具有相似领居的顶点彼此相似,因此它们在低维空间中应该embed在一起。给定一个二部图
 ,其中 和
,其中 和  是两组不同顶点类型、且不相交的顶点集合, 为二部图的边。
是两组不同顶点类型、且不相交的顶点集合, 为二部图的边。令顶点
的 embedding为 ,定义给定 的条件下生成顶点 的概率为:
的条件下生成顶点 的概率为:
对于每个顶点 ,我们定义了一个条件概率分布
 ,这个条件概率分布的经验分布函数为:
,这个条件概率分布的经验分布函数为:其中
 为顶点 的度。
为顶点 的度。为了在低维空间中保留二阶邻近度,我们最小化目标函数:

其中 为两个分布之间的距离函数,通常选择为
KL散度; 为顶点 在网络中的重要性,通常选择为顶点
为顶点 在网络中的重要性,通常选择为顶点  的
的degree。如果忽略常数项,则我们得到目标函数:
我们可以采用带边采样
edge sampling和负采样nagative sampling的随机梯度下降法来求解该最优化问题。在梯度下降的每一步:- 首先以正比于权重
 的概率随机采样一条二元边
的概率随机采样一条二元边 binary edge,即edge sampling。 - 然后通过
noise distribution 来随机采样若干条负边,即
来随机采样若干条负边,即 nagative sampling。
- 首先以正比于权重
word-word网络、word-doc网络、word-label网络都可以使用上述目标函数来优化学习。事实上对于word-word网络我们可以将无向边视为两条有向边, 定义为有向边的源点、 定义为有向边的重点,则word-word网络就成为一个二部图。因此,异质文本网络由三个二部图组成,其中单词顶点在这三个网络之间共享。要学习异质文本网络的
embedding,最直观的方法是将三个二部图共享单词embedding:其中
 为相应的条件概率, 为相应的边权重。
为相应的条件概率, 为相应的边权重。该目标函数可以通过不同的方式优化,这取决于如何利用标记信息,即
word-label网络。一种方法是同时使用标记信息和未标记信息,我们称之为联合训练。
在联合训练过程中,我们同时训练三种不同类型的网络。在梯度更新过程中,我们轮流从三种类型的边中交替采样,从而更新模型。
另一种方法是:先从未标记信息中无监督学习
word embedding,然后在word-label中利用预训练的embedding对网络进行微调fine-tuning。该方法是受到深度学习中预训练pretrain和微调fine-tuning思想的启发。
-
输入:
- 异质文本网络

- 迭代次数 (也称作采样次数,或训练样本数量)
- 负采样数

- 异质文本网络
输出:所有单词的
embedding算法步骤:
循环迭代,直到迭代了
 个
个 step。迭代过程为:- 从 采样一条正边和 个负边,更新单词
embedding - 从 采样一条正边和 个负边,更新单词
embedding和doc embedding - 从 采样一条正边和 个负边,更新单词
embedding和label embedding。
- 从 采样一条正边和
PTE预训练和微调算法:输入:
- 异质文本网络
- 迭代次数 (也称作采样次数,或训练样本数量)
- 负采样数
算法步骤:
预训练阶段:循环迭代,直到迭代了
个 step。迭代过程为:- 从 采样一条正边和 个负边,更新单词
embedding - 从 采样一条正边和 个负边,更新单词
embedding和document embedding
微调阶段:循环迭代,直到迭代了 个
step。迭代过程为:- 从
 采样一条正边和 个负边,更新单词
采样一条正边和 个负边,更新单词 embedding和label embedding。
- 从 采样一条正边和
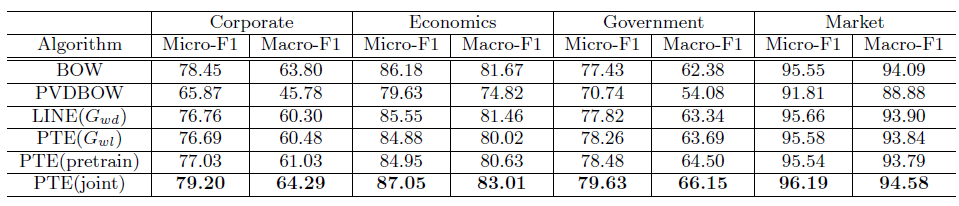
17.2 实验
数据集:我们选择了长文本、短文本两种类型的数据集:
长文本数据集:
20newsgroup数据集:广泛使用的文本分类数据集,包含 个类别。wiki数据集:2010年4月的维基百科数据集,包含大约200万篇英文文章。我们仅保留
