
-
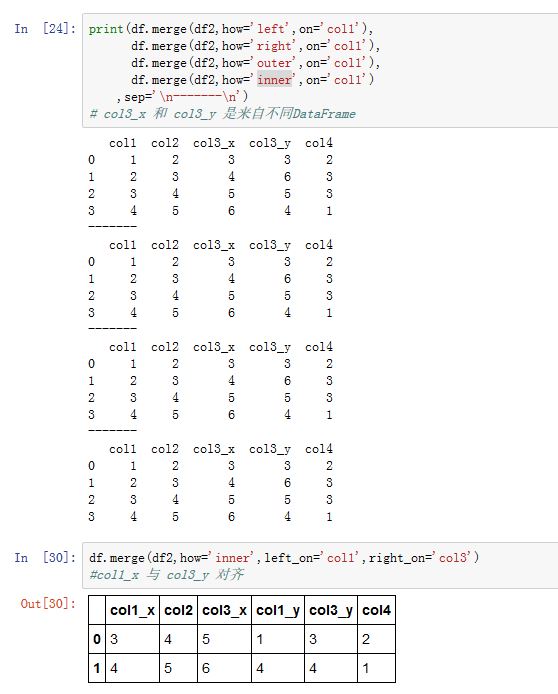
right:另一个DataFrame对象how:指定连接类型。可以为:'left':左连接。只使用左边DataFrame的连接键'right':右连接。只使用右边DataFrame的连接键'outer':外连接。使用两个DataFrame的连接键的并集'inner':内连接。使用两个DataFrame的连接键的交集
on:一个label或者label list。它指定用作连接键的列的label。并且必须在两个DataFrame中这些label都存在。如果它为None,则默认使用两个DataFrame的列label的交集。你可以通过left_on/right_on分别指定两侧DataFrame对齐的连接键。left_on:一个label或者label list。指定左边DataFrame用作连接键的列,参考onright_on:一个label或者label list。指定右边DataFrame用作连接键的列,参考onleft_index:一个布尔值。如果为True,则使用左边的DataFrame的行的index value来作为连接键来合并right_index:一个布尔值。如果为True,则使用右边的DataFrame的行的index value来作为连接键来合并sort:一个布尔值。如果为True,则在结果中,对合并采用的连接键进行排序suffixes:一个二元序列。对于结果中同名的列,它会添加前缀来指示它们来自哪个DataFramecopy:一个布尔值。如果为True,则拷贝基础数据。否则不拷贝数据indicator:一个字符串或者布尔值。- 如果为
True,则结果中多了一列称作_merge,该列给出了每一行来自于那个DataFrame
- 如果为
说明:
- 如果合并的序列来自于行的
index value,则使用left_index或者right_index参数。如果是使用了left_index=True,则必须使用right_index=True,或者指定。此时right_on为第二个DataFrame的行label。此时所有对键的操作都针对index label,而不再是column label。 - 如果不显示指定连接的键,则默认使用两个
