
-
这些用户历史行为数据具有两个显著特点:
多样性:用户在访问电商网站时,可能对各种各样的商品感兴趣。如:一个年轻的母亲可能同时对包包、鞋子、耳环、童装等感兴趣。
局部激活
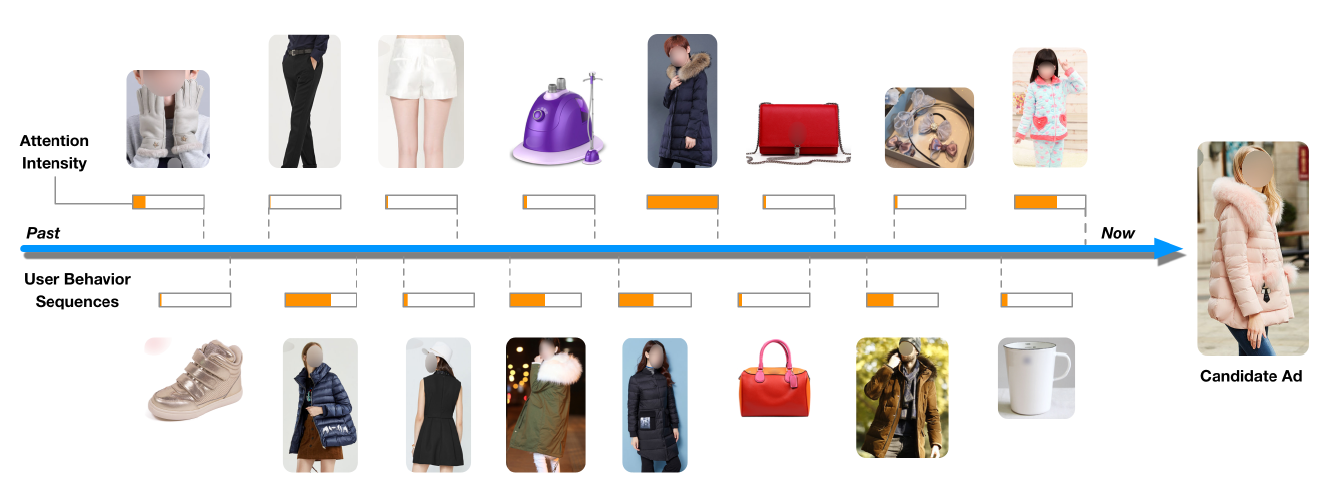
local activation:用户是否点击当前商品仅取决于历史行为数据中的部分数据,而不是全部历史行为数据。如:一个游泳用户会点击推荐的护目镜,主要是因为曾经购买过泳衣,而不是因为最近曾经购买的手机。
如,从淘宝线上收集的用户行为案例:
常见的
DNN模型缺乏针对性的深入了解、利用用户历史行为数据的结构。这些模型通常都是在embedding层之后添加一个池化层,通过使用sum pooling或者avg pooling,从而将用户的一组历史行为embedding转化为固定尺寸的embedding向量。这将导致部分信息丢失,从而无法充分利用用户丰富的历史行为数据。论文
《Deep Interest Network for Click-Through Rate Prediction》提出了深度兴趣网络Deep Interest network:DIN模型,该模型通过兴趣分布来刻画用户的不同兴趣,并针对候选广告(淘宝的广告也是一种商品)设计了类似attention的网络结构来激活局部的相关兴趣,使得与候选广告相关性更高的兴趣获得更高的权重。另外,论文为了解决过拟合问题提出了一种有效的自适应正则化技术。
展示广告系统
display advertising system的应用场景如下所示。当用户访问电商网站时:- 首先检查用户的历史行为数据
- 然后根据
matching模块召回候选广告集 - 接着根据
ranking模块预测用户对每个广告的点击率,挑选出点击率最高的一批广告 - 最后曝光广告并记录用户的行为
注意:电商领域的广告也是一种商品。即:被推广的目标就是广告主期望售卖的商品。
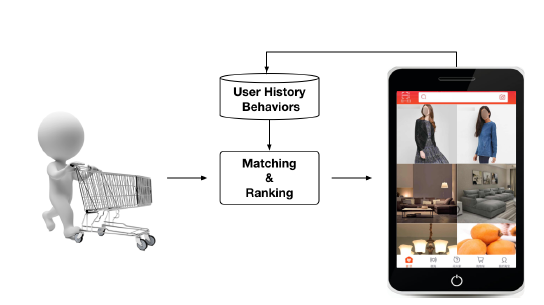
与搜索广告不同,大部分用户进入展示广告系统时并没有明确的兴趣意图。因此我们需要从用户的历史行为数据中有效抽取用户兴趣。