2010年维基百科中出现的常见词汇。我们选择了七种不同类别,包括Art, History, Human, Mathematics, Nature, Technology, Sports。每种类别我们随机选择9000篇文章作为带标签的文档来训练。Imdb数据集:一个情感分类数据集。为避免训练数据和测试数据之间的分布偏差,我们随机混洗了训练数据和测试数据。RCV1数据集:一个大型文本分类基准语料库。我们从数据集中抽取了四个子集,包括Corporate, Economics, Government and Market。在RCV1数据集中,文档已经被处理为BOW的格式,因此单词的顺序已经被丢失。
短文本数据集:
DBLP数据集:包含来自计算机科学领域论文的标题。我们选择了六个方向的论文,包括database,arti cial intelligence, hardware, system,programming languages, theory等。对于每个方向,我们选择该方向具有代表性的会议并收集该会议中发表的论文作为带标签的文档。MR数据集:一个电影评论数据集,每条评论仅包含一句话。Twitter数据集:用于情感分类的Tweet语料库,我们从中随机抽取了120万Tweets然后拆分为训练集和测试集。
我们并没有在原始数据上执行进一步的文本归一化,如删除停用词或者词干化。下表给出了数据集的详细统计信息。

对比模型:
BOW:经典的BOW方法。每篇文档使用一个 维的向量来表达,向量第 个元素为单词 的
个元素为单词 的 TFIDF值。SkipGram:根据SkipGram训练得到单词的embedding,然后我们使用单词embedding的均值来作为文档的embedding。PVDBOW:一种paragraph embedding版本,其中文档内单词的顺序被忽略。PVDM:另一种paragraph embedding版本,其中文档内单词的顺序被考虑。LINE:我们使用LINE模型分别学习word-word网络和word-doc网络,分别记作 。另外,我们也考虑联合学习
。另外,我们也考虑联合学习 word-word网络和word-doc网络,记作 。CNN:基于CNN模型来监督学习文本embedding。尽管原始论文用于建模句子,我们这里将其改编为适用于长文本在内的一般单词序列。CNN也可以通过预训练无监督单词的embedding从而利用未标记数据。PTE:PTE有多种变体,它们使用word-word、word-doc、word-label的不同组合。 为仅使用
为仅使用 word-label的版本- 为使用
word-word和word-label的版本  为仅使用
为仅使用 word-doc和word-label的版本- 为使用
word-word、word-doc进行无监督训练,然后使用word-label来微调的版本 PTE(joint)为联合训练异质文本网络的版本
实验配置:
SkipGram,PVDBOW,PVDM,PTE,PTE模型:- 随机梯度下降的
mini-batch size设为1 - 学习率设为
 ,其中
,其中 T为总的迭代步数, - 负采样次数为
K=5
- 随机梯度下降的
SkipGram, PVDBOW,PVDM,PTE模型:共现窗口大小为5。CNN模型:我们使用《Convolutional neural networks for sentence classi cation》中的CNN结构。该结构使用一个卷积层,然后是最大池化层和全连接层。- 卷积层的窗口大小设为
3, feature map数量设为100- 随机选择训练集的
1%作为验证集来执行早停
- 卷积层的窗口大小设为
- 所有
embedding模型的词向量维度为100
评估方式:我们首先学习文档的
embedding,然后对不同的模型使用相同的训练数据和测试数据来执行分类任务。训练集中的所有文档都在
representation learning阶段和分类学习阶段使用。- 如果使用无监督
embedding方法,则在representation learning阶段不使用这些文档的类别标签,这些类别标签仅在分类学习阶段才使用。 - 如果使用
predictive embedding方法,则在representation learning阶段和分类学习阶段都使用文档的类别标签。
测试集中的所有文档在
