
-
而
Inception网络考虑的是多种卷积核的并行计算,扩展了网络的宽度。 Inception Net核心思想是:稀疏连接。因为生物神经连接是稀疏的。Inception网络的最大特点是大量使用了Inception模块。
4.1.1 网络结构
InceptionNet V1是一个22层的深度网络。 如果考虑池化层,则有29层。如下图中的depth列所示。网络具有三组
Inception模块,分别为:inception(3a)/inception(3b)、inception(4a)/inception(4b)/inception(4c)/inception(4d)/inception(4e)、inception(5a)、inception(5b)。三组Inception模块被池化层分隔。下图给出了网络的层次结构和参数,其中:
type列:给出了每个模块/层的类型。patch size/stride列:给出了卷积层/池化层的尺寸和步长。output size列:给出了每个模块/层的输出尺寸和输出通道数。depth列:给出了每个模块/层包含的、含有训练参数层的数量。#1x1列:给出了每个模块/层包含的1x1卷积核的数量,它就是1x1卷积核的输出通道数。#3x3 reduce列:给出了每个模块/层包含的、放置在3x3卷积层之前的1x1卷积核的数量,它就是1x1卷积核的输出通道数。#3x3列:给出了每个模块/层包含的3x3卷积核的数量,它就是3x3卷积核的输出通道数。#5x5 reduce列:给出了每个模块/层包含的、放置在5x5卷积层之前的1x1卷积核的数量,它就是1x1卷积核的输出通道数。#5x5列:给出了每个模块/层包含的5x5卷积核的数量,它就是5x5卷积核的输出通道数。pool proj列:给出了每个模块/层包含的、放置在池化层之后的1x1卷积核的数量,它就是1x1卷积核的输出通道数。params列:给出了每个模块/层的参数数量。ops列:给出了每个模块/层的计算量。
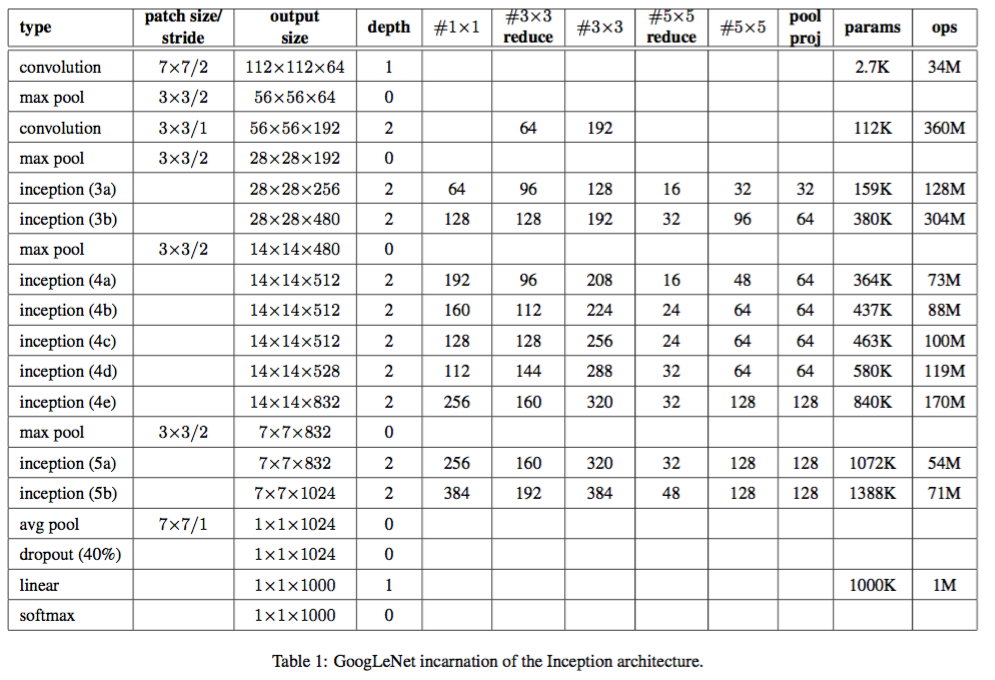
Inception V1的参数数量为 697.7 万,其参数数量远远小于AlexNet(6千万)、VGG-Net(超过1亿)。Inception V1参数数量能缩减的一个主要技巧是:在inception(5b)输出到linear之间插入一个平均池化层avg pool。- 如果没有平均池化层,则
inception(5b)到linear之间的参数数量为:7x7x1024x1024,约为 5 千万。 - 插入了平均池化层之后,
inception(5b)到linear之间的参数数量为:1x1x1024x1024,约为 1百万。
- 如果没有平均池化层,则
4.1.2 Inception 模块
原始的
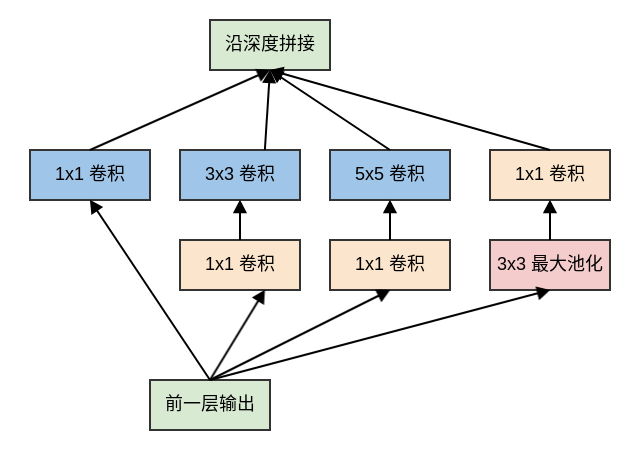
