-
Universal Transformer是Transformer的推广 ,它是一个时间并行的递归自注意力序列模型,解决了上述两个问题。- 通过引入了递归,因此在内存充足的条件下,它是图灵完备的。
- 通过引入自适应处理时间
Adaptive Computation Time(ACT),它使得不同token的迭代时间步不同。
Universal Transformer结合了Transformer和RNN的优势:- 具有
Transformer计算并行性和全局接受域global receptive field的优点 - 也具有
Transformer不具备的递归归纳偏差recurrent inductive bias
- 具有
Universal Transformer总体计算流程如下图所示:- 和
Transformer相同,它使用自注意力机制来组合来自不同位置的信息。 - 和
Transformer不同,它在所有的时间步的所有位置上应用一个转换函数Transition Function。 - 和
Transformer不同,它的时间步不再是固定的,而是一个循环。循环的停止条件由动态停止dynamic halting技术决定,并且每个位置的停止时间可以不同。
图中:箭头表示计算的依赖关系, 表示第
 个时间步各位置的向量表达。其中 由输入
个时间步各位置的向量表达。其中 由输入 token的embedding来初始化。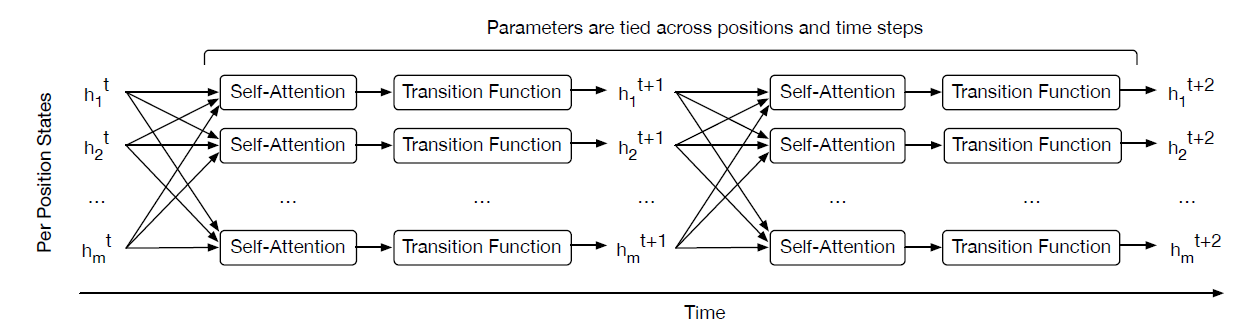
- 和
Universal Transformer基于BERT结构进化而来。Universal Transformer对encoder和decoder的每个token的表达都应用了循环操作,但是这种循环不是基于token的序列位置(横向),而是基于token的处理深度(纵向)。- 因此
Universal Transformer的计算限制不受序列长度的影响,而受网络深度的影响。 - 因此
Universal Transformer具有可变深度,这与Transformer、RNN等具有固定深度的模型完全不同。
- 因此
在每个时间步,对每个
token的表达并行的执行以下操作:在所有时间步的所有位置上应用同一个转换函数 。
有两种转换函数:全连接、深度可分离卷积。
与
Transformer相同,Universal Transformer也会引入残差连接、层归一化Layer Normalization、Dropout。
与
Transformer不同,Universal Transformer的position embedding在每个时间步都发生变化,而不仅仅只有起始时设置一次。设时间步 时,位置
