-
Transformer首次由论文《Attention Is All You Need》提出,在该论文中Transformer用于encoder - decoder架构。事实上Transformer可以单独应用于encoder或者单独应用于decoder。 Transformer相比较LSTM等循环神经网络模型的优点:- 可以直接捕获序列中的长距离依赖关系。
- 模型并行度高,使得训练时间大幅度降低。
论文中的
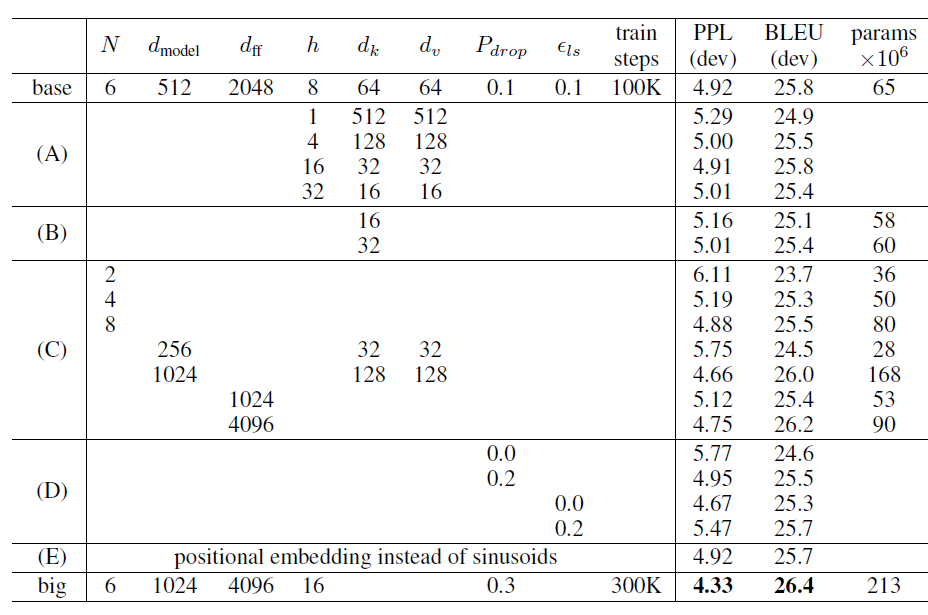
Transformer架构包含了encoder和decoder两部分,其架构如下图所示。Transformer包含一个编码器encoder和一个解码器decoder。编码器
encoder包含一组 6 个相同的层Layer,每层包含两个子层SubLayer。第一个子层是一个多头自注意力
multi-head self-attention层,第二个子层是一个简单的全连接层。每个子层都使用残差直连,并且残差直连之后跟随一个
layer normalization:LN。假设子层的输入为 ,则经过
LN之后整体的输出为: 。
。为了
Add直连,论文将内部所有层的输入、输出的向量维度设置为 维。
解码器
decoder也包含一组 6 个相同的层Layer,但是每层包含三个子层SubLayer。第一个子层也是一个多头自注意力
multi-head self-attention层。但是,在计算位置
 的
的 self-attention时屏蔽掉了位置 之后的序列值,这意味着:位置 的 attention只能依赖于它之前的结果,不能依赖它之后的结果。因此,这种
self-attention也被称作masked self-attention。第二个子层是一个多头注意力
multi-head attention层,用于捕获decoder output和encoder output之间的attention。第三个子层是一个简单的全连接层。
和
encoder一样:- 每个子层都使用残差直连,并且残差直连之后跟随一个
layer normalization:LN。 decoder所有层的输入、输出的向量维度也是 维。
- 每个子层都使用残差直连,并且残差直连之后跟随一个
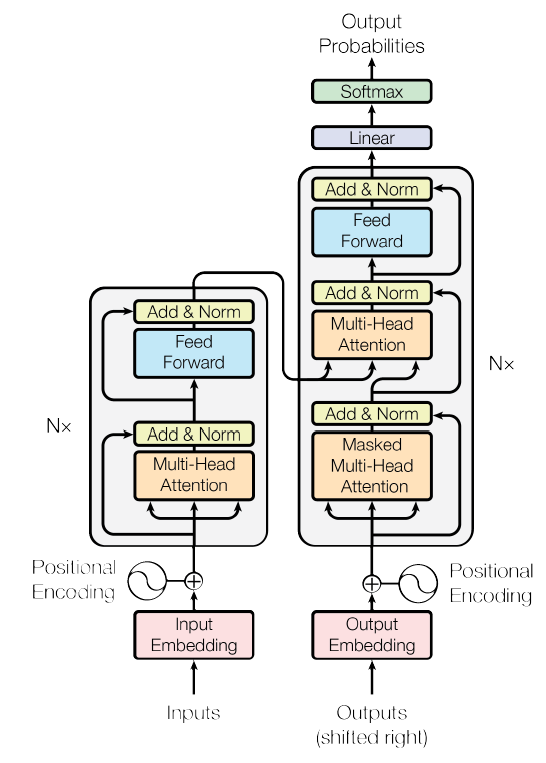
1.1.1 attention
编码器和解码器的
attention都是采用scaled dot attention。设有 个
query向量 、 个
、 个 key向量 、 个
、 个 value向量 ,其中
,其中 query向量和key向量的维度为 ,value向量的维度为 。经过
。经过 attention之后,位置 的输出为:
其中 表示位置
 与位置 之间的权重:
与位置 之间的权重:
除以 是为了降低
 的数值,防止它落入到
的数值,防止它落入到 softmax函数的饱和区间。因为
softmax函数的饱和区梯度几乎为 0 ,容易发生梯度消失。如果使用了
Masked attention,则有:令:

则有:
令:
 ,其中
,其中 softmax沿着矩阵的行归一化。令:则有:
 。即:
。即:
事实上,一组多个
attention的效果要优于单个attention,这称作multi-head attention。给定
