
-
论文
《GATED GRAPH SEQUENCE NEURAL NETWORKS》基于GNN模型进行修改,它使用门控循环单元gated recurrent units以及现代的优化技术,并扩展到序列输出的形式。这种模型被称作门控图序列神经网络Gated Graph Sequence Neural Networks:GGS-NNs。在
Graph数据结构上,GGS-NNs相比于单纯的基于序列的模型(如LSTM)具有有利的归纳偏置inductive biases。 在图上学习
representation有两种方式:- 学习输入图的
representation。这也是目前大多数模型的处理方式。 - 在生成一系列输出的过程中学习内部状态的
representation,其中的挑战在于:如何学习representation,它既能对已经生成的部分输出序列进行编码(如路径输出任务中,已经产生的路径),又能对后续待生成的部分输出序列进行编码(如路径输出任务中,剩余路径)。
- 学习输入图的
6.1.1 GNN回顾
定义图 ,其中
 为顶点集合、 为边集合。顶点
为顶点集合、 为边集合。顶点  , 边 。我们关注于有向图,因此
, 边 。我们关注于有向图,因此  代表有向边 ,但是我们很容易用这套框架处理无向边。
代表有向边 ,但是我们很容易用这套框架处理无向边。定义顶点
 的标签为 ,定义边
的标签为 ,定义边  的标签为 ,其中
的标签为 ,其中  为顶点标签的维度、 为边标签的维度。
为顶点标签的维度、 为边标签的维度。对给定顶点
,定义其状态向量为 。在原始
GNN论文中状态向量记作 ,为了和
,为了和 RNN保持一致,这里记作 。定义函数
 为顶点 的前序顶点集合,定义函数
为顶点 的前序顶点集合,定义函数  为顶点 的后序顶点集合,定义函数
为顶点 的后序顶点集合,定义函数  为顶点 的所有邻居顶点集合。
为顶点 的所有邻居顶点集合。定义函数
 表示所有包含顶点 的边(出边 + 入边)。
表示所有包含顶点 的边(出边 + 入边)。在原始
GNN论文中,仅考虑入边。即信息从邻居顶点流向顶点 。
GNN通过两个步骤来得到输出:- 首先通过转移函数
transition function得到每个顶点的representation。其中转移函数也被称作传播模型propagation model。 - 然后通过输出函数
output function得到每个顶点的输出 。 其中输出函数也被称作输出模型
。 其中输出函数也被称作输出模型 output model。
该系统是端到端可微的,因此可以利用基于梯度的优化算法来学习参数。
传播模型:我们通过一个迭代过程来传播顶点的状态。
顶点的初始状态 可以为任意值,然后每个顶点的状态可以根据以下方程来更新直到收敛,其中
 表示时间步:
表示时间步:其中
 为转移函数,它有若干个变种,包括:
为转移函数,它有若干个变种,包括:nonpositional form和posistional form、线性和非线性。 论文建议按照nonpositional form进行分解:其中
 可以为线性函数,或者为一个神经网络。当 为线性函数时, 为:
可以为线性函数,或者为一个神经网络。当 为线性函数时, 为:其中
 和矩阵 分别由两个前馈神经网络的输出来定义,这两个前馈神经网络的参数对应于
和矩阵 分别由两个前馈神经网络的输出来定义,这两个前馈神经网络的参数对应于 GNN的参数。输出模型:模型输出为
 。其中 可以为线性的,也可以使用神经网络;
。其中 可以为线性的,也可以使用神经网络;  为传播模型最后一次迭代的结果 。
为传播模型最后一次迭代的结果 。为处理
graph-level任务,GNN建议创建一个虚拟的超级顶点super node,该超级顶点通过特殊类型的边连接到所有其它顶点,因此可以使用node-level相同的方式来处理graph-level任务。GNN模型是通过Almeida-Pineda算法来训练的,该算法首先执行传播过程并收敛,然后基于收敛的状态来计算梯度。其优点是我们不需要存储传播过程的中间状态(只需要存储传播过程的最终状态)来计算梯度,缺点是必须限制参数从而使得传播过程是收缩映射。
转移函数是收缩映射是模型收敛的必要条件,这可能会限制模型的表达能力。当
为神经网络模型时,可以通过对网络参数的雅可比行列式的 范数施加约束来实现收缩映射的条件:
其中 表示图的个数,
 表示第 个图的顶点数量,
表示第 个图的顶点数量, 为第 个图、第
为第 个图、第  个顶点的监督信息, 为第
个顶点的监督信息, 为第  个图、第 个顶点的预测,
个图、第 个顶点的预测,  为罚项:
为罚项:超参数
 定义了针对转移函数的约束。
定义了针对转移函数的约束。事实上一个收缩映射很难在图上进行长距离的信息传播。
考虑一个环形图,图有 个顶点,这些顶点首位相连。假设每个顶点的隐状态的维度为
1,即隐状态为标量。假设 为线性函数。为简化讨论,我们忽略了所有的顶点标签信息向量、边标签信息向量,并且只考虑入边而未考虑出边。在每个时间步 ,顶点
的隐单元为:其中
 为传播模型的参数。
为传播模型的参数。考虑到环形结构,我们认为: 时有
 。
。令 ,令:

则有: 。记
 ,则 必须为收缩映射,则存在
,则 必须为收缩映射,则存在  使得对于任意的 ,满足:
使得对于任意的 ,满足:
即:
如果选择
 ,选择 (即除了位置
,选择 (即除了位置  为
为1、其它位置为零) ,则有 。扩展
 ,则有:
,则有:考虑到
 ,这意味着从顶点 传播的信息以指数型速度
,这意味着从顶点 传播的信息以指数型速度  衰减,其中 为顶点 到顶点 的距离(这里 是 的上游顶点)。因此
衰减,其中 为顶点 到顶点 的距离(这里 是 的上游顶点)。因此 GNN无法在图上进行长距离的信息传播。事实上,当
为非线性函数时,收缩映射也很难在图上进行长距离的信息传播。令其中
 为非线性激活函数。则有 ,
为非线性激活函数。则有 ,  为一个收缩映射。则存在 使得对于任意的
为一个收缩映射。则存在 使得对于任意的  ,满足:
,满足:这意味着函数
 的雅可比矩阵的每一项都必须满足:
的雅可比矩阵的每一项都必须满足:证明:考虑两个向量
 ,其中 :
,其中 :则有
 ,则有:
,则有:其中
 为 的第 个分量。当 时, 左侧等于
为 的第 个分量。当 时, 左侧等于  ,因此得到结论 。
,因此得到结论 。当
 时,有 。考虑到图为环状结构,因此对于
时,有 。考虑到图为环状结构,因此对于  的顶点有 。
的顶点有 。
现在考虑 如何影响
 。考虑链式法则以及图的环状结构,则有:
。考虑链式法则以及图的环状结构,则有:当
 时,偏导数 随着 的增加指数级降低到
时,偏导数 随着 的增加指数级降低到0。这意味着一个顶点对另一个顶点的影响将呈指数级衰减,因此GNN无法在图上进行长距离的信息传播。
6.1.2 GG-NN模型
门控图神经网络
Gated Graph Neural Networks:GG-NNs对GNN进行修改,采用了门控循环单元GRU,并对固定的 个时间步进行循环展开。GG-NNs使用基于时间的反向传播BPTT算法来计算梯度。传统
GNN模型只能给出非序列输出,而GG-NNs可以给出序列输出。本节给出的
GG-NNs模型只支持非序列输出,但是GG-NNs的变种GGS-NNs支持序列输出。相比
Almeida-Pineda算法,GG-NNs需要更多内存,但是后者不需要约束参数以保证收缩映射。
在
GNN中顶点状态的初始化值没有意义,因为不动点理论可以确保不动点独立于初始化值。但是在GG-NNs模型中不再如此,顶点的初始化状态可以作为额外的输入。因此顶点的初始化状态可以视为顶点的标签信息的一种。为了区分顶点的初始化状态和其它类型的顶点标签信息,我们称初始化状态为顶点的注解
node annotation,以向量 来表示。
来表示。注解向量的示例:对于给定的图,我们希望预测是否存在从顶点 到顶点
的路径。该任务存在任务相关的两个顶点 ,因此我们定义注解向量为:

注解向量使得顶点 被标记为任务的第一个输入参数,顶点
被标记为任务的第二个输入参数。我们通过 来初始化状态向量  :
:即:
的前面两维为 、后面的维度填充为零。传播模型很容易学得将顶点
 的注解传播到任何 可达的顶点。如,通过设置传播矩阵为:所有存在后向边的位置都为
的注解传播到任何 可达的顶点。如,通过设置传播矩阵为:所有存在后向边的位置都为1。这将使得 的第一维沿着后向边进行复制,使得从顶点 可达的所有顶点的
的第一维沿着后向边进行复制,使得从顶点 可达的所有顶点的  的第一维均为
的第一维均为1。最终查看顶点 的状态向量前两维是否为
[1,1]即可判断从 是否可达顶点 。传播模型:
初始化状态向量:
 ,其中 为状态向量的维度。这一步将顶点的注解信息拷贝到状态向量的前几个维度。
,其中 为状态向量的维度。这一步将顶点的注解信息拷贝到状态向量的前几个维度。信息传递:
 ,它包含所有方向的边的激活值。
,它包含所有方向的边的激活值。如下图所示
(a)表示一个图,颜色表示不同的边类型(类型B和类型C);(b)表示展开的一个计算步;(c)表示矩阵 , 表示 的反向边,采用不同的参数。
表示 的反向边,采用不同的参数。 对应于图中的边,它由 和
对应于图中的边,它由 和  组成,其参数由边的方向和类型决定。通常它们都是稀疏矩阵。
组成,其参数由边的方向和类型决定。通常它们都是稀疏矩阵。由
 对应于顶点 的两列组成;
对应于顶点 的两列组成; 。
。GRU更新状态:
这里采用类似
GRU的更新机制,基于顶点的历史状态向量和所有边的激活值来更新当前状态。 为更新门, 为复位门, 为
为复位门, 为 sigmoid函数, 为逐元素乘积。
为逐元素乘积。我们最初使用普通的
RNN来进行状态更新,但是初步实验结论表明:GRU形式的状态更新效果更好。
输出模型:我们可以给出最终时间步的输出。
node-level输出: 。然后可以对 应用一个 softmax函数来得到每个顶点在各类别的得分。graph-level输出:定义graph-level的representation向量为:其中:
 都是神经网络,它们拼接 和 作为输入, 输出一个实值向量。
都是神经网络,它们拼接 和 作为输入, 输出一个实值向量。- 函数也可以替换为恒等映射。
6.1.3 GGS-NNs 模型
门控图序列神经网络
Gated Graph Sequence Neural Networks :GGS-NNs使用若干个GG-NNs网络依次作用从而生成序列输出 。
。在第 个输出:
定义所有顶点的注解向量组成矩阵
 ,其中 为注解向量的维度。
,其中 为注解向量的维度。定义所有顶点的输出向量组成矩阵
 ,其中 为输出向量的维度。
,其中 为输出向量的维度。我们使用两个
GG-NNs网络 和 ,其中 用于从 中预测
和 ,其中 用于从 中预测  、 用于从
、 用于从  中预测 。
中预测 。 可以视作一个“状态”,它从输出步 转移到输出步
可以视作一个“状态”,它从输出步 转移到输出步  。
。- 每个 和
 均包含各自的传播模型和输出模型。我们定义第 个输出步的第 个时间步的状态矩阵分别为:
均包含各自的传播模型和输出模型。我们定义第 个输出步的第 个时间步的状态矩阵分别为:
- 每个 和
其中  为各自传播模型的状态向量的维度。如前所述, 可以通过 通过填充零得到,因此有:,记作
为各自传播模型的状态向量的维度。如前所述, 可以通过 通过填充零得到,因此有:,记作  。
。
我们也可以选择 和