 的
的 position embedding为 ,则有:
其中 表示向量的维度,
 为序列的长度。写成矩阵的形式有:
为序列的长度。写成矩阵的形式有:
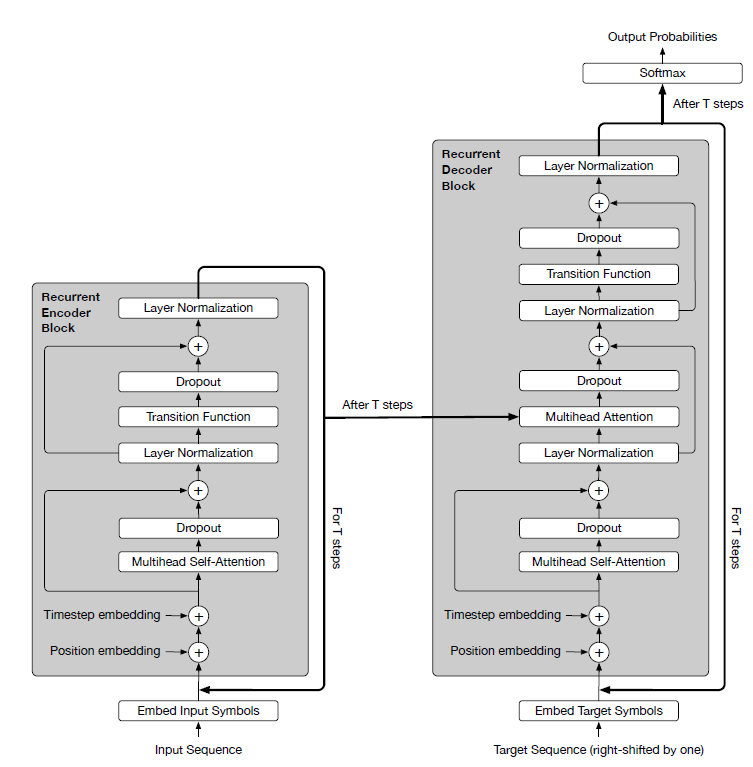
编码器
encoder:给定一个长度为 的输入token序列 :
:首先根据每个
token的 维embedding,得到一个初始输入矩阵 :
:其中 为
token 的一维
的一维 embedding。然后在时刻 ,根据
self attention机制和Transition Function来并行计算 。
。self attention机制:其中
 分别将
分别将 query, key, value映射成 维度, 用于调整
用于调整 concate的输出结果。整体步骤(其中
LN为Layer Normalize,Trans为Transition Function:- 计算 时刻的输入:
 。
。 - 计算
self attention(考虑残差连接和层归一化): 。 - 计算
Transition Function: 。
。
- 计算 时刻的输入:
解码器和编码器的结构基本相同,有以下不同的地方:
与
Transformer相同,Universal Transformer的解码器也采用的是masked self-attention机制。与
Transformer不同,Universal Transformer的解码器对编码器 步的输出 计算注意力,其中
计算注意力,其中 query来自解码器、key,value来自编码器。设解码器在 步的输出为
 ,则输出
,则输出 token为 的概率为:
其中 为输出的位置。
Universal Transformer的训练采用teacher-forcing策略。训练阶段:解码器的输入来自目标序列。由于采用 机制,因此每次迭代时序列右边界右移一个位置,表示下一个预测目标。
测试阶段:
- 首先由编码器重复执行多次,得到输入序列的编码 ;然后解码器重复执行多次,解码器每次执行会生成下一个
token。
- 首先由编码器重复执行多次,得到输入序列的编码
在文本处理任务中,文本中的某些单词相比较于文本中的其它单词可能更难以理解。对于这些难以理解的单词,可能需要执行更多的处理步骤。
Adaptive Computation Time(ACT)技术就是通过为每个token计算个性化的迭代时间步来解决这个问题。在
