
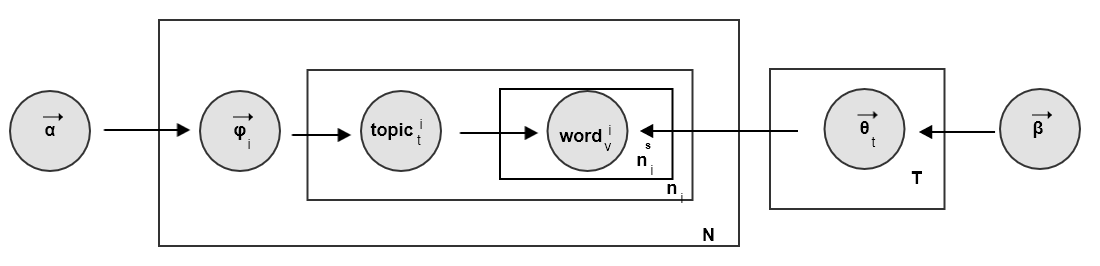
Sentence-LDA的文档生成过程:根据参数为 的狄利克雷分布随机采样,对每个话题
 生成一个单词分布 。每个话题采样一次,一共采样
生成一个单词分布 。每个话题采样一次,一共采样  次。
次。对每篇文档 :
根据参数为
 的狄利克雷分布随机采样,生成文档 的一个话题分布
的狄利克雷分布随机采样,生成文档 的一个话题分布  。每篇文档采样一次。
。每篇文档采样一次。对文档 中的每个句子:
从话题分布中
 中采样一个话题 ,然后从话题的单词分布
中采样一个话题 ,然后从话题的单词分布  采样 个单词 。
采样 个单词 。  为句子的编号。
为句子的编号。此时这些单词的话题都是 。
重复生成
 个句子,得到一篇包含 个句子的文档。
个句子,得到一篇包含 个句子的文档。
Sentence-LDA的吉布斯采样概率为:各参数的意义为:

Sentence-LDA得到的文档-主题概率分布为: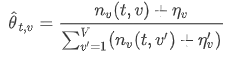
其中:
5.2 ASUM
论文
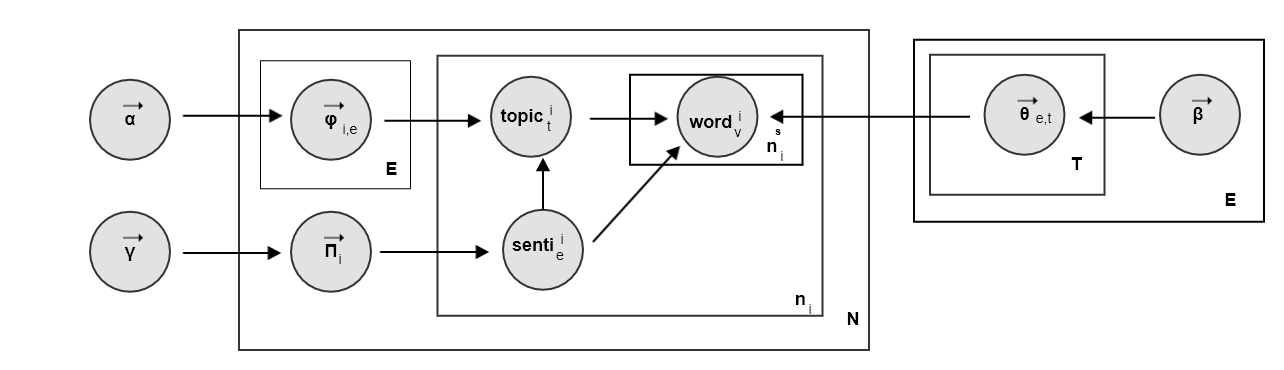
Aspect and sentiment unification model for online review analysis中提出了sentence-LDA以及扩展了sentence-LDA的ASUM模型。ASUM( )同时对评论的主题以及评论的情感进行建模。它认为客户撰写评论的方式为:(以餐馆评论为例):- 首先决定餐馆评价的好坏概率分布,如:70%是满意的,30%是不满意的。
- 然后对每个情感给出其评价主题概率分布。如:满意的主题概率分布为:50%是服务,25%是食物,25% 是价格。
- 最后对每个句子,表达一个主题和一个情感。即:每个句子中所有的单词背后都是同一个主题,也是同一个情感。
ASUM文档生成过程:对每一个
主题-情感对(情感为 ,主题为 ),从
,主题为 ),从 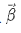 的狄利克雷分布随机采样,得到该主题和该情感下的单词分布: 。每个
的狄利克雷分布随机采样,得到该主题和该情感下的单词分布: 。每个主题-情感采样一次,一共采样 次。
次。其中 为情感的总数。
对每篇文档
 :
:对文档
 中的每个句子:
中的每个句子:
与
LDA模型不同,ASUM模型中的 参数是非对称的:如good,great不大可能会出现在负面情感中,bad,annoying不大可能出现在正面情感中。ASUM的吉布斯采样概率为:各参数的意义为:

ASUM得到的文档-情感概率分布为:文档的情感-主题分布为:
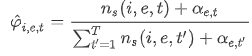
主题-单词概率分布为:
其中:

和
SLDA可以用于以下用途:利用
SLDA进行评论的主题抽取。利用
ASUM进行情感-主题的抽取。自适应的扩展特定主题下的情感词。
- 首先进行
情感-主题合并。以词的分布为向量,计算情感-主题的两两余弦相似度。如果结果超过一个阈值,则认为二者是相同的。 - 计算词的出现概率。如果一个单词在所有
情感-主题下都有高概率,则它是一个通用词;如果它仅仅在一个情感-主题下有高概率,则它是一个特定主题下的情感词。
- 首先进行
无监督情感分类。根据 中,各情感的分布来执行分类。
其中需要引入先验知识:
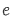 的取值是多少才代表正面情感。这需要观察
的取值是多少才代表正面情感。这需要观察情感-主题词的分布,由人工指定。

