
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False):根据各label的值中是否存在缺失数据来对轴label进行过滤。axis:指定沿着哪个轴进行过滤。如果为0/'index',则沿着0轴;如果为1/'columns',则沿着1轴。你也可以同时提供两个轴(以列表或者元组的形式)how:指定过滤方式。如果为'any',则如果该label对应的数据中只要有任何NaN,则抛弃该label;如果为'all',则如果该label对应的数据中必须全部为NaN才抛弃该label。thresh:一个整数,要求该label必须有thresh个非NaN才保留下来。它比how的优先级较高。subset:一个label的array-like。比如axis=0,则subset为轴 1 上的标签,它指定你考虑哪些列的子集上的NaNinplace:一个布尔值。如果为True,则原地修改。否则返回一个新创建的DataFrame
对于
Series,其签名为:Series.dropna(axis=0, inplace=False, **kwargs)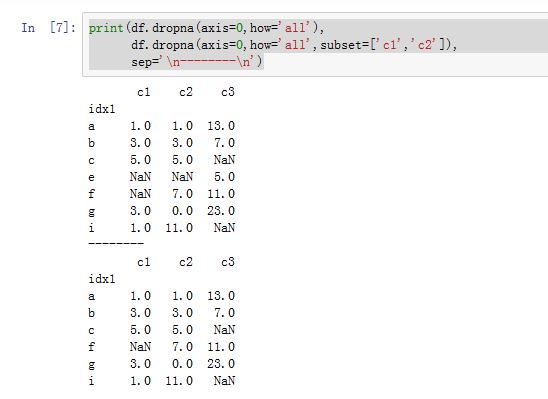
DataFrame/Series.fillna(value=None, method=None, axis=None, inplace=False, limit=None,downcast=None, **kwargs):用指定值或者插值方法来填充缺失数据。value:一个标量、字典、Series或者DataFrame。注意:value与method只能指定其中之一,不能同时提供。- 如果为标量,则它指定了填充
NaN的数据。 - 如果为
Series/dict,则它指定了填充每个index的数据 - 如果为
DataFrame,则它指定了填充每个DataFrame单元的数据
- 如果为标量,则它指定了填充
method:指定填充方式。可以为,也可以为:'backfill'/'bfill':使用下一个可用的有效值来填充(后向填充)'ffill'/'pad':使用前一个可用的有效值来填充(前向填充)
axis:指定沿着哪个轴进行填充。如果为0/'index',则沿着0轴;如果为1/'columns',则沿着1轴limit:一个整数。如果method提供了,则当有连续的N个NaN时,只有其中的limit个NaN会被填充(注意:对于前向填充和后向填充,剩余的空缺的位置不同)downcast:一个字典,用于类型转换。字典形式为:{label->dtype},dtype可以为字符串,也可以为np.float64等。

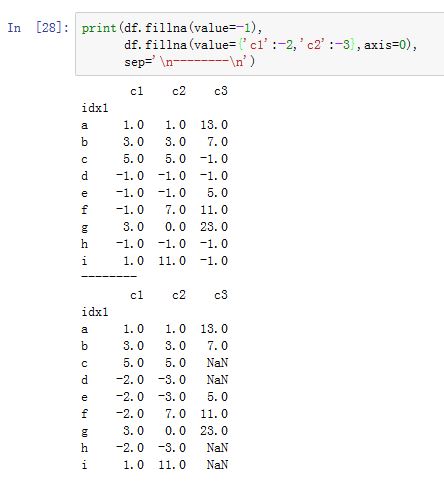
-
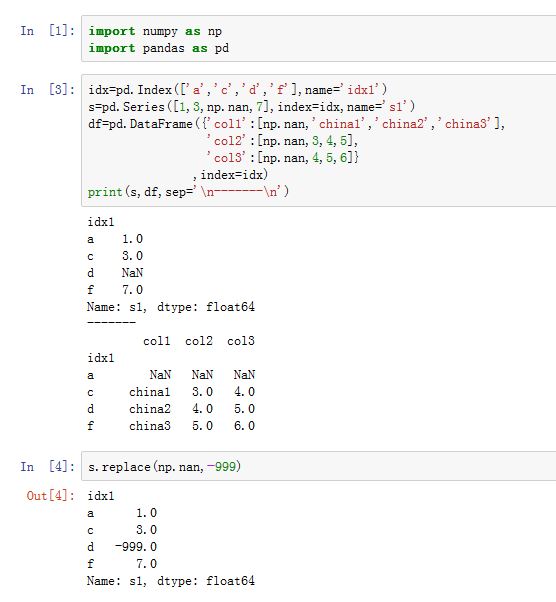
DataFrame/Series.notnull():返回一个同样尺寸的布尔类型的对象,来指示每个值是否是not null fillna()方法可以看作是值替换的一种特殊情况。更通用的是值替换replace()方法。to_replace:一个字符串、正则表达式、列表、字典、Series、数值、None。指示了需要被替换的那些值字符串:则只有严格等于该字符串的那些值才被替换