Universal Transformer中,ACT在每个循环为每个token计算一个停止概率。一旦该
token应该停止计算,则该token的状态直接向后传递,直到所有的token都停止计算,或者达到一个最大的迭代步阈值。
BABI Question-Answering数据集:包含20种不同的任务,每个任务都是根据一段文本来回答问题。该数据集的目标是:通过对每个故事中的事实fact进行某种类型的推理,从而衡量语言理解能力。(12/20)表示 20个任务中,失败任务(测试集错误率超过 5%)的数量。10K/1K表示训练集的大小。train single表示针对每个任务训练一个模型;train joint表示对所有任务共同训练一个模型。- 所有的模型都采用 10 轮不同初始化,并根据验证集选择最佳初始化对应的模型来输出。
针对
BABI任务的可视化分析表明:注意力分布开始时非常均匀。但是随后的步骤中,围绕每个答案所需的正确事实
fact,注意力分布逐渐变得更加清晰。通过动态暂停
ACT技术观察到:对于需要三个事实fact支持的问题,其平均思考时间高于只有两个事实fact支持的问题;对于需要两个事实fact支持的问题,其平均思考时间又高于只有一个事实fact支持的问题。- 平均思考时间:用一组测试样本每个
token的平均迭代时间步来衡量。 - 对于三个/两个/一个事实支持的问题,其平均思考时间分别为:
 、、
、、 。
。 - 这表明:模型根据问题所需的支持事实
fact的数量来调整迭代时间步。
- 平均思考时间:用一组测试样本每个
通过动态暂停
ACT技术观察到:对于需要一个事实fact支持的问题,其不同位置的思考时间更为均匀。对于需要两个/三个事实fact支持的问题,其不同位置的思考时间差距较大。尤其在三个事实支持的问题中,很多位置只迭代一到两步就停止,只有少数位置迭代更多步。这意味着:大多数位置与任务无关。
下图为某个三事实支持的问题对应的
token迭代时间步的分布。
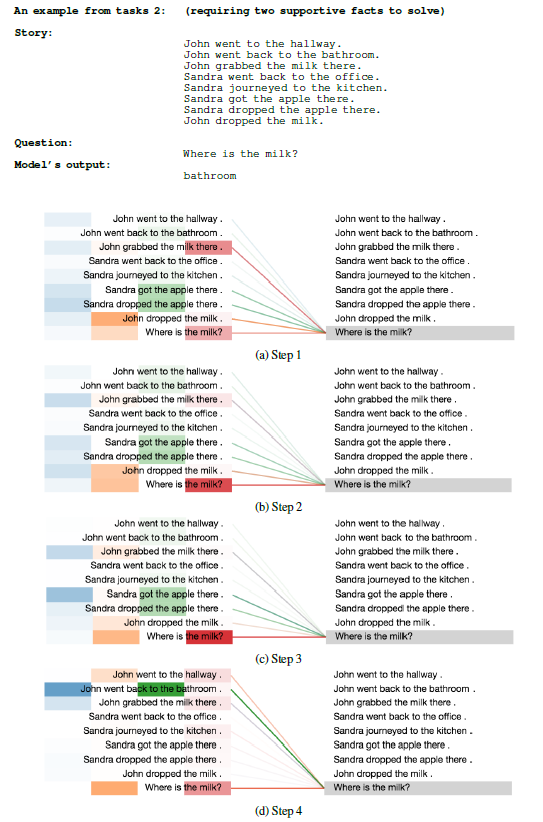
针对
BABI任务的可视化分析表明:Universal Transformer类似动态记忆网络dynamic memory network,它具有一个迭代注意力的过程。Universal Transformer模型根据前一个迭代的结果(也称作记忆)来调节其注意力分布。下图为注意力权重在不同时间步上的可视化,左侧不同的颜色条表示不同
head的注意力权重(一共4个头)。一个事实
fact支持的问题: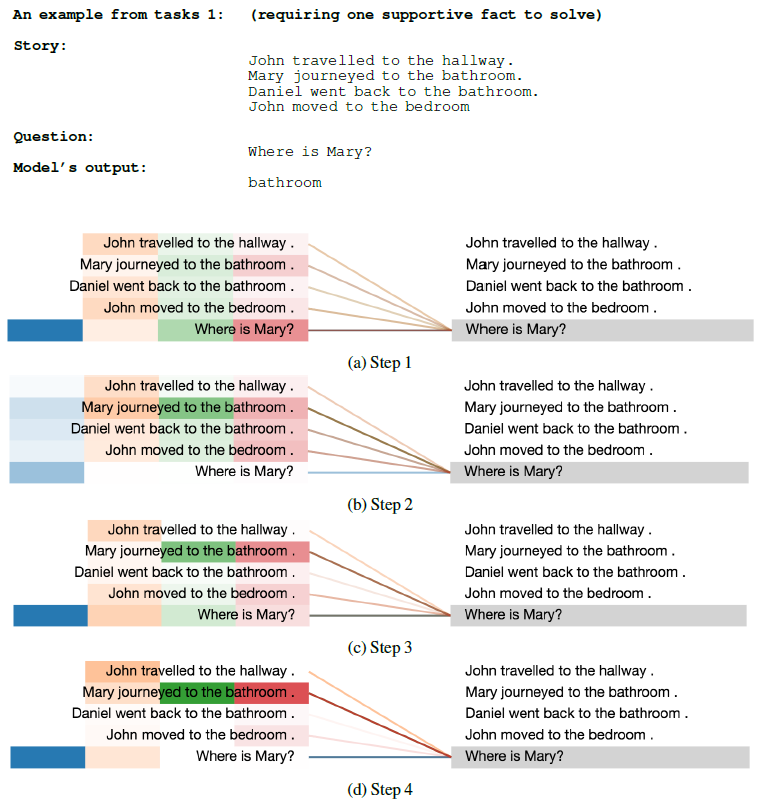
两个事实
fact支持的问题: