
-
算法复杂度:较高的算法复杂度限制了某些
ANE算法在实际任务中的应用。已有一些算法基于网络的结构信息和属性信息来学习顶点embedding,但是这些算法要么在每个迭代step中使用了 复杂度的特征值分解, 要么使用了收敛速度很慢的梯度下降。heterogeneous异质信息:由于同时引入了结构信息和属性信息,因此如何在网络的结构和属性的联合空间中评估顶点的邻近度(即距离)是一个挑战。另外,随着网络规模的扩大,顶点的属性邻近度矩阵通常非常庞大,难以存储到单台计算机上,更别提对它进行操作。
噪音:网络结构信息和顶点属性信息可能都是残缺的、带噪音的,这进一步加入了顶点
embedding学习的难度。
因此,现有方法无法直接应用于
scalable的attributed network embedding。为解决该问题,论文《Accelerated Attributed Network Embedding》提出了一种加速属性网络embedding算法accelerated attributed network embedding:AANE。一方面,
AANE将顶点属性纳入到顶点embedding过程中;另一方面,AANE提出了一种分布式优化算法,该算法将复杂的建模和优化过程分解为很多子问题,从而能够以分布式方式完成联合学习。
设
 为一个网络,其中 为顶点集合,
为一个网络,其中 为顶点集合, 为定输数量, 为边的集合,
为定输数量, 为边的集合, 为权重矩阵。定义顶点 的直接邻接顶点为
为权重矩阵。定义顶点 的直接邻接顶点为  ,其大小为 。
,其大小为 。每条边
 关联一个权重 。这里我们关注于无向图,因此有
关联一个权重 。这里我们关注于无向图,因此有  。
。- 更大的 意味着顶点
 和 之间产生更强的关联,或者说更大的相似性。
和 之间产生更强的关联,或者说更大的相似性。  意味着顶点 和
意味着顶点 和  之间不存在边。
之间不存在边。
- 更大的 意味着顶点
- 定义顶点 的属性向量为
 ,其中 为属性的维度。定义属性矩阵为
,其中 为属性的维度。定义属性矩阵为  ,其中 为
,其中 为  的第 行。
的第 行。
定义
attributed network embedding为:给定网络 以及属性矩阵 ,任务的目的是给出每个顶点  一个低维
一个低维embedding向量 ,使得embedding向量能够同时保留顶点的结构邻近关系、顶点的属性邻近关系。ANE需要保留网络的结构邻近关系,为此AANE提出两个假设:- 首先,假设基于图的映射在边上是平滑的,特别是对于顶点密集的区域。即图上映射的连续性假设。
- 其次,边的权重更大的一对顶点更有可能具有相似的
embedding。
因此
AANE提出以下损失函数来最小化相连顶点之间的embedding差异:
当 较大时(顶点
和 相似性更大),为最小化  , 和
, 和  的距离将减小。
的距离将减小。ANE需要保留网络的属性邻近关系,AANE考虑利用顶点的embedding内积来逼近顶点的属性相似性。假设顶点 和
的属性相似性为 ,这里我们直接使用 cosin相似度。因此有:
AANE提出以下损失函数来最小化顶点之间的属性损失:其中
 为顶点之间的属性相似度矩阵;
为顶点之间的属性相似度矩阵;embedding矩阵为 ,其中 为 的第
为 的第  行。
行。现在我们有两个损失函数 和
 ,它们分别对顶点结构邻近度、顶点属性邻近度进行建模。为了对这两种邻近度在一个统一的、信息互补的联合空间中建模,
,它们分别对顶点结构邻近度、顶点属性邻近度进行建模。为了对这两种邻近度在一个统一的、信息互补的联合空间中建模,AANE模型为:其中
 用于平衡网络结构损失和属性损失:
用于平衡网络结构损失和属性损失:- 当 时,网络的结构不影响最终的顶点
embedding,顶点embedding由顶点的属性决定。 - 当
 时,最优解倾向于使得所有顶点的
时,最优解倾向于使得所有顶点的 embedding相同(即 ), 此时所有顶点在embedding空间中形成单个簇cluster。
因此我们可以通过调节
从而调整 embedding空间中簇的数量。- 当 时,网络的结构不影响最终的顶点
AANE可以视为带正则化项的矩阵分解,其中将 分解为 。在分解过程中施加了基于网络结构的正则化 ,该正则化迫使相连的顶点在
。在分解过程中施加了基于网络结构的正则化 ,该正则化迫使相连的顶点在 embedding空间中彼此靠近。AANE的目标函数不仅可以对网络结构邻近度和顶点属性邻近度进行联合建模,而且它还具有特殊的设计, 从而能够更有效地优化: 对每个 都是独立的,因此可以重新表述为双凸优化问题
对每个 都是独立的,因此可以重新表述为双凸优化问题 bi-convex optimization。令
 , 为
, 为  的第 行。因此有:
的第 行。因此有:
则目标函数重写为:
这表明
对每个 和  都是独立的。
都是独立的。引入增强的拉格朗日函数:
其中
 为对偶变量, 为罚项参数。
为对偶变量, 为罚项参数。我们可以交替优化
 从而得到 的极小值点。