query矩阵 、key矩阵 、
、value矩阵 ,multi-head attention的head i先通过一个线性映射然后再经过attention,得到head i的输出 :
:其中:
 将 个
将 个 query向量 从 维降低到
从 维降低到  维。
维。- 将
 个
个 key向量 从 维降低到 维。
维降低到 维。  将 个
将 个 value向量 从 维降低到
从 维降低到  维。
维。
将多个
head i的输出 进行拼接,并再经过一个线性映射即可得到多头attention的结果:其中:
a为head的数量, 是为了确保
是为了确保multi-head attention前后的输入输出维度一致。
论文中选择
 。为了保证
。为了保证 multi-head attention的表达空间与single-head attention一致,论文中选择:将整个
attention空间拆分成多个attention子空间,其表达能力更强。从原理上看,
multi-head相当于在整体计算代价几乎保持不变的条件下,引入了更多的非线性从而增强了模型的表达能力。在论文中,有三种方式使用多头注意力机制:
encoder-decoder attention:query来自前一个decoder层的输出,keys,values来自encoder的输出。其意义是:
decoder的每个位置去查询它与encoder的哪些位置相关,并用encoder的这些位置的value来表示。encoder self-attention:query,key,value都来自前一层encoder的输出。这允许
encoder的每个位置关注encoder前一层的所有位置。decoder masked self-attention:query,key,value都来自前一层decoder的输出。这允许
decoder的每个位置关注encoder前一层的、在该位置之前的所有位置。
1.1.2 全连接层
encoder和decoder还包含有全连接层。对encoder/decoder的每个attention输出,全连接层通过一个ReLU激活函数以及一个线性映射:
- 对于同一个
multi-head attention的所有 个输出,采用相同的参数;对于不同的multi-head attention的输出,采用不同的参数。 - 输入和输出的维度保持为
 ,但是中间向量的维度是 2048 维,即 。这是为了扩充中间层的表示能力,从而抵抗
,但是中间向量的维度是 2048 维,即 。这是为了扩充中间层的表示能力,从而抵抗 ReLU带来的表达能力的下降。
- 对于同一个
1.1.3 embedding 层
网络涉及三个
embedding层:encoder输入embedding层:将encoder输入token转化为 维的向量。
维的向量。decoder输入embedding层:将decoder输入token转化为 维的向量。decoder输出embedding层:将decoder输出token转化为 维的向量。
在论文中这三个
embedding矩阵是共享的,并且论文中在embedding层将该矩阵乘以一个常量 来放大每个权重。
1.1.4 position embedding
从
attention的计算公式 可以看到:调整输入的顺序对
可以看到:调整输入的顺序对 attention的结果没有任何影响。即:attention的输出中不包含任何顺序信息。事实上输入的顺序对于很多任务是非常重要的,比如
