
-
:一个
array-like类型的实例,它不一定是数组,可以为list、tuple、list of tuple、list of list、tuple of list、tuple of tuple等等。dtype:数组的值类型,默认为float。你可以指定Python的标准数值类型,也可以使用numpy的数值类型如:numpy.int32或者numpy.float64等等。order:指定存储多维数据的方式。- 可以为
'C',表示按行优先存储(C风格); - 可以为
'F',表示按列优先存储(Fortran风格)。 - 对于
**_like()函数,order可以为:'C','F','A'(表示结果的order与a相同),'K'(表示结果的order与a尽可能相似)
- 可以为
subok:bool值。如果为True则:如果a为ndarray的子类(如matrix类),则结果类型与a类型相同。如果为False则:结果类型始终为ndarray。默认为True。
2.1 创建全1或者全0
np.empty(shape[,dtype,order]):返回一个新的ndarray,指定了shape和dtype,但是没有初始化元素。因此其内容是随机的。np.empty_like(a[,dtype,order,subok]):返回一个新的ndarray,shape与a相同,但是没有初始化元素。因此其内容是随机的。
np.ones(shape[, dtype, order]):返回一个新的ndarray,指定了shape和type,每个元素初始化为1.np.ones_like(a[, dtype, order, subok]):返回一个新的ndarray,shape与a相同,每个元素初始化为1。

-
np.zeros_like(a[, dtype, order, subok]):返回一个新的ndarray,shape与a(另一个数组)相同,每个元素初始化为0。
np.full(shape, fill_value[, dtype, order]):返回一个新的ndarray,指定了shape和type,每个元素初始化为fill_value。np.full_like(a, fill_value[, dtype, order, subok]):返回一个新的ndarray,shape与a相同,每个元素初始化为fill_value。

2.2 从现有数据创建
np.array(object[, dtype, copy, order, subok, ndmin]):从object创建。object可以是一个ndarray,也可以是一个array_like的对象,也可以是一个含有返回一个序列或者ndarray的__array__方法的对象,或者一个序列。copy:默认为True,表示拷贝对象order可以为'C'、'F'、'A'。默认为'A'。subok默认为Falsendmin:指定结果ndarray最少有多少个维度。
np.asanyarray(a[, dtype, order]):将a转换成ndarray。np.ascontiguousarray(a[, dtype]):返回C风格的连续ndarraynp.asmatrix(data[, dtype]):返回matrixnp.copy(a[, order]):返回ndarray的一份深拷贝np.fromfile(file[, dtype, count, sep]):从二进制文件或者文本文件中读取数据返回ndarray。sep:当从文本文件中读取时,数值之间的分隔字符串,如果sep是空字符串则表示文件应该作为二进制文件读取;如果sep为" "表示可以匹配0个或者多个空白字符。np.fromfunction(function, shape, **kwargs):返回一个ndarray。从函数中获取每一个坐标点的数据。假设shape的维度为N,那么function带有N个参数,fn(x1,x2,...x_N),其返回值就是该坐标点的值。np.fromiter(iterable, dtype[, count]):从可迭代对象中迭代获取数据创建一维ndarray。np.fromstring(string[, dtype, count, sep]):从字符串或者raw binary中创建一维ndarray。如果sep为空字符串则string将按照二进制数据解释(即每个字符作为ASCII码值对待)。创建的数组有自己的数据存储区。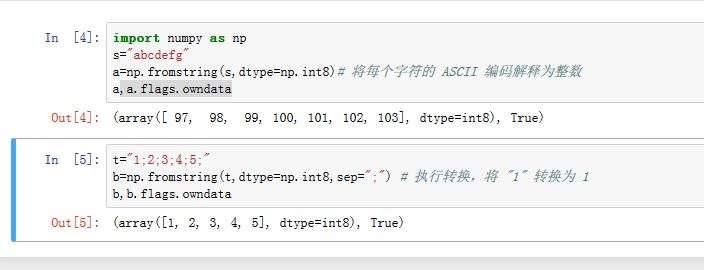
np.loadtxt(fname[, dtype, comments, delimiter, ...]):从文本文件中加载数据创建ndarray,要求文本文件每一行都有相同数量的数值。comments:指示注释行的起始字符,可以为单个字符或者字符列表(默认为#)。delimiter:指定数值之间的分隔字符串,默认为空白符。converters:将指定列号(0,1,2…)的列数据执行转换,是一个map,如{0:func1}表示对第一列数据执行func1(val_0)。skiprows:指定跳过开头的多少行。usecols:指定读取那些列(0表示第一列)。
2.3 从数值区间创建
np.arange([start,] stop[, step,][, dtype]):返回均匀间隔的值组成的一维ndarray。区间是半闭半开的[start,stop),其采样行为类似Python的range函数。start为开始点,stop为终止点,step为步长,默认为1。这几个数可以为整数可以为浮点数。注意如果step为浮点数,则结果可能有误差,因为浮点数相等比较不准确。np.linspace(start, stop[, num, endpoint, ...]):返回num个均匀采样的数值组成的一维ndarray(默认为50)。区间是闭区间[start,stop]。endpoint为布尔值,如果为真则表示stop是最后采样的值(默认为True),否则结果不包含stop。retstep如果为True则返回结果包含采样步长step,默认为True。np.logspace(start, stop[, num, endpoint, base, ...]):返回对数级别上均匀采样的数值组成的一维ndarray。采样点开始于base^start,结束于base^stop。base为对数的基,默认为 10。- 它没有
retstep关键字参数
- 它没有

