
- 代价函数的选取和输出单元的类型紧紧相关。
- 任何类型的输出单元,也可以用作隐单元。
-
- 给定特征 ,单个线性输出单元的输出为:
 。
。 - 若输出层包含多个线性输出单元,则线性输出层的输出为: 。
- 给定特征 ,单个线性输出单元的输出为:
线性输出层经常用于学习条件高斯分布的均值:
 。
。给定 的条件下,
 的分布为均值为 、方差为 的高斯分布。此时:最大化对数似然函数等价于最小化均方误差。
的分布为均值为 、方差为 的高斯分布。此时:最大化对数似然函数等价于最小化均方误差。线性模型不会饱和,因此可以方便的使用基于梯度的优化算法。
sigmoid单元:用于Bernoulli分布的输出。二类分类问题可以用伯努利分布来描述。由于伯努利分布只需要一个参数来定义,因此神经网络只需要预测
 ,它必须位于区间
,它必须位于区间 [0,1]之间。一种方案是采用线性单元,但是通过阈值来使它位于
[0,1]之间:令
 ,则上式右侧就是函数 ,函数图象如下。
,则上式右侧就是函数 ,函数图象如下。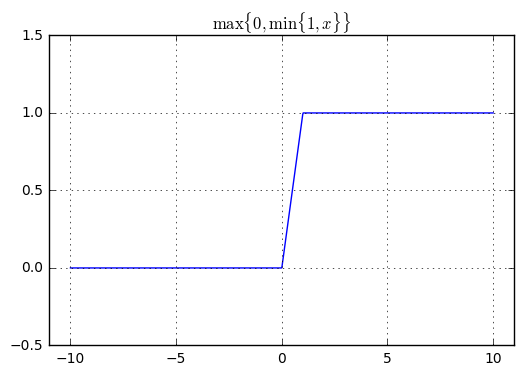
该函数有个问题:当 位于
[0,1]之外时,模型的输出 对于 的梯度都为 0。根据反向传播算法,此时
对于 的梯度都为 0。根据反向传播算法,此时  对于参数 和参数
对于参数 和参数  的梯度都为零。从而使得梯度下降算法难以推进。
的梯度都为零。从而使得梯度下降算法难以推进。另一种方案就是采用
sigmoid单元: ,其中 就是
就是sigmoid函数。虽然
sigmoid函数也存在饱和的问题,但是它比 要稍微缓解。
要稍微缓解。
sigmoid输出单元有两个部分:首先它用一个线性层来计算 ;然后它使用sigmoid激活函数将 转化成概率。
转化成概率。根据:
则有: 。即:

单元的代价函数通常采用负的对数似然函数:
其中
 ,它是函数 的一个近似。
,它是函数 的一个近似。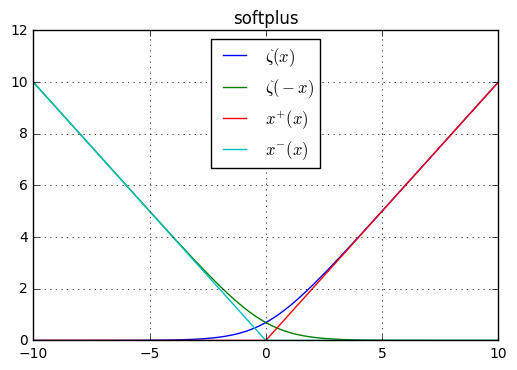
可以看到,只有当 取一个非常大的负值时,代价函数才非常接近于0。因此代价为0发生在:
 且 为一个较大的正值,此时表示正类分类正确。
且 为一个较大的正值,此时表示正类分类正确。 且 为一个较大的负值 ,此时表示负类分类正确。
且 为一个较大的负值 ,此时表示负类分类正确。
当
符号错误时(即 为负数,而 ;或者 为正数,但是  ), ,则
), ,则softplus函数会渐进地趋向于 ,且其梯度不会收缩。这意味着基于梯度的学习可以很快地改正错误的 。
,且其梯度不会收缩。这意味着基于梯度的学习可以很快地改正错误的 。当使用其他代价函数时(如均方误差),代价函数会在任何
 饱和时饱和,此时梯度会变得非常小从而无法学习。
饱和时饱和,此时梯度会变得非常小从而无法学习。因此最大似然函数总是训练
sigmoid输出单元的首选代价函数。
当表示一个具有 个可能取值的离散型随机变量分布时,可以采用
softmax函数。它可以视作sigmoid函数的扩展:
表示类别为
 的概率。
的概率。当所有输入都加上一个相同常数时,
softmax的输出不变。即: 。根据该性质,可以导出一个数值稳定的
softmax函数的变体:
-
argmax函数的结果为一个独热向量(只有一个元素为1,其余元素都是0),且不可微。softmax函数是连续可微的。当某个输入最大(),且
 远大于其他的输入时,对应的位置输出非常接近 1 ,其余的位置的输出非常接近 0 。
远大于其他的输入时,对应的位置输出非常接近 1 ,其余的位置的输出非常接近 0 。max函数的软化版本为 。
假设真实类别为
 ,则
,则softmax输出的对数似然函数为: 。其中:第一项
 不会饱和(它的梯度不会为零),第二项近似为 。
不会饱和(它的梯度不会为零),第二项近似为 。为了最大化对数似然函数:第一项鼓励
较大,第二项鼓励所有的 较小。此时意味着:若真实类别为 ,则 较大,其它的  较小。
较小。基于对数似然函数的代价函数为: 。
因此代价函数惩罚那个最活跃的预测(最大的
)。如果 ,则代价函数近似为零。当输入是绝对值较小的负数时,
 的计算结果可能为 0 。此时 趋向于负无穷,非数值稳定的。
的计算结果可能为 0 。此时 趋向于负无穷,非数值稳定的。因此需要设计专门的函数来计算
 ,而不是将 的结果传递给
,而不是将 的结果传递给  函数。
函数。除了负对数似然,其他的许多代价函数对
softmax函数不适用(如均方误差代价函数)。softmax函数将在很多情况下饱和,饱和意味着梯度消失,而梯度消失会造成学习困难。softmax函数饱和时,此时基于softmax函数的代价函数也饱和;除非它们能将softmax转化为成其它形式,如对数形式。
-
如果定义了一个条件分布 ,则最大似然准则建议使用
 作为代价函数。
作为代价函数。

