
- 2012年 和他的学生推出了
AlexNet。在当年的ImageNet图像分类竞赛中,AlexeNet以远超第二名的成绩夺冠,使得深度学习重回历史舞台,具有重大历史意义。
-
- 广义的卷积层:包含了卷积层、池化层、
ReLU、LRN层等。 - 广义全连接层:包含了全连接层、
ReLU、Dropout层等。
- 广义的卷积层:包含了卷积层、池化层、
网络结构如下表所示:
输入层会将
3@224x224的三维图片预处理变成3@227x227的三维图片。第二层广义卷积层、第四层广义卷积层、第五层广义卷积层都是分组卷积,仅采用本
GPU内的通道数据进行计算。第一层广义卷积层、第三层广义卷积层、第六层连接层、第七层连接层、第八层连接层执行的是全部通道数据的计算。
第二层广义卷积层的卷积、第三层广义卷积层的卷积、第四层广义卷积层的卷积、第五层广义卷积层的卷积均采用
same填充。其它层的卷积,以及所有的池化都是
valid填充(即:不填充 0 )。第六层广义连接层的卷积之后,会将
feature map展平为长度为 4096 的一维向量。
2.2 设计技巧
-
- 使用
ReLU激活函数。 - 使用
dropout、数据集增强 、重叠池化等防止过拟合的方法。 - 使用百万级的大数据集来训练。
- 使用
GPU训练,以及的LRN使用。 - 使用带动量的
mini batch随机梯度下降来训练。
- 使用
2.2.1 数据集增强
AlexNet中使用的数据集增强手段:随机裁剪、随机水平翻转:原始图片的尺寸为
256xx256,裁剪大小为224x224。每一个
epoch中,对同一张图片进行随机性的裁剪,然后随机性的水平翻转。理论上相当于扩充了数据集 倍。
倍。在预测阶段不是随机裁剪,而是固定裁剪图片四个角、一个中心位置,再加上水平翻转,一共获得 10 张图片。
用这10张图片的预测结果的均值作为原始图片的预测结果。
PCA降噪:对RGB空间做PCA变换来完成去噪功能。同时在特征值上放大一个随机性的因子倍数(单位1加上一个 的高斯绕动),从而保证图像的多样性。- 每一个
epoch重新生成一个随机因子。 - 该操作使得错误率下降
1%。
- 每一个
AlexNet的预测方法存在两个问题:- 裁剪窗口重叠,这会引起很多冗余的计算。
改进的思路是:
- 执行所有可能的裁剪方式,对所有裁剪后的图片进行预测。将所有预测结果取平均,即可得到原始测试图片的预测结果。
- 减少裁剪窗口重叠部分的冗余计算。
具体做法为:将全连接层用等效的卷积层替代,然后直接使用原始大小的测试图片进行预测。将输出的各位置处的概率值按每一类取平均(或者取最大),则得到原始测试图像的输出类别概率。
下图中:上半图为 的预测方法;下半图为改进的预测方法。
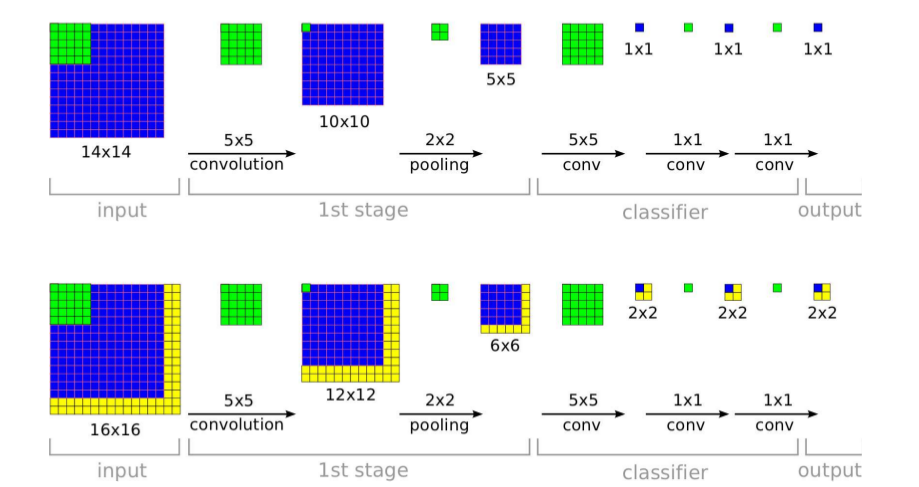
2.2.2 局部响应规范化
局部响应规范层
LRN:目地是为了进行一个横向抑制,使得不同的卷积核所获得的响应产生竞争。LRN层现在很少使用,因为效果不是很明显,而且增加了内存消耗和计算时间。- 在
AlexNet中,该策略贡献了1.2%的贡献率。
LRN的思想:输出通道 在位置 处的输出会受到相邻通道在相同位置输出的影响。
处的输出会受到相邻通道在相同位置输出的影响。其中:
 为输出通道 在位置 处的原始值, 为归一化之后的值。
为输出通道 在位置 处的原始值, 为归一化之后的值。 为影响第 通道的通道数量(分别从左侧、右侧
为影响第 通道的通道数量(分别从左侧、右侧  个通道考虑)。 为超参数。
个通道考虑)。 为超参数。一般考虑
 。
。
2.2.3 多GPU 训练
AlexNet使用两个GPU训练。网络结构图由上、下两部分组成:一个GPU运行图上方的通道数据,一个GPU运行图下方的通道数据,两个GPU只在特定的网络层通信。即:执行分组卷积。- 第二、四、五层卷积层的核只和同一个
GPU上的前一层的feature map相连。 - 第三层卷积层的核和前一层所有
GPU的feature map相连。 - 全连接层中的神经元和前一层中的所有神经元相连。
- 第二、四、五层卷积层的核只和同一个
2.2.4 重叠池化
一般的池化是不重叠的,池化区域的大小与步长相同。
Alexnet中,池化是可重叠的,即:步长小于池化区域的大小。重叠池化可以缓解过拟合,该策略贡献了
0.4%的错误率。为什么重叠池化会减少过拟合,很难用数学甚至直观上的观点来解答。一个稍微合理的解释是:重叠池化会带来更多的特征,这些特征很可能会有利于提高模型的泛化能力。
2.2.5 优化算法
AlexNet使用了带动量的mini-batch随机梯度下降法。标准的带动量的
mini-batch随机梯度下降法为:
而论文中,作者使用了修正:
- 其中
 , ,
, , 为学习率。
为学习率。
- 其中