Inception模块对输入同时执行:3个不同大小的卷积操作(1x1、3x3、5x5)、1个最大池化操作(3x3)。所有操作的输出都在深度方向拼接起来,向后一级传递。三种不同大小卷积:通过不同尺寸的卷积核抓取不同大小的对象的特征。
使用
1x1、3x3、5x5这些具体尺寸仅仅是为了便利性,事实上也可以使用更多的、其它尺寸的滤波器。1个最大池化:提取图像的原始特征(不经过过滤器)。
原始
Inception模块中,模块的输出通道数量为四个子层的输出通道数的叠加。这种叠加不可避免的使得Inception模块的输出通道数增加,这就增加了Inception模块中每个卷积的计算量。因此在经过若干个模块之后,计算量会爆炸性增长。解决方案是:在
3x3和5x5卷积层之前额外添加1x1卷积层,来限制输入给卷积层的输入通道的数量。注意:
1x1卷积是在最大池化层之后,而不是之前。这是因为:池化层是为了提取图像的原始特征,一旦它接在1x1卷积之后就失去了最初的本意。1x1卷积在3x3、5x5卷积之前。这是因为:如果1x1卷积在它们之后,则3x3卷积、5x5卷积的输入通道数太大,导致计算量仍然巨大。
4.1.3 辅助分类器
为了缓解梯度消失的问题,
InceptionNet V1给出了两个辅助分类器。这两个辅助分类器被添加到网络的中间层,它们和主分类器共享同一套训练数据及其标记。其中:第一个辅助分类器位于
Inception(4a)之后,Inception(4a)模块的输出作为它的输入。第二个辅助分类器位于
Inception(4d)之后,Inception(4d)模块的输出作为它的输入。两个辅助分类器的结构相同,包括以下组件:
- 一个尺寸为
5x5、步长为3的平均池化层。 - 一个尺寸为
1x1、输出通道数为128的卷积层。 - 一个具有
1024个单元的全连接层。 - 一个
drop rate = 70%的dropout层。 - 一个使用
softmax损失的线性层作为输出层。
- 一个尺寸为
在训练期间,两个辅助分类器的损失函数的权重是0.3,它们的损失被叠加到网络的整体损失上。在推断期间,这两个辅助网络被丢弃。
在
Inception v3的实验中表明:辅助网络的影响相对较小,只需要其中一个就能够取得同样的效果。事实上辅助分类器在训练早期并没有多少贡献。只有在训练接近结束,辅助分支网络开始发挥作用,获得超出无辅助分类器网络的结果。
Inception v2的主要贡献是提出了Batch Normalization。论文指出,使用了Batch Normalization之后:可以加速网络的学习。
相比
Inception v1,训练速度提升了14倍。因为应用了BN之后,网络可以使用更高的学习率,同时删除了某些层。网络具有更好的泛化能力。
在
ImageNet分类问题的top5上达到4.8%,超过了人类标注top5的准确率。