样本原始特征由稀疏
ID组成,我们将其划分为四组:- 用户画像特征:包括用户基础画像如年龄、性别等。
- 用户行为特征:包括用户历史访问的商品
id、历史访问的店铺id、历史访问的商品类别id等。 - 广告特征:包括广告的商品
id、店铺id、商品类别id等。 - 上下文特征:包括访问时间等。
这里不包含任何交叉特征,交叉特征由神经网络来捕获。
DIN模型(右图)和基准模型Base Model(左图)如下图所示。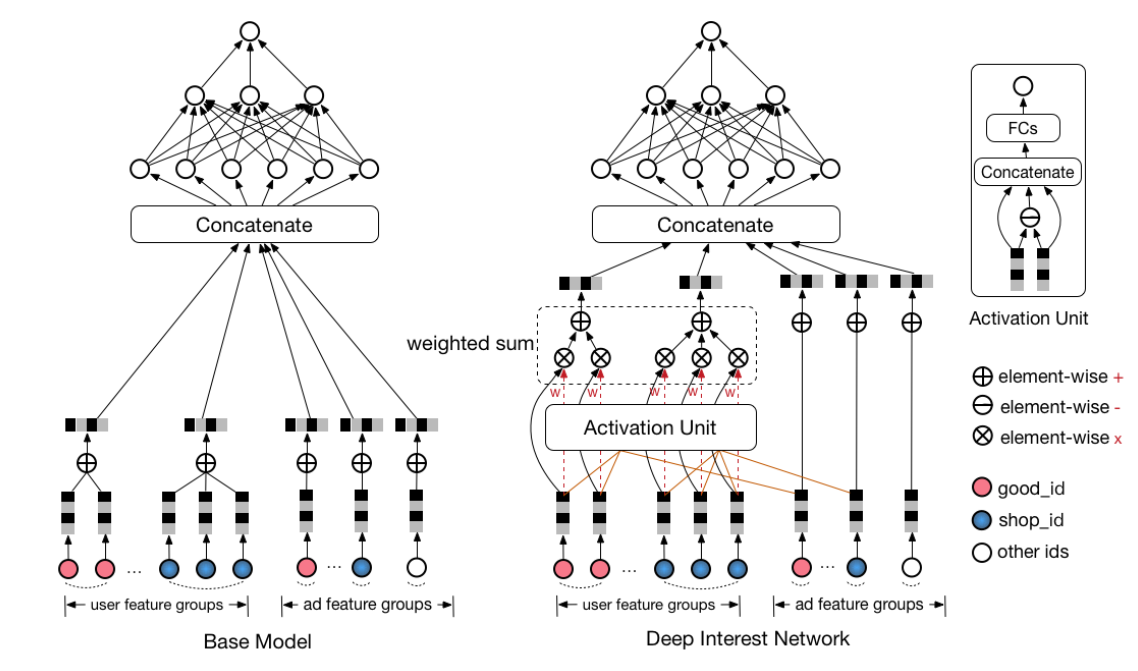
假设用户
u的分布式表达为 ,广告a的分布式表达为 。我们通过内积来衡量用户和广告的相关性: 。
。我们通过内积来衡量用户和广告的相关性: 。假设用户
u和广告a,b的相关性都很高,则 的值都会较大。那么位于 之间的点都会具有很高的相关性得分。这给用户和广告的分布式表达建模带来了硬约束。
的值都会较大。那么位于 之间的点都会具有很高的相关性得分。这给用户和广告的分布式表达建模带来了硬约束。我们可以通过增加向量空间的维数来满足约束条件,但是这会导致模型参数的巨大增长。
DIN通过让 称为 的函数来解决这个问题:
称为 的函数来解决这个问题:
其中:
- 是用户第
i个行为id(如商品id、店铺id)的embedding向量 - 是用户所有行为
id的embedding向量的加权和,权重 是用户第i个行为对候选广告a的attention score。
因此用户的
embedding向量根据不同的候选广告而有所不同,即:局部激活。而通过sum pooling融合历史行为来实现兴趣多样性。- 是用户第
PReLU激活函数是一种广泛应用的激活函数,其定义为:
其中 是一个很小的数。
激活函数类似
Leaky ReLU,它用于避免零梯度。研究表明:PReLU激活函数虽然能提升准确率,但是会有引入一些额外的过拟合风险。
其中:
和
 是训练期间基于
是训练期间基于 mini-batch统计得到的均值和方差, 为一个小的正数从而平滑结果。在推断期间我们使用
 和 :
和 :