DataFrame的column label的交集中的第一个label。 - 如果根据列来连接,则结果的
index label是RangeIndex(连续整数)。如果根据行label value连接,则结果的index label/column label来自两个DataFrame - 对于层次化索引的数据,你必须以列表的形式指明用作合并键的多个列。
如果所有的连接键来自于某列值,则可以使用
DataFrame.join()函数。它是.merge()的简化版。other:一个DataFrame,或者一个Series(要求它的name非空),或者一个DataFrame序列。Series的name作用等同DataFrame的column labelon:指定以调用者的那个column对应的列为键。how:参考merge的howlsuffic/rsuffix:参考merge的suffixes。如果结果中有重名的列,则必须指定它们之一。sort:一个布尔值。如果为True,则在结果中,对合并采用的连接键进行排序
如果是
Series,则连接键为Series的index value。此外,DataFrame默认使用index value(这与merge()不同)。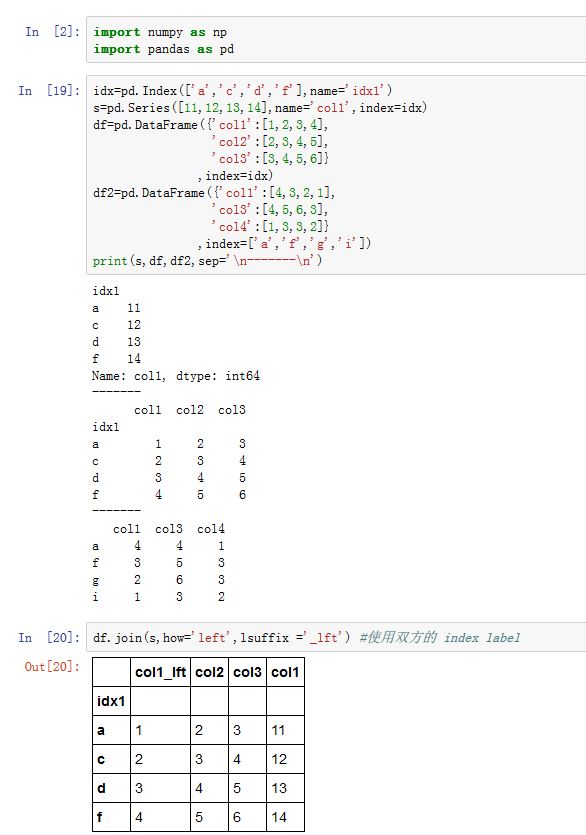
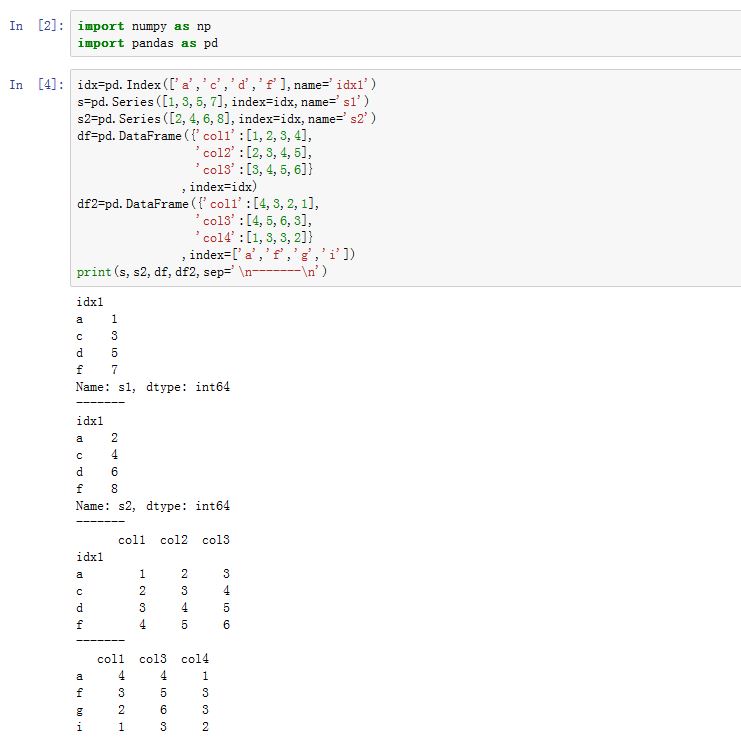
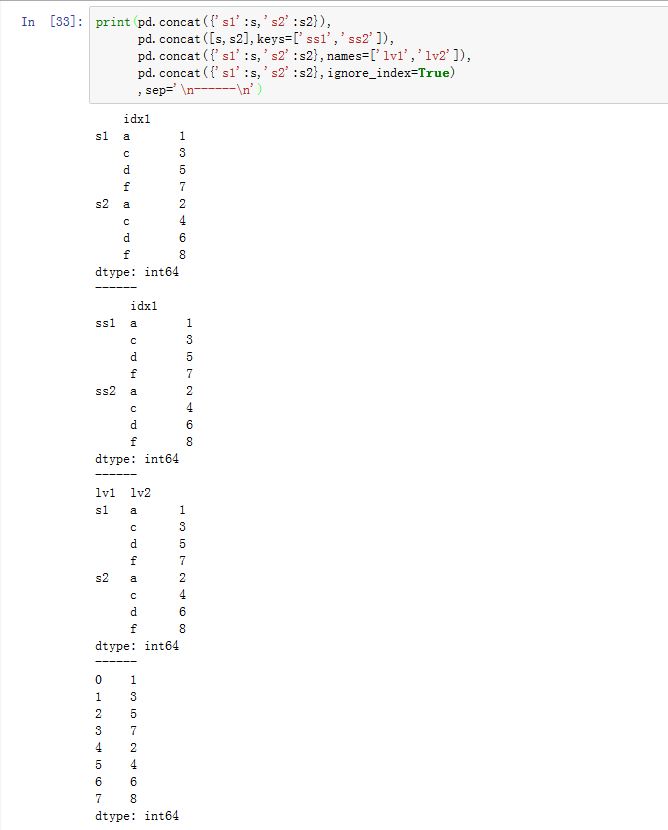
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False, copy=True)函数:它将多个DataFrame/Series对象拼接起来。objs:一个序列,序列元素为Series/DataFrame/Panel等。你也可以传入一个字典,此时字典的键将作为keys参数。axis:指定拼接沿着哪个轴。可以为0/'index'/,表示沿着 0 轴拼接。可以为1/'columns',表示沿着 1轴拼接。join:可以为'inner'/'outer',指定如何处理其他轴上的索引。join_axes:一个Index对象的列表。你可以指定拼接结果中,其他轴上的索引而不是交集或者并集(join参数使用时,其他轴的索引是计算得出的)。