representation learning阶段和分类评估阶段使用。注意:在representation learning阶段保留所有测试数据的标签,即这一阶段模型看不到测试数据的标签。在分类阶段我们使用
LibLinear软件包的one-vs-rest逻辑回归模型。最终我们通过分类的micro-F1和macro-F1指标来衡量模型效果。每一种配置我们都执行十次,并报告指标的均值和方差。
- 如果使用无监督
17.2.1 实验结果
我们在
20NG,Wiki,IMDB数据集上的长文本效果对比如下。首先我们比较无监督文本
embedding方法,可以看到: 的效果最好
的效果最好PVDM性能不如PVDBOW,这和原始论文中的结论不同。不幸的是我们始终无法得出他们的结论。
然后我们比较
predictive embedding方法,可以看到:或者
PTE(joint)效果最好。所有带
word-label网络PTE方法都超越了对应的无监督方法(即LINE模型),这表明了在监督学习下PTE的强大能力。PTE(joint)也超越了PTE(pretrain),这表明联合训练未标记数据和标记数据,要比将它们分别独立训练更有效。PTE(joint)始终优于CNN模型。另外我们通过
 学到的单词
学到的单词 embedding来对CNN进行预训练,然后使用label信息对其进行微调。出乎意料的是:预训练CNN在20NG和IMDB数据集上显著提高,并且在Wiki上几乎保持不变。这意味着训练良好的无监督embedding对CNN预训练非常有用。PTE(joint)也始终优于经典的BOW模型,经管PTE(joint)的embedding向量维度远小于BOW的向量维度。
我们在
RCV1数据集上的长文本效果对比如下。由于单词之间的顺序丢失,因此要求保留单词顺序信息的embedding方法不适用。这里我们观察到了类似的结论:predictive embedding方法超越了无监督embedding。PTE(joint)方法比PTE(pretrain)方法更有效。
我们比较了 和
PTE(joint)在IMDB数据集上的训练实践。我们采用异步随机梯度下降算法,在1T内存、2.0G HZ的40核CPU上执行。平均而言PTE(joint)要比CNN快10倍以上。在使用
pretrain时,CNN虽然训练速度加快,但是仍然比PTE(joint)慢 5倍以上。我们在短文本上比较了模型性能如下。
首先我们比较无监督文本
embedding方法,可以看到:效果最好。
使用局部上下文级别单词共现的
 要优于使用文档级别单词共现的 。这和长文本实验中结论相反。
要优于使用文档级别单词共现的 。这和长文本实验中结论相反。这是因为在短文本中,文档级别的单词共现非常稀疏。我们在主题模型中也观察到了类似的结果。
PVDM性能仍然不如PVDBOW性能,这和长文本中结论一致。
然后我们比较
predictive embedding方法,可以看到:PTE在DBLP,MR数据集上性能最佳,CNN在Twitter数据集上性能最好。融合了
word-label网络的PTE方法超越了对应的无监督embedding方法(即LINE模型),这和长文本中结论一致。PTE(joint)超越了 ,这证明了融合未标记数据的有效性。PTE(joint)超越了PTE(pretrain),这证明了对标记数据和未标记数据联合训练的优势。我们观察到
PTE(joint)并不能始终超越CNN。原因是单词歧义ambiguity问题,这类问题在短文本中更为严重。CNN通过在卷积核中使用局部上下文的单词顺序来减少单词歧义问题,而PTE抛弃了单词顺序。我们认为:如果利用了单词顺序,则PTE还有很大提升空间。
17.2.2 标记数据 & 未标记数据
我们考察标记样本规模的变化对
CNN和PTE的影响。我们考虑两种模式:- 监督学习:不包含未标记数据。如 、
CNN。 - 半监督学习:包含未标记数据。如
PTE(joint)、CNN等。
在半监督学习中,我们还比较了讲点的半监督方法:带
EM的朴素贝叶斯NB+EM、标签传播算法label propagation:LP。可以看到:
CNN和PTE随着标记数据规模的增加,性能持续改善。- 在监督学习的
CNN和 之间, 均优于CNN或可与CNN媲美。 - 在半监督学习的
CNN(pretrain)和PTE(joint)之间,PTE(joint)始终优于CNN(pretrain)。 PTE(joint)还始终优于经典的NB+EM和LP方法。