其中 分别为第
 个
个 mini-batch统计得到的均值和方差, 为超参数(入0.99)。最后一个迭代步的
和 就是推断期间用到的均值和方差。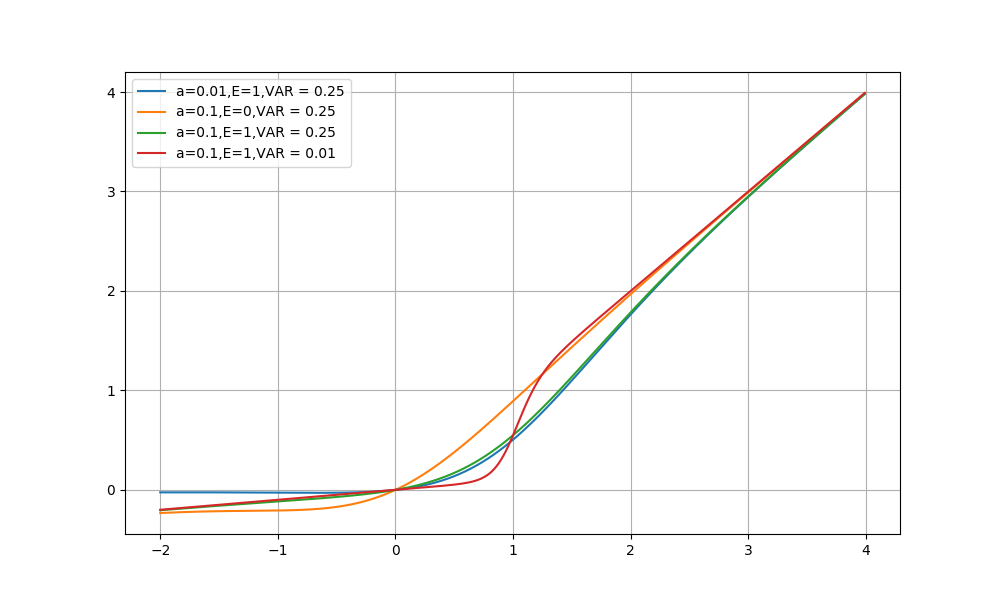
Dice可以视为一个soft rectifier,它带有两个通道 和 ,通过 控制这两个通道的流量。
,通过 控制这两个通道的流量。Dice的核心思想是:根据数据来自适应的调整整流点rectifier point,而不是像PReLU一样整流点在零点。
实验显示:当添加细粒度的、用户访问过的商品
id特征时,模型的性能(验证auc)在第一个epoch后迅速下降。这表明模型遇到严重过拟合。由于
web-scale级别的用户行为数据遵从长尾分布,即:大多数行为特征ID在训练样本中仅出现几次。这不可避免地将噪声引入到训练过程中,并加剧过拟合。缓解该问题地一种简单方式是:过滤掉低频地行为特征
ID。这可以视为一种人工正则化策略。这种过滤策略太过于粗糙,因此论文引入了一种自适应地正则化策略:根据行为特征
ID出现地频率对行为特征ID施加不同地正则化强度。定义
 为
为 size = b的mini batch样本集合, 表示训练集中行为特征ID = i出现的频次, 为正则化系数。
为正则化系数。定义参数更新方程为:
其中:
 表示特征
表示特征 ID = i对应的embedding向量,它也是embedding参数。用于指示:
中是否有特征 i非零的样本。
该正则化项惩罚了低频特征。
实践中发现:大多数
DNN网络都是基于以下两个部分来构建:- 采用
embedding技术将高维的原始稀疏特征转换为低维的embedding向量 - 将得到的
embedding向量馈入MLP/RNN/CNN等网络。
模型参数主要集中在
embedding部分,这部分需要在多台机器上分配;第二个部分可以在单台机器上处理。基于该思想,论文提出了支持多
GPU分布式训练的X-Deep Learning:XDL平台,该平台支持模型并行和数据并行,其目标是解决大规模稀疏输入特征、百亿级参数的工业级深度学习网络的挑战。XDL平台主要有三个组件:分布式
