
-
memorization:学到item或者feature共现关系,并基于历史数据中的这种相关性来推荐。基于
memorization的推荐通常更具有话题性,并且和用户已经发生行为的item直接关联。generalization:根据item或者feature的共现关系,探索过去从未发生或者很少发生的新特征组合。基于
generalization的推荐通常更具有多样性。
广义线性模型通常对特征执行
one-hot编码。如性别=男表示特征:如果用户是男性,则该特征为 1 。通过特征交叉可以有效的达到
memorization。如特征交叉AND(性别=男,曾经购买汽车=奇瑞QQ):当用户是男性、且曾经购买奇瑞QQ汽车时该交叉特征为 1。如果希望提升泛化能力,则可以提升特征的粒度。如:
AND(性别=男,曾经购买汽车=10万以下汽车)。这种方式的限制是无法推广到训练集中没有出现过的
query-item或者feature pair。
基于
embedding的模型(如FM或者DNN)为每个query和item学习一个低维的dense embedding向量,通过embedding向量来泛化到训练集中未见过的query-item feature pair,同时也缓解了特征工程的代价。但是当
query-item矩阵非常稀疏且矩阵的秩较高时(如:用户具有特定偏好,产品非常小众),很难学到有效的query/item的低维表达。此时大多数
query-item pair之间不应该存在任何交互,但是dense embedding仍然给出了非零的预测结果。这会导致严重的过拟合,并给出一些不怎么相关的推荐结果。在这种场景下,基于特征交叉的广义线性模型能够记住这些特定偏好或者小众产品的
exception rule。广义线性模型(称为
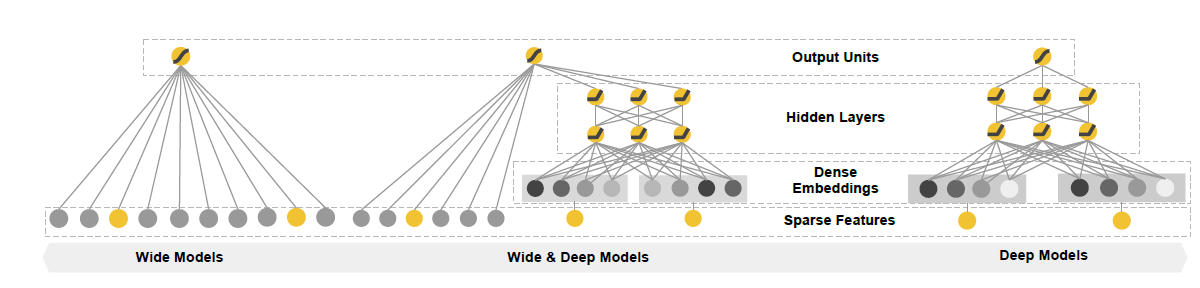
wide模型)可以通过大量交叉特征来记住特征交互feature interaction,即memorization。其优点是可解释性强,缺点是:为了提升泛化能力,需要人工执行大量的特征工程。深度神经网络模型(称为
deep模型)只需要执行较少的特征工程即可泛化到未出现的特征组合,即generalization。其优点是泛化能力强,缺点是容易陷入过拟合。论文
“Wide & Deep Learning for Recommender Systems”结合了wide模型和deep模型,同时实现了memorization和generalization。
一个典型的推荐系统整体架构如下图所示。推荐的流程如下:
当用户访问
app store时产生一个query,它包含用户特征(如用户画像)和上下文特征(如 当前时刻LBS信息、设备信息、页面信息)。检索
retrieval模块根据用户的query返回一组相关app组成的app list。检索算法可以综合利用机器学习模型和人工定义的规则,它用于将百万级别的
app集合降低到几百上千级别的候选 。精排
ranking模块对候选app list根据用户的行动(如:下载、购买)概率进行排名,返回概率最高的十几个或者几十个app组成的推荐结果。返回的推荐结果展示在用户界面,用户可以对这些
app执行各种操作(如:下载、购买)。这些操作行为,以及query, result app list都会被记录并发送到后台日志作为训练数据。
Wide & Deep模型主要用于ranking精排模块,它包含一个linear model:LM部分和一个neural network:NN部分。设模型的输入特征向量为
 是一个 维的特征向量(经过
是一个 维的特征向量(经过 one-hot),仅包含原始特征。 表示特征交叉转换函数, 包含转换后的特征。
表示特征交叉转换函数, 包含转换后的特征。NN部分:即右侧的deep子模型,它是一个DNN模型。输入层:为了缓解模型的输入大小,
DNN的所有离散特征的输入都是原始特征,而没有经过one-hot编码转换。第一层
embedding层:将高维稀疏的categorical特征转换为低维的embedding向量。论文中的embedding向量维度为 32 维。第二层特征拼接层:将所有的
embedding向量拼接成一个dense feature向量。论文中该向量维度为 1200维。后续每一层都是全连接层:

其中 为层的编号,
 为激活函数。
为激活函数。
模型联合了
wide和deep的输出:其中
 为
为 wide部分的权重, 为deep部分的权重, 为全局偏置。
为全局偏置。模型的损失函数为负的对数似然,并通过随机梯度下降来训练:
Wide&Deep模型与LM & DNN的ensemble集成模型不同。在集成模型中,每个子模型都是独立训练的,只有预测时才将二者结合在一起。
在
Wide&Deep模型中,每个子模型在训练期间就结合在一起,共同训练。在集成模型中,每个子模型必须足够大从而足够健壮,使得子模型集成之后整体的
accuracy等性能足够高。在
Wide&Deep模型中,每个子模型都可以比较小,尤其是wide部分只需要少量的特征交叉即可。
Wide&Deep模型的实现如下图所示。模型的Pipeline分为三个部分:数据生成
data generation阶段:此阶段把一段时间内的用户曝光数据生成训练样本,每个样本对应一次曝光,标签为用户是否产生行为(如:下载app)。在这个阶段执行两个特征工程:
离散的字符串特征(如
app name)映射成为整数ID,同时生成映射字典vocabulary。注意:对于出现次数低于指定阈值(如 10此)的字符串直接丢弃,这能够丢弃一些长尾的、罕见的字符串,降低字典规模。
-
首先将连续特征归一化到
0~1之间,它通过累积分布函数来归一化,计算特征的整体排名(1.0表示排名最高,0.0表示排名最低)其中
 为示性函数, 为总样本数量。
为示性函数, 为总样本数量。然后将
 映射到 分位。如映射到
映射到 分位。如映射到10分位时,假设 (即排名在最高的 5%),则映射为
(即排名在最高的 5%),则映射为 9这个等级。
模型训练
model training阶段:此阶段的输入为样本数据、字典数据、标签数据。wide部分的特征由:用户已经安装的app、给用户曝光的app的两个特征的交叉组成。每次有新的训练数据到达时,模型会利用该部分数据重新训练。
由于重新训练模型的代价太大,因此我们实现了一个
warm-starting系统:基于前一个模型的 和 参数来初始化当前模型的这两个参数。在模型部署到线上之前,还需要验证模型的质量。
模型使用
model serving阶段:训练并验证模型后,将模型部署到服务器上来提供预测服务。为满足
10ms量级的响应速度,采用多线程并行来优化性能。方法为:假设一个batch有500个候选app,- 先将其拆分为更小的一组
batch:如50个batch,每个batch有10个候选app。 - 每个子线程并行的执行推断
- 将所有子线程的推断结果收集在一起,拼接成整个
batch的推断结果并返回
- 先将其拆分为更小的一组

5.2 实验
模型从谷歌应用商店的
app下载量,以及serving性能这两方面来评估。我们执行三个星期的在线
A/B test,其中:- 对照组1:随机抽取
1%的用户,该部分用户采用旧的精排模型:只有wide部分的、采取大量特征交叉的LR模型。 - 对照组2:随机抽取
1%的用户,该部分用户采用DNN精排模型:只有deep部分的DNN模型。 - 实验组:随机抽取
1%的用户,该部分用户采用Wide&Deep精排模型。
另外我们还在一个离线的留出
holdout数据集上评估了这三个模型的离线AUC指标。最终结果如下表:在线
app下载量提升:Wide&Deep提升幅度较大,达到3.9%。事实上仅
deep模型就能提升2.9%,但是结合了wide和deep能进一步提升。离线
AUC提升:Wide&Deep稍微有所提升,但提升幅度不大。可能的原因:离线评估固定了曝光和
label,即:你给用户推荐的app list是固定的,用户是否安装的label也是固定的。这种假设实际上是有问题的,因为如果模型发生变化则推送给用户的
app list会有所变化,是否安装的label也会有所变化。这使得模型 --> 特征、label --> 模型相互依赖。而离线的数据集无法体现这种模型和数据的相互依赖性。在线
A/B test中,模型学习从用户最新的反馈中学习,然后推荐出新的app list。
- 对照组1:随机抽取
谷歌应用商店面临高流量,因此提供高吞吐量、低延迟的
model serving服务是一个挑战。在流量峰值,我们需要每秒为1000万个app打分。- 当使用单线程时,一个
batch的样本打分需要31ms。 - 当使用多线程并行时,一个
batch的样本拆分到多个更小的batch,最终打分需要 。

- 当使用单线程时,一个