从而得到 的极小值点。 为对偶变量构成的矩阵,其中 为 的第 行。对于顶点 ,在第 个
为对偶变量构成的矩阵,其中 为 的第 行。对于顶点 ,在第 个 step的更新为:
根据偏导数为零,我们解得 和
 :
:由于每个子问题都是凸的,因此当
 时 就是极值点。因此当
时 就是极值点。因此当  和 足够接近时,停止迭代。
和 足够接近时,停止迭代。由于原始问题是一个
bi-convex问题, 因此可以证明我们方法的收敛性,确保算法收敛到一个局部极小值点。这里有几点需要注意:
在计算
 之前必须计算所有的 。
之前必须计算所有的 。计算
 之间是相互独立的。
之间是相互独立的。机器内存有限,则也可以不必存储相似度矩阵 ,而是需要的时候相互独立计算
 :
:其中
 为 的第
为 的第  项, 为逐元素积。
项, 为逐元素积。
为了进行适当的初始化,我们在第一次迭代中将
 初始化为 的左奇异值。其中
初始化为 的左奇异值。其中  为一个矩阵,它包含了 的前
为一个矩阵,它包含了 的前  列。
列。AANE将优化过程分为 个子问题,然后迭代地求解它们。在每轮迭代过程中,可以分布式地将 (或者 )的 个更新 step分配给 个worker。当原始残差 或者对偶残差 足够小时,停止迭代。
或者对偶残差 足够小时,停止迭代。整体而言,
AANE优化算法具有以下优点:- 每个子任务的算法复杂度都很低。
- 算法很快就能够收敛到一个合适的解。
AANE优化算法:输入:
- 图

- 顶点属性矩阵
embedding维度
- 收敛阈值
- 图
输出:所有顶点的
embedding矩阵
步骤:
从属性矩阵 中提取前
列,构成 初始化:
 , 为
, 为  的左奇异向量, ,
的左奇异向量, , 
计算属性相似度矩阵
迭代,直到残差
 或者对偶残差 。迭代步骤为:
或者对偶残差 。迭代步骤为:- 计算

- 分配 个子任务到
 个
个 worker, 然后更新:对于 计算 。 - 计算
- 分配 个子任务到 个
worker, 然后更新:对于 计算 。
计算 。 - 计算

- 更新
- 计算
- 返回
下图说明了
AANE的基本过程:给定一个包含 个顶点的图,首先通过 和 来分解属性邻近度矩阵  ,在分解过程中增加了基于边的惩罚项,使得相连的顶点在
,在分解过程中增加了基于边的惩罚项,使得相连的顶点在 embedding空间中彼此靠近。这种惩罚由 来控制。在优化过程中,我们将原始问题划分为
 个复杂度很低的子问题:前
个复杂度很低的子问题:前 6个子问题相互独立、后6个子问题也相互独立。因此所有子问题可以分配给 个worker。在最终输出中,顶点
