
-
axis:指定沿着那个轴排序。如果为0/'index',则对沿着0轴,对行label排序;如果为1/'columns',则沿着 1轴对列label排序。level:一个整数、label、整数列表、label list或者None。对于多级索引,它指定在哪一级上排序。ascending:一个布尔值,如果为True,则升序排序;如果是False,则降序排序。inplace:一个布尔值,如果为True,则原地修改。如果为False,则返回排好序的新对象kind:一个字符串,指定排序算法。可以为'quicksort'/'mergesort'/'heapsort'。注意只有归并排序是稳定排序的na_position:一个字符串,值为'first'/'last',指示:将NaN排在最开始还是最末尾。sort_remaining:一个布尔值。如果为True,则当多级索引排序中,指定level的索引排序完毕后,对剩下level的索引也排序。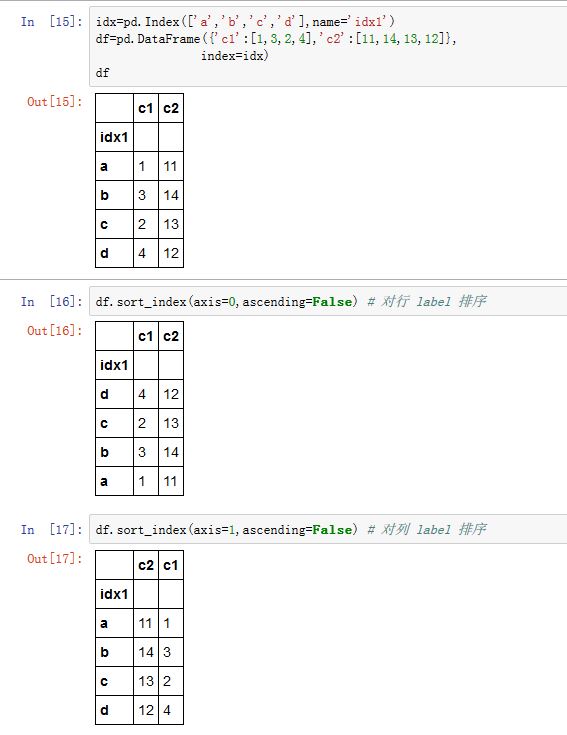
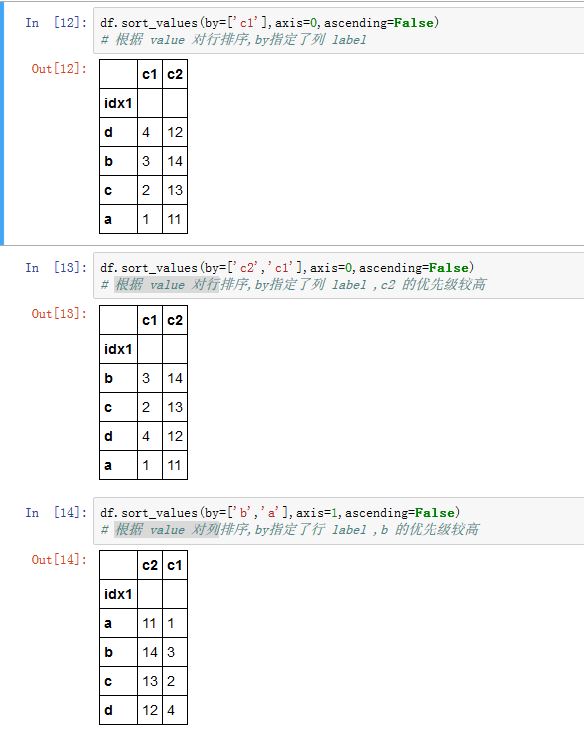
.sort_values()方法的作用是根据元素值进行排序。by:一个字符串或者字符串的列表,指定希望对那些label对应的列或者行的元素进行排序。对于DataFrame,必须指定该参数。而Series不能指定该参数。如果是一个字符串列表,则排在前面的
label的优先级较高。
ascending:一个布尔值,如果为True,则升序排序;如果是False,则降序排序。inplace:一个布尔值,如果为True,则原地修改。如果为False,则返回排好序的新对象na_position:一个字符串,值为'first'/'last',指示:将NaN排在最开始还是最末尾。
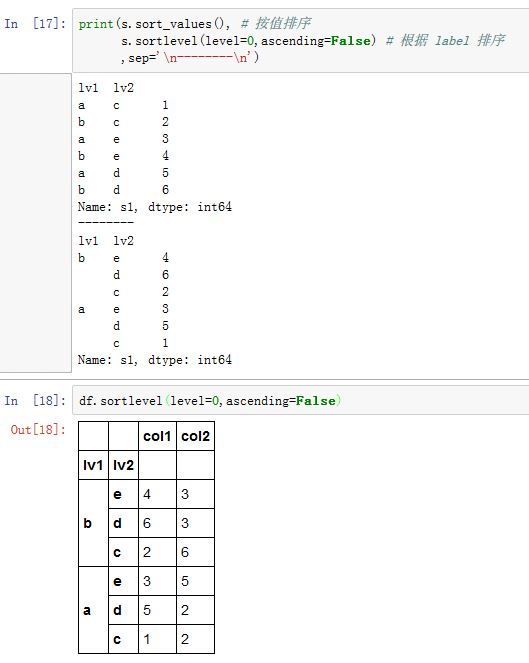