Inception V2网络训练的技巧有:- 使用更高的学习率。
- 删除
dropout层、LRN层。 - 减小
L2正则化的系数。 - 更快的衰减学习率。学习率以指数形式衰减。
- 更彻底的混洗训练样本,使得一组样本在不同的
epoch中处于不同的mini batch中。 - 减少图片的形变。
Inception v2的网络结构比Inception v1有少量改动:5x5卷积被两个3x3卷积替代。这使得网络的最大深度增加了 9 层,同时网络参数数量增加 25%,计算量增加 30%。
28x28的inception模块从2个增加到3个。在
inception模块中,有的采用最大池化,有的采用平均池化。在
inception模块之间取消了用作连接的池化层。inception(3c),inception(4e)的子层采用步长为 2 的卷积/池化。
Inception V2的网络参数约为1126万。Inception V2在ImageNet测试集上的误差率: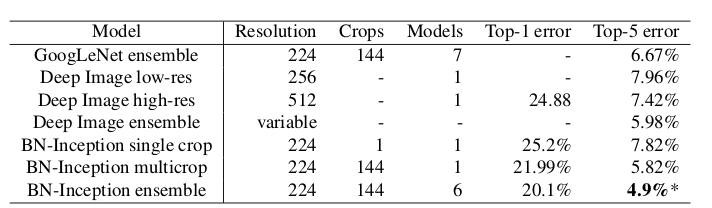
虽然
Inception v1的参数较少,但是它的结构比较复杂,难以进行修改。原因有以下两点:- 如果单纯的放大网络(如增加
Inception模块的数量、扩展Inception模块的大小),则参数的数量会显著增长,计算代价太大。 Inception v1结构中的各种设计,其对最终结果的贡献尚未明确。
因此
Inception v3的论文重点探讨了网络结构设计的原则。- 如果单纯的放大网络(如增加
4.3.1 网络结构
Inception v3的网络深度为42层,它相对于Inception v1网络主要做了以下改动:7x7卷积替换为3个3x3卷积。3个
Inception模块:模块中的5x5卷积替换为2个3x3卷积,同时使用后面描述的网格尺寸缩减技术。5个
Inception模块:模块中的5x5卷积替换为2个3x3卷积之后,所有的nxn卷积进行非对称分解,同时使用后面描述的网格尺寸缩减技术。2个
Inception模块:结构如下。它也使用了卷积分解技术,以及网格尺寸缩减技术。
Inception v3的网络结构如下所示:3xInception表示三个Inception模块,4xInception表示四个Inception模块,5xInception表示五个Inception模块。conv padded表示使用0填充的卷积,它可以保持feature map的尺寸。在
Inception模块内的卷积也使用0填充,所有其它的卷积/池化不再使用填充。
在
3xInception模块的输出之后设有一个辅助分类器。其结构如下: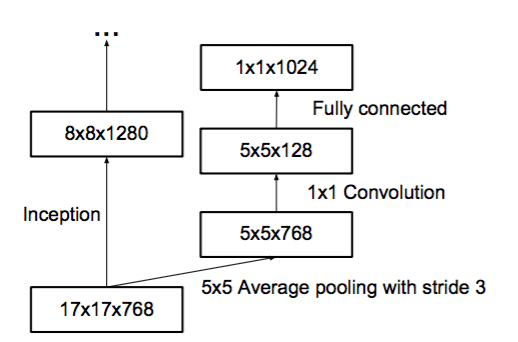