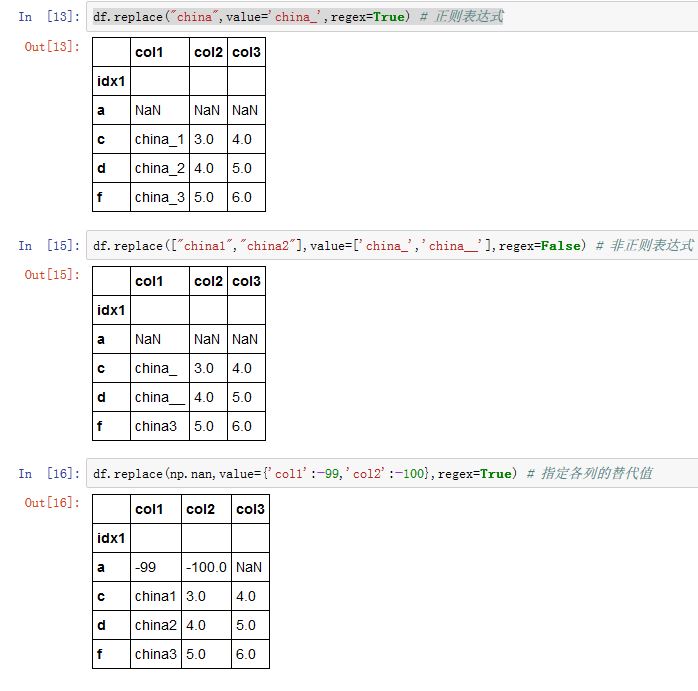
正则表达式:只有匹配该正则表达式的那些值才被替换(
regex=True)列表:
- 如果
to_place和value都是列表,则它们必须长度严格相等 - 如果
regex=True,则列表中所有字符串都是正则表达式。
- 如果
字典:字典的键对应了被替换的值,字典的值给出了替换值。如果是嵌套字典,则最外层的键给出了
column名None:此时regex必须是个字符串,该字符串可以表示正则表达式、列表、字典、ndarray等。如果value也是None,则to_replace必须是个嵌套字典。
value:一个字符串、正则表达式、列表、字典、Series、数值、None。给出了替换值。如果是个字典,则键指出了将填充哪些列(不在其中的那些列将不被填充)inplace:一个布尔值。如果为True,则原地修改。否则创建新对象。limit:一个整数,指定了连续填充的最大跨度。-
- 如果是个字符串,则
to_replace必须为None,因为它会被视作过滤器
- 如果是个字符串,则
method:指定填充类型。可以为'pad'/'ffill'/'bfill'。当to_replace是个列表时该参数有效。
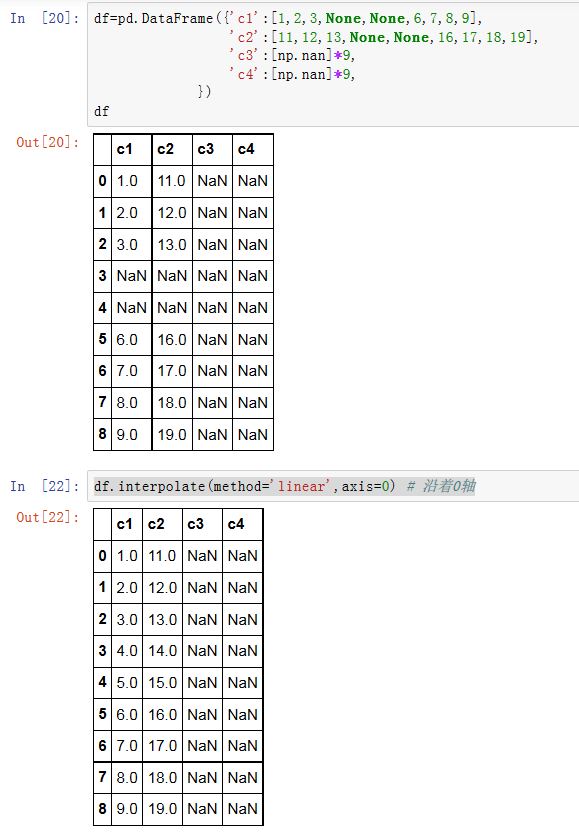
interpolate是通过前后数据插值来填充NaN。Series/DataFrame.interpolate(method='linear', axis=0, limit=None, inplace=False,limit_direction='forward', downcast=None, **kwargs)
method:一个字符串,指定插值的方法。'linear':线性插值。只有它支持MultiIndex'index'/'values':使用索引标签的整数下标来辅助插值'nearest', 'zero', 'slinear', 'quadratic', 'cubic',
'barycentric', 'polynomial'使用scipy.interpolate.interp1d。对于'polynomial'/'spline',你需要传入一个order(一个整数)'krogh', 'piecewise_polynomial', 'spline', 'pchip','akima'也使用了scipy的插值算法。它们使用索引标签的整数下标来辅助插值。'time': interpolation works on daily and higher resolution data to interpolate given length of interval
axis:指定插值的轴。如果为0/'index'则沿着0 轴;如果为1/'columns'则沿着 1 轴limit:一个整数,指定插值时,如果有K个连续的NaN,则只插值其中的limit个limit_direction:一个字符串。当设定了limit时,指定处理前面limit个NaN,还是后面limit个NaN。可以为'forward'/'backward'/'both'inplace:一个布尔值。如果为True,则原地修改。否则创建新对象。其他参数是传递给
scipy的插值函数的。
3. 缺失数据
本文档使用 BookStack 构建