embedding层:它是一个模型并行模块,embedding层的参数分布在多个GPU上。embedding层作为一个预定义的网络单元来使用,提供前向、反向传播两种工作模式。本地后端
local backend模块:它是一个独立的模块,用于处理本地网络的训练。其优点是:
- 采用统一的数据交换接口和抽象,我们可以轻松的集成和切换不同的框架。
- 论文复用了开源的深度学习框架,如
tensorflow,mxnet,theano等。因此可以方便的跟进开源社区并利用最新的网络结构和算法的好处。
- 采用
DIN在XDL平台上训练,并采用了common feature技巧。由于
XDL平台的高性能和灵活性,训练速度加快了10倍,从而以更高的效率优化超参数。
评估指标:
AUC和Group AUC : GAUC。GAUC是 的推广,它是AUC的加权平均:
其中: 表示用户
i的所有样本对应的auc; 是用户
是用户 i的所有样本数。事实证明:
GAUC在展示广告中更具有指导意义。AUC考虑所有样本的排名,而事实上在线上预测时,对于给定用户我们只需要考虑候选广告的排名。GAUC对每个用户单独进行处理,先考虑每个用户的预测结果,再对所有用户进行加权。这可以消除用户bias的影响。如:模型倾向于对女性用户打高分(预测为正的概率较高),对男性用户打低分(预测为正的概率较低)。
- 如果采用
AUC则指标效果一般,因为男性正样本打分可能低于女性负样本。 - 如果采用
GAUC则指标效果较好,因为男性用户、女性用户各自的AUC都较高,加权之后的GAUC也较高。这和线上投放的方式一致。
- 如果采用
12.5.1 可视化
DIN模型中,稀疏ID特征被编码为embedding向量。这里随机选择9个类别(服装、运动鞋、箱包等),每个类别选择100种商品。这些商品的embedding向量通过t-SNE可视化如下图。图中具有相同形状的点对应于同一类别颜色和点击率预测值相对应。从图中可以清楚看到