另外我们还注意到:
- 当标记数据规模不足时,使用无监督
embedding对CNN预训练非常有效,尤其是在短文本上。 - 当标记数据规模增加时,对
CNN的预训练并不总是能够改善其性能,如DBLP和MR数据集。 - 对于
SkipGram模型,增加标记数据规模几乎不会进一步改善其性能。 - 在
DBLP数据集上,当标记样本太少时PTE性能甚至不如SkipGram。原因是当标记数据太少时,word-label网络的噪音太多。PTE将word-label网络与噪音较少的word-word, word-doc网络同等对待。一种解决办法是:在标签数据不足时,调整word-label, word-word,word-doc网络的采样概率。
- 监督学习:不包含未标记数据。如
我们考察未标记样本规模的变化对
CNN(pretrain)和PTE的影响。由于篇幅有限,这里我们仅给出20NG和DBLP数据集的效果。在
20NG数据集上,我们使用10%文档作为标记数据,剩余文档作为未标记数据;在DBLP数据集上,我们随机抽取其它会议发表的20万篇论文的标题作为未标记数据。我们使用
 作为
作为 CNN的预训练模型。可以看到:- 当未标记数据规模增加时,
CNN和PTE性能都有改善。 - 对于
PTE模型,未标记数据和标记数据联合训练的效果要优于单独训练。
- 当未标记数据规模增加时,
17.2.3 参数敏感性与可视化
PTE模型除了训练步数T之外,大多数超参数对于不同训练集都是不敏感的(如学习率、batch size),所以可以使用默认配置。我们在
20NG和DBLP数据集上考察了PTE(joint)对于参数T的敏感性。可以看到:当T足够大时,PTE(joint)性能会收敛。实际应用中,我们可以将
T的数量设置称足够大。经验表明:T的合理范围是异质文本网络中所有边的数量的几倍。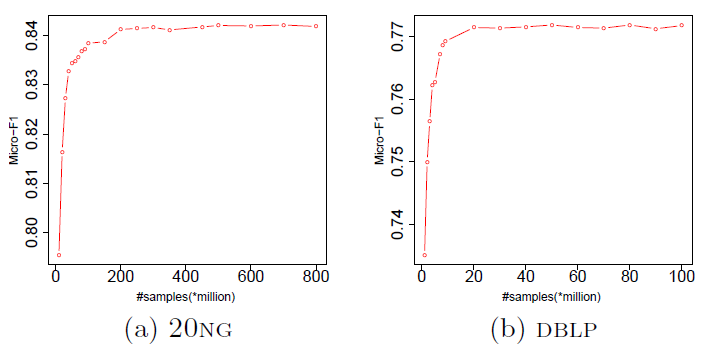
我们给出了无监督
embedding(以 为代表)和predictive embedding(以 为代表)在 20NG数据集上采用tSNE可视化的结果。我们对训练集和测试集的文档均进行了可视化,其中文档的
embedding为文档内所有单词的平均embedding。可以看到:在训练集和测试集上,predictive embedding均比无监督embedding更好地区分了不同的类别。这直观表明了predictive embedding在文本分类任务中的效果。
17.2.4 讨论
无监督
embedding使用的基本信息是局部上下文级别或者文档级别的单词共现。在长文本中,我们可以看到文档级别的单词共现比局部上下文级别的单词共现效果更好,并且二者的结合并不能进一步改善效果。
在短文本中,局部上下文级别的单词共现比文档级别的单词共现效果更好,并且二者的结合可以进一步改善效果。
这是因为文档级别的单词共现受到文本长度太短的困扰,即文本太稀疏。
predictive embedding中:与
PTE相比,CNN模型可以更有效地处理标记信息,尤其是在短文本上。这是因为CNN的模型结构比PTE复杂得多,尤其时CNN可以在局部上下文中利用词序从而解决单词的歧义问题。因此,在标记数据非常稀疏的情况下,
CNN可以超越PTE,尤其是在短文本上。但是这个优势是以大量的计算、详尽的超参数优化为代价的。与
CNN相比,PTE训练速度更快、超参数调整更容易(几乎没有需要调整的超参数)。当标记数据更为丰富时,PTE的性能至少和CNN一样好甚至更好。PTE模型的一个明显优势是它可以联合训练标记数据和未标记数据。相比之下CNN只能通过预训练来间接利用未标记数据。当标记数据非常丰富时,这种预训练并不总是有帮助的。
实践指南:
当没有标记数据时:
- 在长文本上使用 来学习无监督文本
embedding - 在短文本上使用 来学习无监督文本
embedding
- 在长文本上使用
-
- 在长文本上使用
PTE来学习文本embedding - 在短文本上使用
CNN(pretrain),其中预训练采用
- 在长文本上使用
当有大量标记数据时:
- 在短文本上从
PTE(joint)、CNN或者 三者之间选择,其中主要考虑训练效率和模型效果之间的平衡
- 在短文本上从

