
- 对于线性不可分训练数据,线性支持向量机不再适用,但可以想办法将它扩展到线性不可分问题。
-
假设训练数据集不是线性可分的,这意味着某些样本点 不满足函数间隔大于等于 1 的约束条件。
对每个样本点
 引进一个松弛变量 ,使得函数间隔加上松弛变量大于等于 1。
引进一个松弛变量 ,使得函数间隔加上松弛变量大于等于 1。即约束条件变成了:
 。
。对每个松弛变量 ,支付一个代价
 。目标函数由原来的 变成:
。目标函数由原来的 变成:
这里 称作惩罚参数,一般由应用问题决定。
 值大时,对误分类的惩罚增大,此时误分类点凸显的更重要
值大时,对误分类的惩罚增大,此时误分类点凸显的更重要- 值较大时,对误分类的惩罚增加,此时误分类点比较重要。
- 值较小时,对误分类的惩罚减小,此时误分类点相对不重要。
相对于硬间隔最大化, 称为软间隔最大化。
于是线性不可分的线性支持向量机的学习问题变成了凸二次规划问题:

这称为线性支持向量机的原始问题。
因为这是个凸二次规划问题,因此解存在。
可以证明 的解是唯一的;
 的解不是唯一的, 的解存在于一个区间。
的解不是唯一的, 的解存在于一个区间。
对于给定的线性不可分的训练集数据,通过求解软间隔最大化问题得到的分离超平面为:
 ,
,以及相应的分类决策函数: ,称之为线性支持向量机。
- 线性支持向量机包含线性可分支持向量机。
- 现实应用中训练数据集往往是线性不可分的,线性支持向量机具有更广泛的适用性。
定义拉格朗日函数为:

原始问题是拉格朗日函数的极小极大问题;对偶问题是拉格朗日函数的极大极小问题。
再求极大问题:将上面三个等式代入拉格朗日函数:
于是得到对偶问题:

根据 条件:
则有:
 。
。若存在 的某个分量
 ,则有:。
,则有:。- 根据
 ,有 。
,有 。 - 考虑
 ,则有:
,则有:
- 根据
分离超平面为:
 。
。分类决策函数为: 。
线性支持向量机对偶算法:
输入:训练数据集
 ,其中
,其中 输出:
- 分离超平面
- 分类决策函数
算法步骤:
选择惩罚参数
 ,构造并且求解约束最优化问题:
,构造并且求解约束最优化问题:求得最优解
 。
。计算 : 。
-
可能存在多个符合条件的
 。这是由于原始问题中,对 的解不唯一。所以
。这是由于原始问题中,对 的解不唯一。所以实际计算时可以取在所有符合条件的样本点上的平均值。
由此得到分离超平面:
,以及分类决策函数: 。
在线性不可分的情况下,对偶问题的解
中,对应于 的样本点 的实例点 称作支持向量,它是软间隔的支持向量。
定义取正函数为:

定义合页损失函数为: ,其中
 为样本的标签值, 为样本的模型预测值。
为样本的标签值, 为样本的模型预测值。则线性支持向量机就是最小化目标函数:

合页损失函数的物理意义:
- 当样本点 被正确分类且函数间隔(确信度)
 大于 1 时,损失为0
大于 1 时,损失为0 - 当样本点 被正确分类且函数间隔(确信度) 小于等于 1 时损失为
- 当样本点 未被正确分类时损失为
- 当样本点 被正确分类且函数间隔(确信度)
可以证明:线性支持向量机原始最优化问题等价于最优化问题:

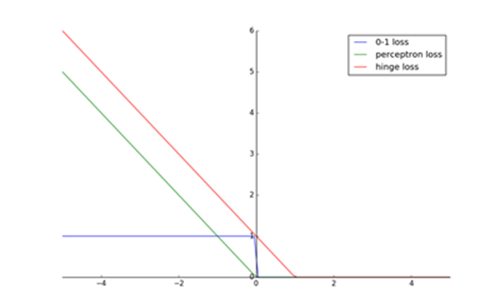
合页损失函数图形如下:
感知机的损失函数为 ,相比之下合页损失函数不仅要分类正确,而且要确信度足够高(确信度为1)时,损失才是0。即合页损失函数对学习有更高的要求。
0-1损失函数通常是二分类问题的真正的损失函数,合页损失函数是0-1损失函数的上界。
- 因为0-1损失函数不是连续可导的,因此直接应用于优化问题中比较困难。
- 通常都是用0-1损失函数的上界函数构成目标函数,这时的上界损失函数又称为代理损失函数。
-
- 合页损失函数部分不可导。这可以通过 来解决。
- 无法得出支持向量和非支持向量的区别。