DIN embedding的聚类特性。DIN基于attention单元来局部激活与候选广告相关的历史行为。下图展示了候选广告相关的注意力得分。可以看到:与候选广告高度相关的历史行为获得了很高的注意力得分。
12.5.2 自适应正则化
基准模型和
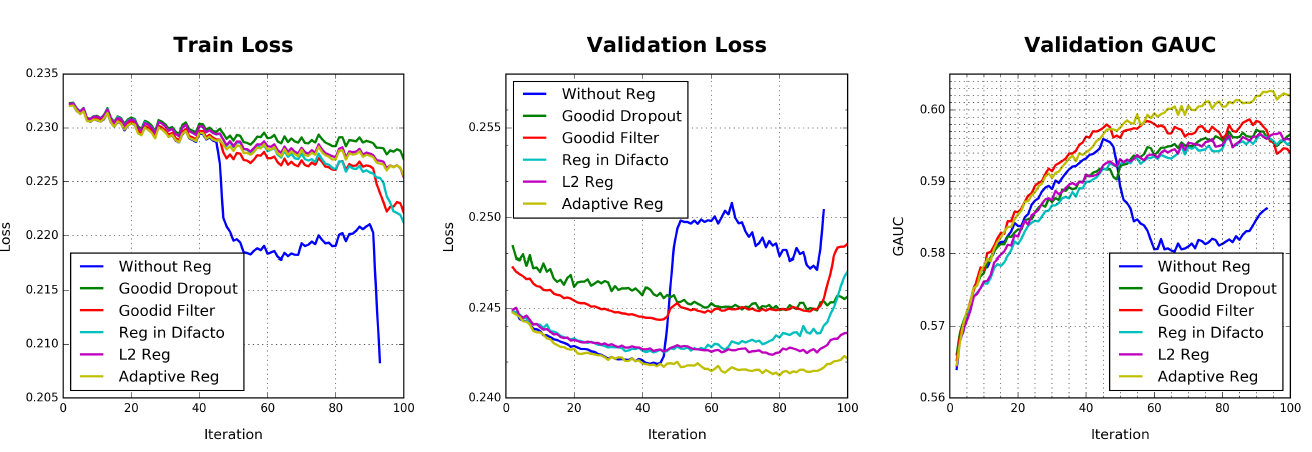
DIN模型都会遇到过拟合问题。下图展示了具有细粒度商品ID特征时的训练过程,图中清楚的看到过拟合问题(without reg)。论文比较了几种正则化技术:
dropout:在每个样本中,随机丢弃50%的历史行为商品ID。人工频率过滤:在每个样本中,人工去掉历史行为中的低频商品
ID,保留高频商品ID。正则化:采用正则化系数
 的 正则化。
的 正则化。DiFacto正则化:正则化系数 :自适应正则化::正则化系数
。
比较结果如下图所示:
- 不带任何正则化时(
without reg),模型发生严重过拟合。 - 带
dropout正则化会缓解过拟合,但是同时会导致收敛速度在第一个epoch变慢。 - 人工频率过滤正则化也会缓解过拟合,同时在第一个
epoch保持同样的收敛速度(和无任何正则化方法相比),但是最终模型性能比dropout效果更差。 DiFactro正则化对于用户历史行为中的高频商品设置更大惩罚。但是在我们的任务中,高频商品更能代表用户的兴趣,而低频商品代表噪声。因此这种形式的正则化效果效果甚至不如 正则化。- 自适应正则化方法在第一个
epoch之后几乎看不到过拟合,在第二个epoch验证集的loss和GAUC几乎已经收敛。这证明了自适应正则化方法的有效性。
12.5.3 模型对比
在淘宝线上展示广告系统中比较了不同的模型效果。
训练数据和测试数据采集自系统日志(曝光日志和点击日志)。论文收集了两周的样本作为训练集,下一天的样本作为测试集。
基准模型和
DIN模型的参数各自独立调优,并且报告各自最佳结果。结论:
使用自适应正则化的
DIN使用基准模型一半的迭代次数就可以获得基准模型最好的GAUC。最终
DIN模型相比基准模型获得了1.01%的绝对GAUC增益。采用
Dice激活函数之后,DIN模型提高了0.23%的绝对 增益。