Inception v3整体参数数量约 23,626,728万(论文Xception: Deep Learning with Depthwise Separable Convolutions)。
4.3.2 设计技巧
Inception v3总结出网络设计的一套通用设计原则:避免
representation瓶颈:representation的大小应该从输入到输出缓缓减小,避免极端压缩。在缩小feature map尺寸的同时,应该增加feature map的通道数。representation大小通常指的是feature map的容量,即feature map的width x height x channel。空间聚合:可以通过空间聚合来完成低维嵌入,而不会在表达能力上有较大的损失。因此通常在
nxn卷积之前,先利用1x1卷积来降低输入维度。猜测的原因是:空间维度之间的强相关性导致了空间聚合过程中的信息丢失较少。
平衡网络的宽度和深度:增加网络的宽度或者深度都可以提高网络的泛化能力,因此计算资源需要在网络的深度和宽度之间取得平衡。
4.3.2.1 卷积尺寸分解
大卷积核的分解:将大卷积核分解为多个小的卷积核。
如:使用2个
3x3卷积替换5x5卷积,则其参数数量大约是1个5x5卷积的 72% 。nxn卷积核的非对称分解:将nxn卷积替换为1xn卷积和nx1卷积。- 这种非对称分解的参数数量是原始卷积数量的
 。随着
。随着n的增加,计算成本的节省非常显著。 - 论文指出:对于较大的
feature map,这种分解不能很好的工作;但是对于中等大小的feature map(尺寸在12~20之间),这种分解效果非常好。
- 这种非对称分解的参数数量是原始卷积数量的
4.3.2.2 网格尺寸缩减
假设输入的
feature map尺寸为dxd,通道数为k。如果希望输出的feature map尺寸为d/2 x d/2,通道数为2k。则有以下的两种方式:首先使用
2k个1x1的卷积核,执行步长为1的卷积。然后执行一个2x2的、步长为2的池化操作。该方式需要执行
 次
次乘-加操作,计算代价较大。直接使用
2k个1x1的卷积核,执行步长为2的卷积。该方式需要执行 次
乘-加操作,计算代价相对较小。但是表征能力下降,产生了表征瓶颈。
事实上每个
Inception模块都会使得feature map尺寸缩半、通道翻倍,因此在这个过程中需要仔细设计网络,使得既能够保证网络的表征能力,又不至于计算代价太大。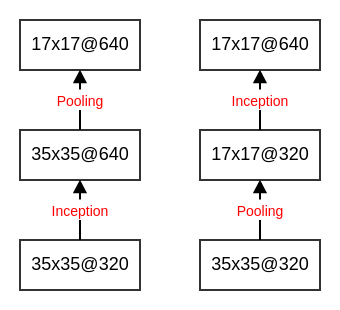
解决方案是:采用两个模块
P和C。- 模块
P:使用k个1x1的卷积核,执行步长为2的卷积。其输出feature map尺寸为d/2 x d/2,通道数为k。 - 模块
C:使用步长为2的池化。其输出feature map尺寸为d/2 x d/2,通道数为k。
将模块
P和模块C的输出按照通道数拼接,产生最终的输出feature map。- 模块