我喜欢喝牛奶,而不喜欢喝咖啡与我喜欢喝咖啡,而不喜欢喝牛奶的语义完全不同。论文通过将位置编码添加到
encoder和decoder底部的输入embedding来解决问题。即有:其中
 为位置 的
为位置 的position embedding,
attention权重与位置有关。对于同一个输入序列如果打乱序列顺序,则不同
token的attention权重发生改变使得attention的结果不同。位置编码有两种选择:
可以作为参数来学习,即:将
encoder的每个输入的位置embedding、decoder的每个输入的位置embedding作为网络的参数,这些参数都从训练中学得。也可以人工设定固定值。论文中使用:
其中
 表示位置编号, 表示向量的维度。
表示位置编号, 表示向量的维度。不同的维度对应不同的波长的正弦曲线,波长从
 到 。
到 。选择这样的函数是因为:不同位置之间的
embedding可以简单的相互表示。即:对于给定的偏移量 , 可以表示为
, 可以表示为  的线性函数。
的线性函数。这意味着模型可以捕获到位置之间的相对位置关系。
论文的实验表明:通过参数学习的
position embedding的效果和采用固定的position embedding相差无几。另外,固定方式的
position embedding可以在测试阶段处理那些超过训练序列长度的测试序列。
假设输入序列长度为 ,每个元素的维度为
 : 。输出序列长度也为
: 。输出序列长度也为  ,每个元素的维度也是 :
,每个元素的维度也是 : 。
。可以从每层的计算复杂度、并行的操作数量、学习距离长度三个方面比较
Transformer、CNN、RNN三个特征提取器。-
- 考虑到
n个key和n个query两两点乘,因此self-attention每层计算复杂度为
- 考虑到矩阵(维度为
nxn) 和输入向量相乘,因此RNN每层计算复杂度为 - 对于 个卷积核经过 次一维卷积,因此
CNN每层计算复杂度为 。如果考虑深度可分离卷积,则计算复杂度下降为 。
。
因此:
当 时,
self attention要比RNN和CNN快,这也是大多数常见满足的条件。当
 时,可以使用受限
时,可以使用受限 self attention,即:计算attention时仅考虑每个输出位置附近窗口的 个输入。这带来两个效果:- 每层计算复杂度降为

- 每层计算复杂度降为
- 最长学习距离降低为 ,因此需要执行
 次才能覆盖到所有输入。
次才能覆盖到所有输入。
- 考虑到
并行操作数量:可以通过必须串行的操作数量来描述。
- 对于
RNN,其串行操作数量为 ,较难并行化。
- 对于
最长计算路径:覆盖所有输入的操作的数量。
- 对于
self-attention,最长计算路径为 ;对于
;对于 self-attention stricted,最长计算路径为 。 - 对于常规卷积,则需要
 个卷积才能覆盖所有的输入;对于空洞卷积,则需要 才能覆盖所有的输入。
个卷积才能覆盖所有的输入;对于空洞卷积,则需要 才能覆盖所有的输入。 - 对于
RNN,最长计算路径为 。
。
- 对于
-
- 作为额外收益,
self-attention可以产生可解释性的模型:通过检查模型中的注意力分布,可以展示与句子语法和语义结构相关的信息。