verify_integrity:一个布尔值。如果为,则检查新连接的轴上是否有重复索引,如果有则抛出异常。levels:一个序列。与keys配合使用,指定多级索引各级别上的索引。如果为空,则从keys参数中推断。(推荐为空)ignore_index:一个布尔值。如果为True,则不使用拼接轴上的index value,代替以RangeIndex,取值为0,1,...copy:一个布尔值。如果为True,则拷贝数据。
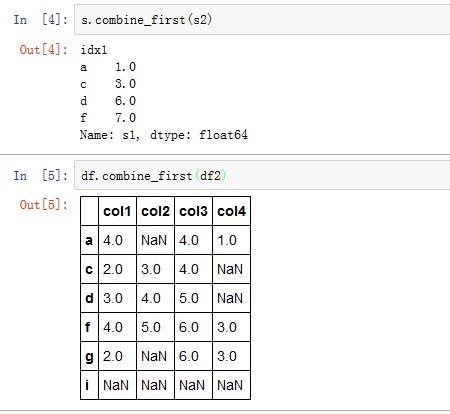
Series/DataFrame.combine_first()也是一种合并方式。它用参数对象中的数据给调用者打补丁。other:Series中必须为另一个Series,DataFrame中必须为另一个DataFrame
结果的
index/columns是两个的并集。结果中每个元素值这样产生:- 如果调用者不是
NaN,则选择调用者的值 - 如果调用者是
NaN,则选择参数的值(此时无论参数的值是否NaN)
Series/DataFrame.combine()也是一种合并。other:Series中必须为另一个Series,DataFrame中必须为另一个DataFramefunc:一个函数,该函数拥有两个位置参数。第一个参数来自于调用者,第二个参数来自于other。- 对于
Series,两个参数都是标量值,对应它们对齐后的元素值。返回值就是结果对应位置处的值。 - 对于
DataFrame,这两个参数都是Series,即对应的列。
- 对于
fill_value:一个标量 。在合并之前先用它来填充NaN。overwrite:如果为True,则原地修改调用者。如果为False,则返回一个新建的对象。
对于
Series,结果的index是两个的并集。结果中每个元素值这样产生:- 将两个
Series在同一个index的两个标量值分别传给func func的返回值就是结果Series在该index处的值
对于
DataFrame,结果的index/columns是两个的并集。结果中每列这样产生:func的返回值就是结果DataFrame在该column label列的值
2. 合并数据
本文档使用 BookStack 构建