1和3的embedding分别为 以及 。它们距离非常接近,这表明它们在原始结构和属性的联合空间中彼此相似。
以及 。它们距离非常接近,这表明它们在原始结构和属性的联合空间中彼此相似。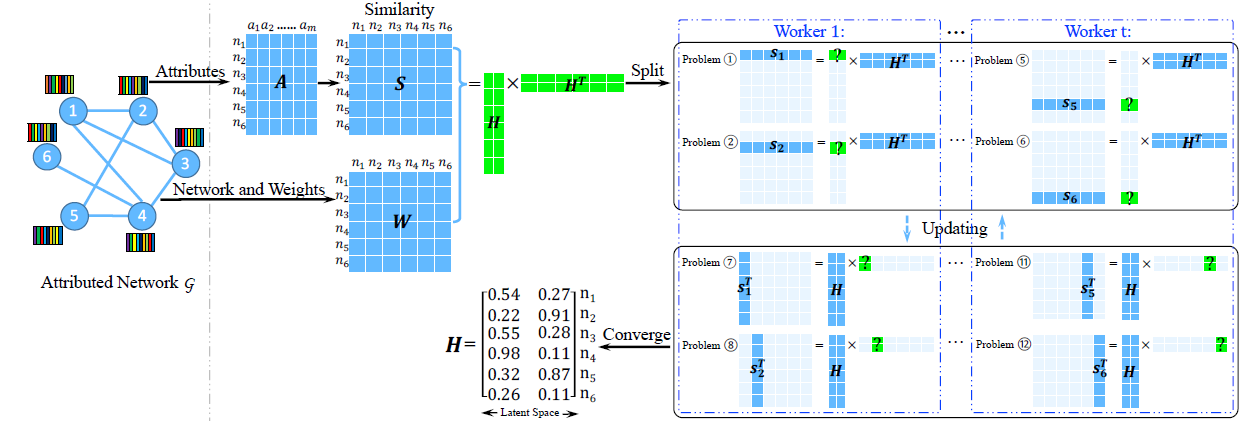
-
在初始化步骤,由于需要计算奇异值向量,因此计算复杂度为
在每个子任务过程中,更新
的计算复杂度为 。注意:我们只需要在每轮迭代中计算一次 。由于 , 因此其计算复杂度为  。
。另外,可以验证每个子任务的空间复杂度为 。
因此
AANE总的时间复杂度为 ,其中 为矩阵 的非零元素数量, 为
,其中 为矩阵 的非零元素数量, 为 worker数量。
19.2 实验
baseline模型:为评估顶点属性的贡献,我们对比了DeepWalk,LINE,PCA等模型,这些baseline模型仅能处理网络结构或者顶点属性,无法处理二者的融合;为了对比AANE的效率和效果,我们对比了其它的两种ANE模型LCMF, MultiSpec。DeepWalk:使用SkipGram学习基于图上的随机游走序列从而得到图的embedding。LINE:建模图的一阶邻近度和二阶邻近度从而得到图的embedding。PCA:经典的降维技术,它将属性矩阵 的 top d个主成分作为图的embedding。LCMF:它通过对网络结构信息和顶点属性信息进行联合矩阵分解来学习图的embedding。MultiSpec:它将网络结构和顶点属性视为两个视图view,然后在两个视图之间执行co-regularizing spectral clustering来学习图的embedding。
所有模型的 维度设置为 。
在所有实验中,我们首先在图上学习顶点的
embedding,然后根据学到的embedding向量作为特征,来训练一个SVM分类模型。分类模型在训练集上训练,然后在测试集上评估Macro-F1和Micro-F1指标。在训练
SVM时,我们使用五折交叉验证。所有的顶点被随机拆分为训练集、测试集,其中训练集和测试集之间的所有边都被移除。考虑到每个顶点可能属于多个类别,因此对每个类别我们训练一个二类SVM分类器。所有实验均随机重复
10并报告评估指标的均值。我们首先评估这些方法的效果。我们分别将分类训练集的规模设置为
10%,25%,50%,100%。其中,由于Yelp数据集的规模太大,大多数ANE方法的复杂度太高而无法训练,因此我们随机抽取其20%的数据并设置为新的数据集,即Yelp1。所有模型的分类效果如下所示:
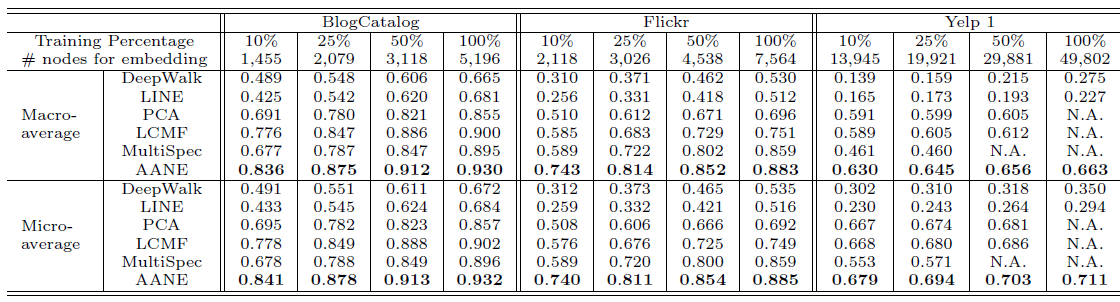
所有模型在完整的
Yelp数据集上的分类效果如下所示,其中PCA,LCMF,MultiSpec因为无法扩展到如此大的数据集,因此不参与比较:结论:
- 由于利用了顶点的属性信息,因此
LCMF,MultiSpec,AANE等属性网络embedding方法比DeepWalk,LINE等网络结构embedding方法效果更好。 - 我们提出的
AANE始终优于LCMF, MultiSpec方法。 LCMF,MultiSpec方法无法应用于大型数据集。
- 由于利用了顶点的属性信息,因此
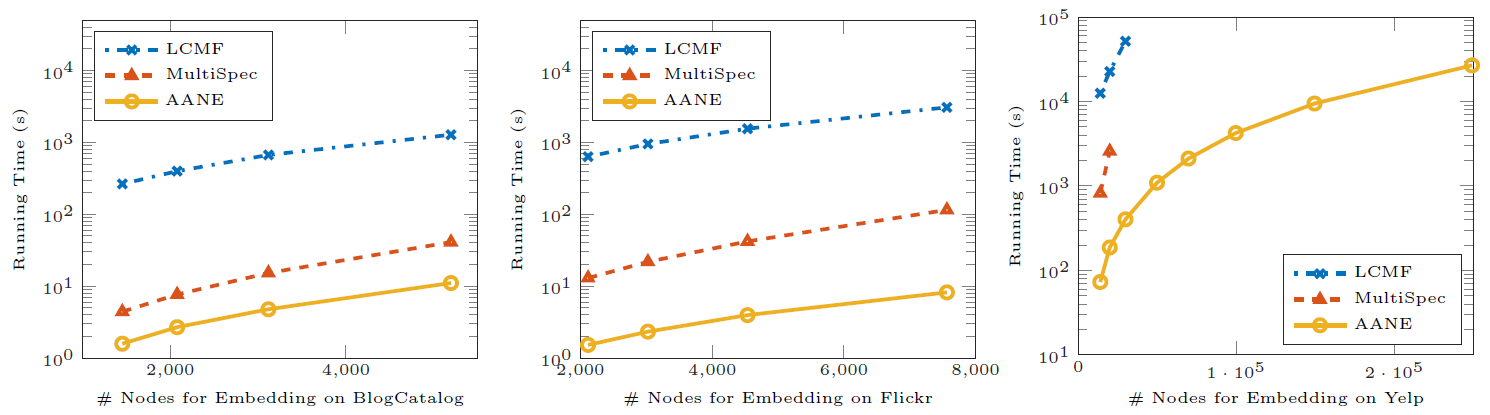
然后我们评估这些方法的训练效率。我们将
AANE和LCMF,MultiSpec这些属性网络embedding方法进行比较。下图给出了这些模型在不同数据集上、不同顶点规模的训练时间。结论:
AANE的训练时间始终比LCMF和MultiSpec更少。- 随着顶点规模的增加,训练效率之间的
gap也越来越大。 AANE可以在多线程环境下进一步提升训练效率。
参数敏感性:这里我们研究参数 和
的影响。参数 平衡了网络结构和顶点属性之间的贡献。为研究
的影响,我们将其从 变化到  ,对应的分类
,对应的分类 Micro-F1效果如下所示。- 当 接近于
0时,模型未考虑网络结构信息。随着 的增加,AANE开始考虑网络结构,因此性能不断提升。 - 当 接近
0.1时,模型在BlogCatalog和Flickr上的效果达到最佳。随着 的继续增加,模型性能下降。因为较大的 倾向于使得所有顶点具有相同的 embedding。
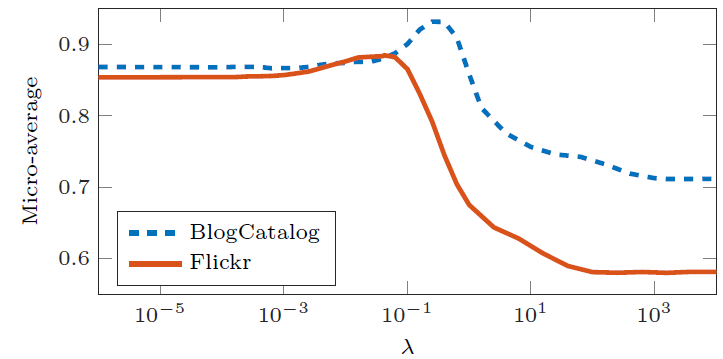
- 当 接近于
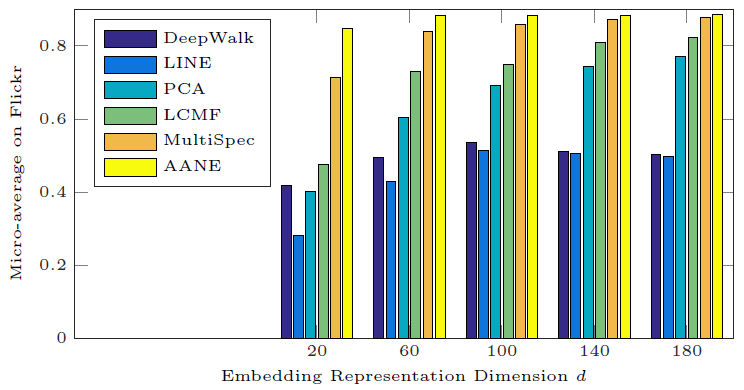
为研究
embedding维度 的影响,我们将 从 10变化到180,对应的分类Micro-F1效果如下所示。我们仅给出Flickr数据集的结果,BlogCatalog和Yelp的结果也是类似的。可以看到:
- 无论 为多少,
DeepWalk和LINE都不如属性网络embedding方法(AANE,LCMF,MultiSpec) - 无论 为多少,
AANE的效果始终最佳。 - 当 增加时,这些模型的效果先提高、然后保持稳定。这表示低维
embedding已经能够捕获大多数有意义的信息。
- 无论 为多少,