训练包含两个训练数据集:
WMT 2014 English - German数据集:包含 450万句子对,每个句子通过byte-pair encoding:BPE编码。BPE编码首先将所有文本转换为Unicode bytes,然后将其中出现次数较高的、连续的一组bytes用一个token替代。- 源句和翻译句共享词汇表,包含 37000个
token。
WMT 2014 English-French数据集:包含 3600万句子对,每个句子通过BPE编码。源句和翻译句共享词汇表,包含 32000个
token。
训练在
8 NVIDIA P100 GPU上,相近大小的句子对放到一个batch里,每个训练batch包含大约 25000个源token和 25000个 翻译token。优化器采用
Adam optimizer, 。学习率为:
其中 。
训练在基础版本上执行 10 万步约12个小时,在大型版本上(更大的参数)执行 30 万步约 3.5 天。
通过两种方式进行正则化:
dropout:residual dropout:在每个子层添加到ADD & LN之前执行dropout, 。
。embedding dropout:在encoder和decoder添加position embedding之后,立即执行dropout, 。
label smoothing::训练期间使用 的
的label smoothing。虽然这会降低模型的困惑度,因为模型学到了更大的不确定性,但是这会提高
BLEU。
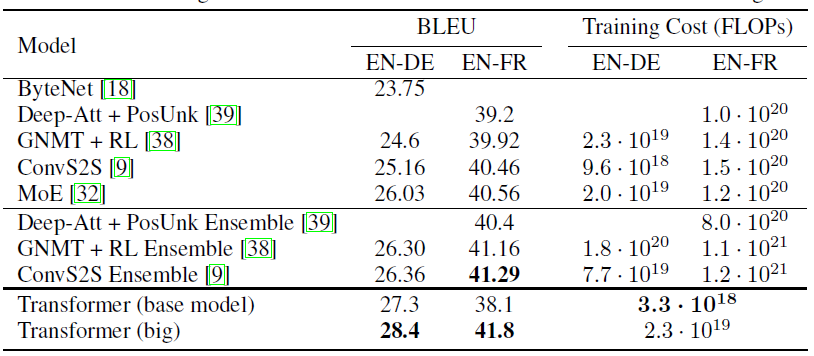
在
WMT 2014 English-German/ WMT 2014 English-French翻译任务上,各种模型的效果如下图:训练参数:见后一个表的最后一行。
超参数选择:使用
beam size = 4、长度惩罚因子 的beam search,超参数在验证集上选择。训练代价
FLOPs:通过训练时间、训练GPU个数、每个GPU的单精度浮点计算能力三者相乘得到估计值。对于
base model,采用单个模型的最后 5 个checkpoint的平均(10分钟生成一个checkpoint)。对于
big model,采用单个模型的最后 20个checkpoint的平均。
为了评估不同参数的影响,论文在
English-German翻译任务中采用不同的模型,评估结果是newstest2013验证集上得到。beam search参数同前,但是并没有采用checkpoint平均的策略。PPL困惑度是在word-piece上得到的。考虑到BPE编码,这和word级别的困惑度有所出入。为空的参数表示和
base模型一致。(A)展示了不同attention head和attention key/value dimension的影响。为了保持模型参数不变,二者需要满足一定条件。结果表明:单头的效果要比多头模型差,但是头数太多也会导致效果下降。
(B)展示了不同的attention key的影响。结果表明:降低 会带来性能下降。因为降低
会降低模型的 attention矩阵 的容量,从而降低模型的整体表达能力。(C)展示了不同大小模型的影响。结果表明:模型越大,性能越好。
(E)展示了通过学习position embedding(而不是固定的position embedding)的影响。结果表明:这两种 策略的效果几乎相同。