DataFrame/Series.sortlevel(level=0, axis=0, ascending=True,inplace=False, sort_remaining=True):根据单个level中的label对数据进行排列(稳定的)axis:指定沿着那个轴排序。如果为0/'index',则沿着0轴排序 ;如果为1/'columns',则沿着 1轴排序level:一个整数,指定多级索引的levelascending:一个布尔值,如果为True,则升序排序;如果是False,则降序排序。inplace:一个布尔值,如果为True,则原地修改。如果为False,则返回排好序的新对象sort_remaining:一个布尔值。如果为True,则当多级索引排序中,指定level的索引排序完毕后,对剩下level的索引也排序。
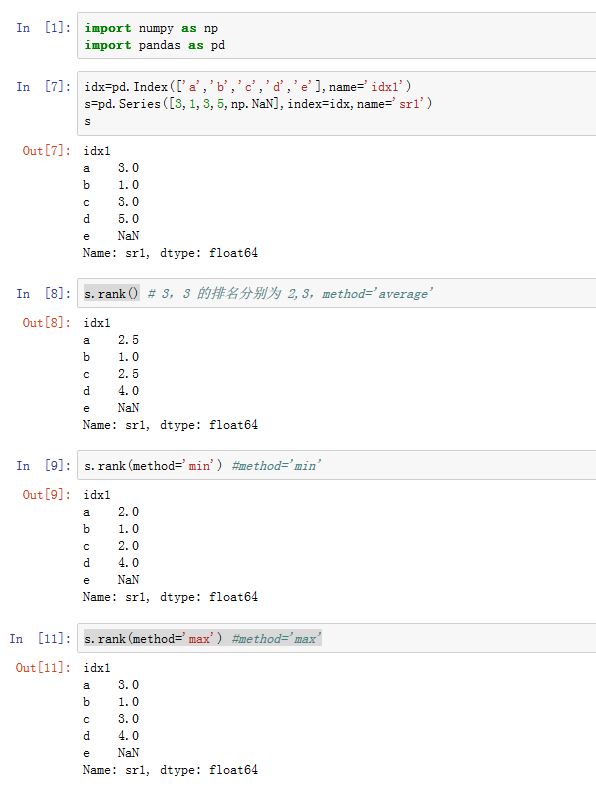
.rank()方法的作用是在指定轴上计算各数值的排,其中相同数值的排名是相同的。method:一个字符串,指定相同的一组数值的排名。假设数值v一共有N个。现在轮到对v排序,设当前可用的排名为k。'average':为各个等值平均分配排名,这N个数的排名都是'min':使用可用的最小的排名,这N个数的排名都是k'max':使用可用的最大的排名,这N各数的排名都是k+N-1'first:根据元素数据中出现的顺序依次分配排名,即按照它们出现的顺序,其排名分别为k,k+1,...k+N-1'dense:类似于'min',但是排名并不会跳跃。即比v大的下一个数值排名为k+1,而不是k+N
numeric_only:一个布尔值。如果为True,则只对float/int/bool数据排名。仅对DataFrame有效na_option:一个字符串,指定对NaN的处理。可以为:'keep':保留NaN在原位置'top':如果升序,则NaN安排最大的排名'bottom':如果升序,则NaN安排最小的排名
:一个布尔值。如果为
True,则计算数据的百分位数,而不是排名。

2. 排序
本文档使用 BookStack 构建