4.3.2.3 标签平滑正则化
标签平滑正则化的原理:假设样本的真实标记存在一定程度上的噪声。即:样本的真实标记不一定是可信的。
对给定的样本
 ,其真实标记为 。在普通的训练中,该样本的类别分布为一个
,其真实标记为 。在普通的训练中,该样本的类别分布为一个  函数:。记做
函数:。记做  。
。采用标签平滑正则化(
LSR:Label Smoothing Regularization)之后,该样本的类别分布为:其中
 是一个很小的正数(如 0.1),其物理意义为:样本标签不可信的比例。
是一个很小的正数(如 0.1),其物理意义为:样本标签不可信的比例。该类别分布的物理意义为:
- 样本 的类别为
 的概率为 。
的概率为 。 - 样本 的类别为 的概率均
 。
。
- 样本 的类别为
- 论文指出:标签平滑正则化对
top-1错误率和top-5错误率提升了大约 0.2% 。
性能比较:(综合采用了
144 crops/dense评估的结果,数据集:ILSVRC 2012的验证集 )Inception-ResNet-v2参数数量约为 5500万,Inception-ResNet-v1/Inception-v4的参数数量也在该量级。
4.4.1 Inception v4
在
Inception v4结构的主要改动:修改了
stem部分。引入了
Inception-A、Inception-B、Inception-C三个模块。这些模块看起来和Inception v3变体非常相似。Inception-A/B/C模块中,输入 和输出feature map形状相同。而Reduction-A/B模块中,输出feature map的宽/高减半、通道数增加。引入了专用的“缩减块”(
reduction block),它被用于缩减feature map的宽、高。早期的版本并没有明确使用缩减块,但是也实现了其功能。
Inception v4结构如下:(没有标记V的卷积使用same填充;标记V的卷积使用valid填充)stem部分的结构: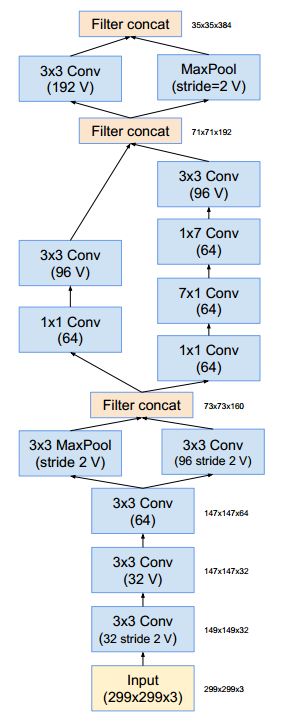
Inception-A模块(这样的模块有4个):Inception-B模块(这样的模块有7个):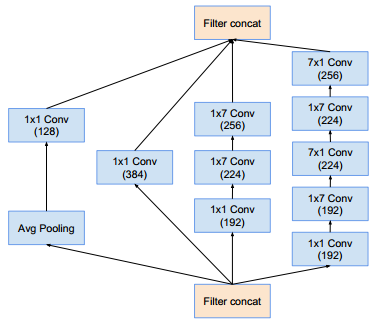
Reduction-A模块:(其中 分别表示滤波器的数量)
分别表示滤波器的数量)Reduction-B模块: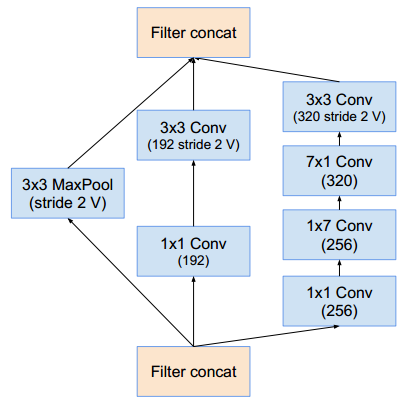
4.4.2 Inception-ResNet
在
Inception-ResNet中,使用了更廉价的Inception块:inception模块的池化运算由残差连接替代。在
Reduction模块中能够找到池化运算。
