
- 在中有多种不同的朴素贝叶斯分类器。他们的区别就在于它们假设了不同的 分布 。
-

其中: 为第
 个特征的条件概率分布的均值, 为第 个特征的条件概率分布的方差。
个特征的条件概率分布的均值, 为第 个特征的条件概率分布的方差。 GaussianNB的原型为:模型属性:
class_prior_:一个数组,形状为(n_classes,),是每个类别的概率 。class_count_:一个数组,形状为(n_classes,),是每个类别包含的训练样本数量。theta_:一个数组,形状为(n_classes,n_features),是每个类别上,每个特征的均值。sigma_:一个数组,形状为(n_classes,n_features),是每个类别上,每个特征的标准差。
模型方法:
fit(X, y[, sample_weight]):训练模型。partial_fit(X, y[, classes, sample_weight]):分批训练模型。该方法主要用于大规模数据集的训练。此时可以将大数据集划分成若干个小数据集,然后在这些小数据集上连续调用
partial_fit方法来训练模型。predict_proba(X):返回一个数组,数组的元素依次是X预测为各个类别的概率值 。score(X, y[, sample_weight]):返回模型的预测性能得分。
多项式贝叶斯分类器
MultinomialNB:它假设特征的条件概率分布满足多项式分布:其中:
 ,表示属于类别 的样本的数量。
,表示属于类别 的样本的数量。 ,表示属于类别 且第 个特征取值为 的样本的数量。
,表示属于类别 且第 个特征取值为 的样本的数量。
MultinomialNB的原型为:alpha:一个浮点数,指定 值。
值。fit_prior:一个布尔值。- 如果为
True,则不去学习 ,替代以均匀分布。 - 如果为
False,则去学习 。
。
- 如果为
class_prior:一个数组。它指定了每个分类的先验概率 。如果指定了该参数,则每个分类的先验概率不再从数据集中学得
模型属性:
class_log_prior_:一个数组对象,形状为(n_classes,)。给出了每个类别的调整后的的经验概率分布的对数值。class_count_:一个数组,形状为(n_classes,),是每个类别包含的训练样本数量。feature_count_:一个数组,形状为(n_classes, n_features)。训练过程中,每个类别每个特征遇到的样本数。
下面的示例给出了不同的
值对模型预测能力的影响。 运行结果如下。为了便于观察将
x轴设置为对数坐标。可以看到随着 之后,随着 的增长,预测准确率在下降。这是因为,当 时,
 。即对任何类型的特征、该类型特征的任意取值,出现的概率都是 。它完全忽略了各个特征之间的差别,也忽略了每个特征内部的分布。
。即对任何类型的特征、该类型特征的任意取值,出现的概率都是 。它完全忽略了各个特征之间的差别,也忽略了每个特征内部的分布。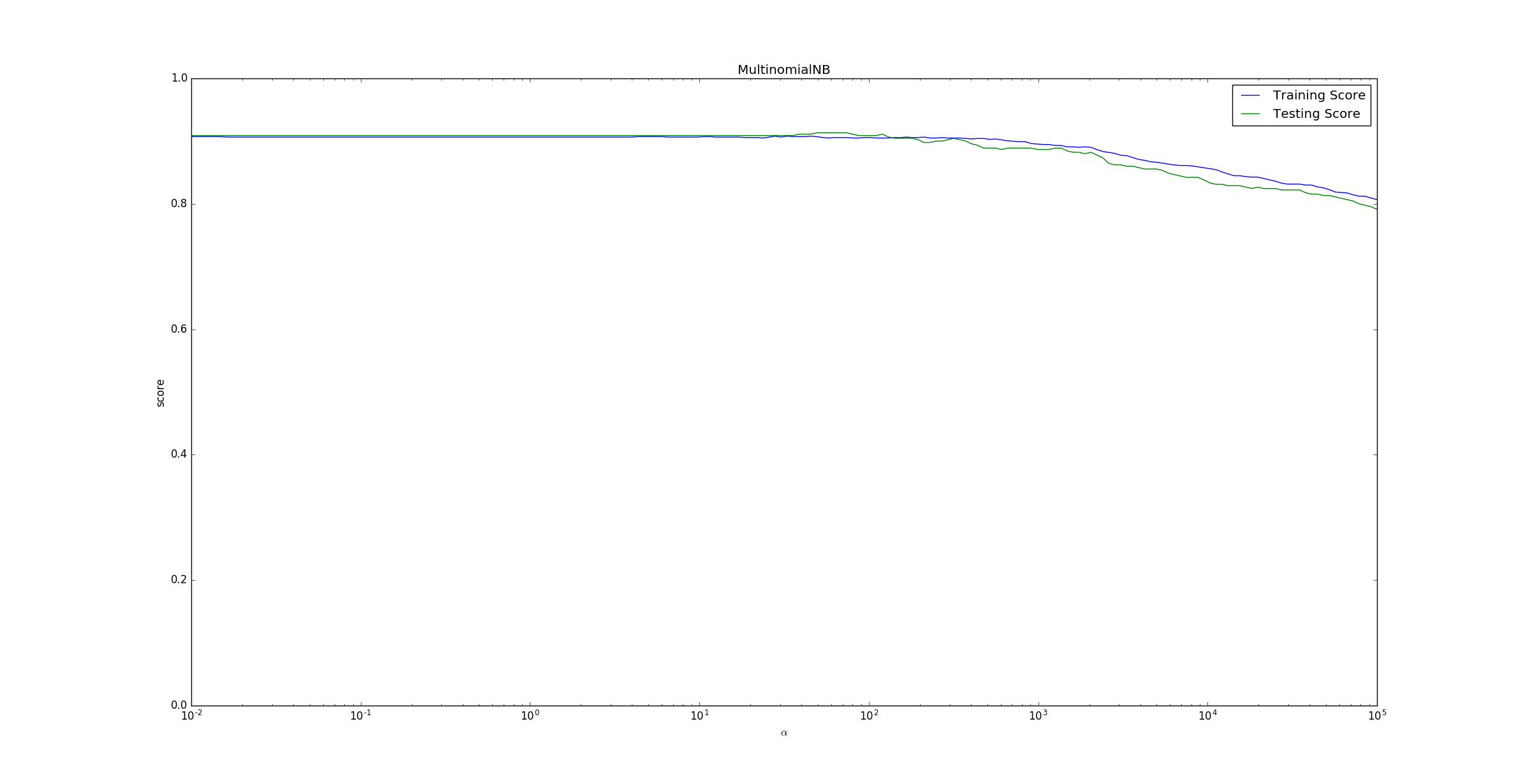
伯努利贝叶斯分类器
BernoulliNB:它假设特征的条件概率分布满足二项分布:其中
 ,且要求特征的取值为 。
,且要求特征的取值为 。BernoulliNB的原型为:binarize:一个浮点数或者None。如果为
None,那么会假定原始数据已经是二元化的。如果是浮点数,则执行二元化策略:以该数值为界:
- 特征取值大于它的作为 1 。
- 特征取值小于它的作为 0 。
- 其它参数参考
MultinomialNB。
模型方法:参考
MultinomialNB。

