
-
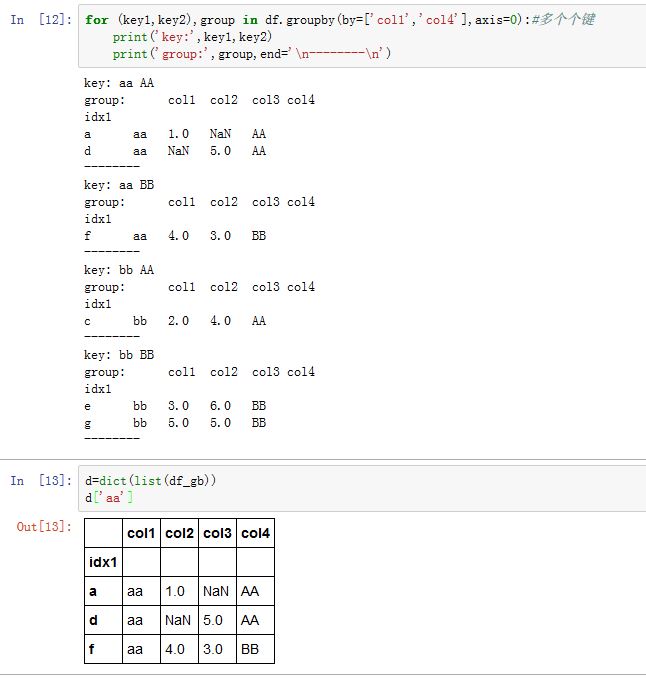
- 如果有多重键,则元组的第一个元素将是由键组成的元组。
dict(list(GroupBy_obj))将生产一个字典,方便引用
GroupBy.groups属性返回一个字典:{group name->group labels}GroupBy.indices属性返回一个字典:{group name->group indices}
-
GroupBy.count():计算各分组的非NaN的数量GroupBy.cumcount([ascending]):计算累积分组数量GroupBy.first():计算每个分组的第一个非NaN值GroupBy.head([n]):返回每个分组的前n个值GroupBy.max():计算每个分组的最大值- :计算每个分组的均值
GroupBy.median():计算每个分组的中位数GroupBy.min():计算每个分组的最小值GroupBy.nth(n[, dropna]):计算每个分组第n行数据。 如果n是个整数列表,则也返回一个列表。GroupBy.ohlc():计算每个分组的开始、最高、最低、结束值GroupBy.prod():计算每个分组的乘GroupBy.size():计算每个分组的大小(包含了NaN)GroupBy.sem([ddof]):计算每个分组的sem(与均值的绝对误差之和)GroupBy.std([ddof]):计算每个分组的标准差GroupBy.sum():计算每个分组的和GroupBy.tail([n]):返回每个分组的尾部n个值
另外
SeriesGroupBy/DataFrameGroupBy也支持的统计类方法以及其他方法: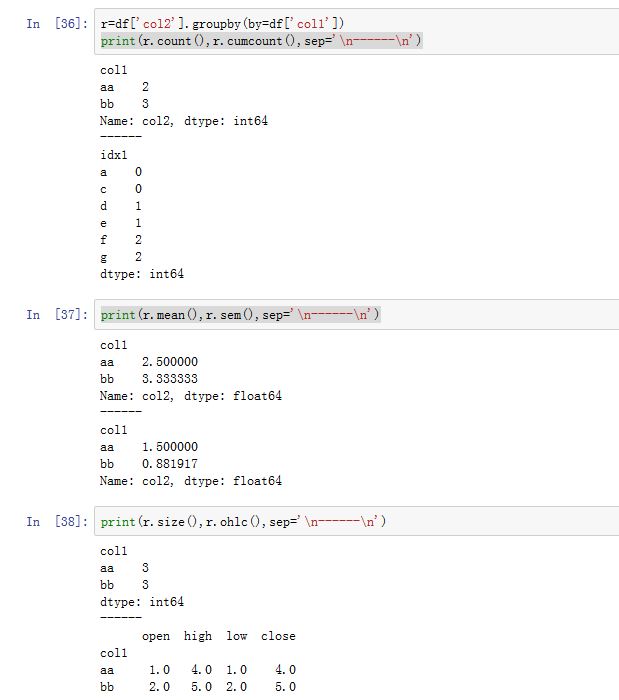
-
- 注意:自定义聚合函数会慢得多。这是因为在构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)
- 你可以将前面介绍的
GroupBy的统计函数名以字符串的形式传入。 - 如果你传入了一组函数或者函数名,则得到的结果中,相应的列就用对应的函数名命名。如果你希望提供一个自己的名字,则使用
(name,function)元组的序列。其中name用作结果列的列名。 - 如果你希望对不同的列采用不同的聚合函数,则向
agg()传入一个字典。字典的键就是列名,值就是你希望对该列采用的函数。

.get_group(key)可以获取分组键对应的数据。key:不同的分组就是依靠它来区分的
GroupBy类定义了__getattr__()方法,当获取GroupBy中未定义的属性时:- 如果属性名是源数据对象的某列的名称则,相当于
GroupBy[name],即获取针对该列的GroupBy对象
- 如果属性名是源数据对象的某列的名称则,相当于
2. GroupBy对象
本文档使用 BookStack 构建