Inception ResNet有两个版本:v1和v2。v1的计算成本和Inception v3的接近,v2的计算成本和Inception v4的接近。v1和v2具有不同的stem。- 两个版本都有相同的模块
A、B、C和缩减块结构,唯一不同在于超参数设置。
Inception-ResNet-v1结构如下:stem部分的结构: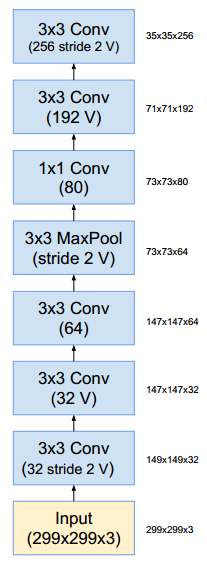
Inception-ResNet-A模块(这样的模块有5个):Inception-B模块(这样的模块有10个):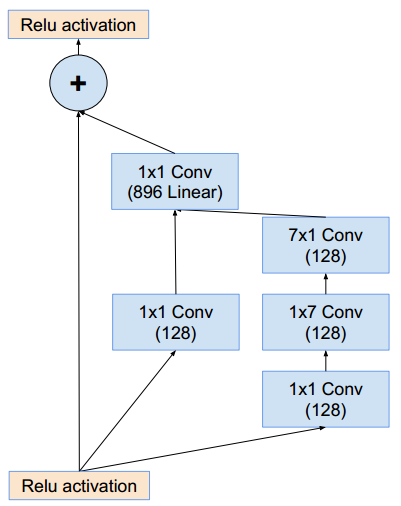
Inception-C模块(这样的模块有5个):Reduction-A模块:同inception_v4的Reduction-A模块Reduction-B模块: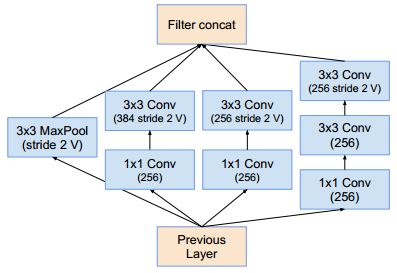
Inception-ResNet-v2结构与Inception-ResNet-v1基本相同 :stem部分的结构:同inception_v4的stem部分。Inception-ResNet-v2使用了inception v4的stem部分,因此后续的通道数量与Inception-ResNet-v1不同。Inception-ResNet-A模块(这样的模块有5个):它的结构与Inception-ResNet-v1的Inception-ResNet-A相同,只是通道数发生了改变。Inception-B模块(这样的模块有10个):它的结构与Inception-ResNet-v1的Inception-ResNet-B相同,只是通道数发生了改变。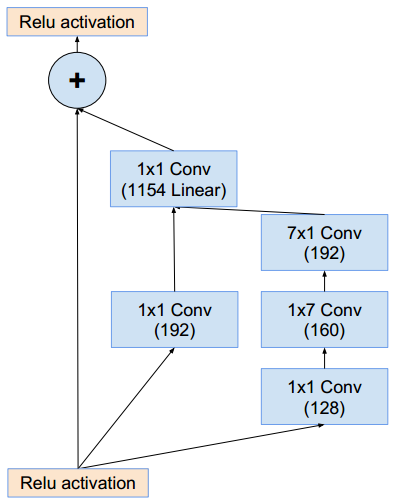
Inception-C模块(这样的模块有5个):它的结构与Inception-ResNet-v1的Inception-ResNet-C相同,只是通道数发生了改变。Reduction-A模块:同inception_v4的Reduction-A模块。Reduction-B模块:它的结构与Inception-ResNet-v1的Reduction-B相同,只是通道数发生了改变。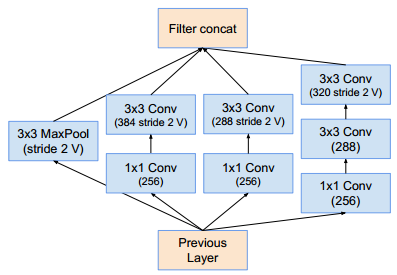
如果滤波器数量超过1000,则残差网络开始出现不稳定,同时网络会在训练过程早期出现“死亡”:经过成千上万次迭代之后,在平均池化之前的层开始只生成 0 。
解决方案:在残差模块添加到
activation激活层之前,对其进行缩放能够稳定训练。降低学习率或者增加额外的BN都无法避免这种状况。这就是
Inception ResNet中的Inception-A,Inception-B,Inception-C为何如此设计的原因。- 将
Inception-A,Inception-B,Inception-C放置在两个Relu activation之间。 - 通过线性的
1x1 Conv(不带激活函数)来执行对残差的线性缩放。
- 将
一个常规的卷积核尝试在三维空间中使用滤波器抽取特征,包括:两个空间维度(宽度和高度)、一个通道维度。因此单个卷积核的任务是:同时映射跨通道的相关性和空间相关性。
Inception将这个过程明确的分解为一系列独立的相关性的映射:要么考虑跨通道相关性,要么考虑空间相关性。Inception的做法是:- 首先通过一组
1x1卷积来查看跨通道的相关性,将输入数据映射到比原始输入空间小的三个或者四个独立空间。 - 然后通过常规的
3x3或者5x5卷积,将所有的相关性(包含了跨通道相关性和空间相关性)映射到这些较小的三维空间中。
一个典型的
Inception模块(Inception V3)如下: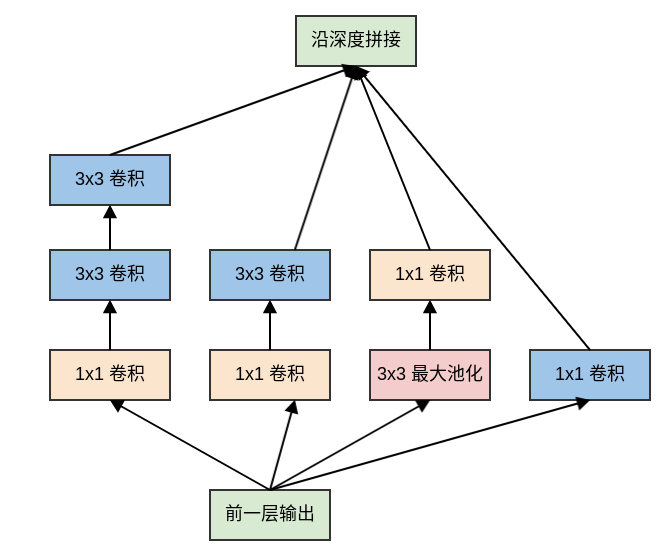
可以简化为:
- 首先通过一组
Xception将这一思想发挥到极致:首先使用1x1卷积来映射跨通道相关性,然后分别映射每个输出通道的空间相关性,从而将跨通道相关性和空间相关性解耦。因此该网络被称作Xception:Extreme Inception,其中的Inception块被称作Xception块。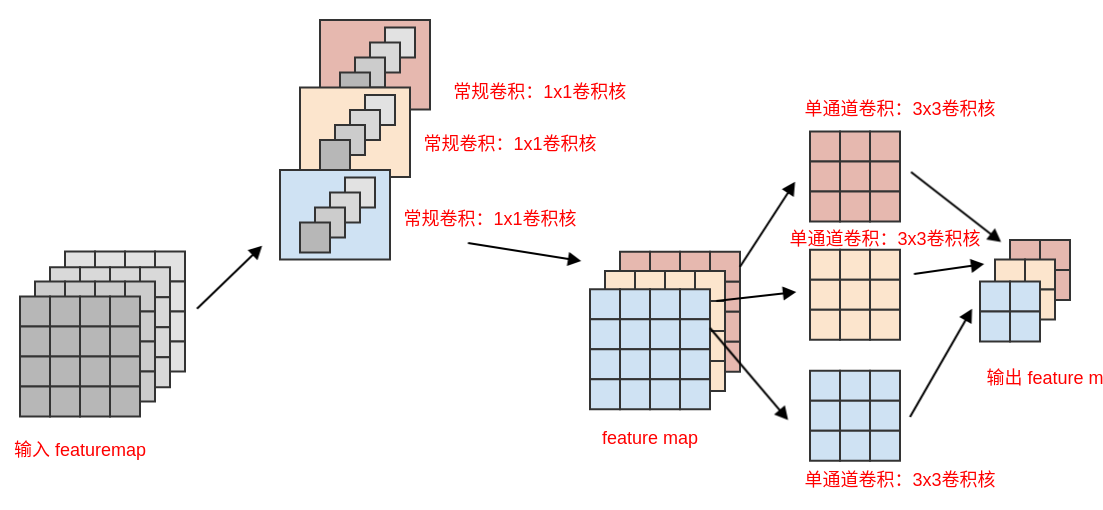
Xception块类似于深度可分离卷积,但是它与深度可分离卷积之间有两个细微的差异:操作顺序不同:
- 深度可分离卷积通常首先执行
channel-wise空间卷积,然后再执行1x1卷积。 Xception块首先执行1x1卷积,然后再进行channel-wise空间卷积。
- 深度可分离卷积通常首先执行
第一次卷积操作之后是否存在非线性:
- 深度可分离卷积只有第二个卷积(
1x1)使用了ReLU非线性激活函数,channel-wise空间卷积不使用非线性激活函数。 Xception块的两个卷积(1x1和3x3)都使用了ReLU非线性激活函数。
- 深度可分离卷积只有第二个卷积(
其中第二个差异更为重要。
对
Xception进行以下的修改,都可以加快网络收敛速度,并获取更高的准确率:- 引入类似
ResNet的残差连接机制。 - 在
1x1卷积和3x3卷积之间不加入任何非线性。
- 引入类似
Xception的参数数量与Inception V3相同,但是性能表现显著优于Inception V3。这表明Xception更加高效的利用了模型参数。根据论文
Xception: Deep Learning with Depthwise Separable Convolutions,Inception V3参数数量为 23626728,Xception参数数量为 22855952 。