共享同一个传播模型,然后使用不同的输出模型。这种方式的训练速度更快,推断速度更快,并且大多数适合能够获得原始模型相差无几的性能。但是如果 和 的传播行为不同,则这种变体难以适应。的输出模型称为顶点
annotation output模型,它用于从 中预测 。该模型在每个顶点上利用神经网络独立的预测:
中预测 。该模型在每个顶点上利用神经网络独立的预测:其中
 为神经网络, 和
为神经网络, 和  的拼接作为网络输入, 为
的拼接作为网络输入, 为sigmoid函数。
整个网络的结构如下图所示,如前所述有
 ,记作 。
,记作 。
GGS-NNs的训练有两种方式:仅仅给定 ,然后执行端到端的模型训练。这种方式更为通用。
我们将
 视为网络的隐变量,然后通过反向传播算法来联合训练。
视为网络的隐变量,然后通过反向传播算法来联合训练。指定所有的中间注解向量: 。当我们已知关于中间注解向量的信息时,这种方式可以提高性能。
考虑一个图的序列输出任务,其中每个输出都仅仅是关于图的一个部分的预测。为了确保图的每个部分有且仅被预测一次,我们需要记录哪些顶点已经被预测过。我们为每个顶点指定一个
bit作为注解,该比特表明顶点到目前为止是否已经被“解释”过。因此我们可以通过一组注解来捕获输出过程的进度。此时,我们可以将尚未“解释”的顶点的注解作为模型的额外输入。因此我们的
GGS-NNs模型中,GG-NNs和给定的注解是条件独立的。- 训练期间序列输出任务将被分解为单个输出任务,并作为独立的
GG-NNs来训练。 - 测试期间,第
 个输出得到的注解(已“解释”过的顶点)当作为第 个输出的网络输入。
个输出得到的注解(已“解释”过的顶点)当作为第 个输出的网络输入。
- 训练期间序列输出任务将被分解为单个输出任务,并作为独立的
6.2 application
6.2.1 bAbI 任务
bAbI任务旨在测试AI系统应该具备的推理能力。在bAbI suite中有20个任务来测试基本的推理形式,包括演绎、归纳、计数和路径查找。我们定义了一个基本的转换过程
transformation procedure从而将bAbI任务映射成GG-NNs或者GGS-NNs任务。我们使用已发布的
bAbI代码中的--symbolic选项从而获取仅涉及entity实体之间一系列关系的story故事,然后我们将每个实体映射为图上的一个顶点、每个关系映射为图上的一条边、每个story被映射为一张图。Question问题在数据中以eval来标记,每个问题由问题类型(如)、问题参数(如一个或者多个顶点)组成。我们将问题参数转换为初始的顶点注解,第 个参数顶点注解向量的第 位设置为 1。
问题的监督标签为
true。bAbI任务15(Basic Deduction任务)转换的符号数据集symbolic dataset的一个示例:- 前
8行描述了事实fact,GG-NNs将基于这些事实来构建Graph。每个大写字母代表顶点,is和has_fear代表了边的label(也可以理解为边的类型)。 - 最后
4行给出了四个问题,has_fear代表了问题类型。 - 每个问题都有一个输入参数,如
eval B has_fear H中,顶点B为输入参数。顶点B的初始注解为标量1(只有一个元素的向量就是标量)、其它顶点的初始注解标量为0。
- 前
某些任务具有多个问题类型,如
bAbI任务4具有四种问题类型:e,s,w,n。对于这类任务,我们为每个类型的任务独立训练一个GG-NNs模型。在任何实验中,我们都不会使用很强的监督标签,也不会给
GGS-NNs任何中间注解信息。
我们的转换方式虽然简单,但是这种转换并不能保留有关
story的所有信息,如转换过程丢失了输入的时间顺序;这种转换也难以处理三阶或者更高阶的关系,如昨天 John 去了花园则难以映射为一条简单的边。注意:将一般化的自然语言映射到符号是一项艰巨的任务,因此我们无法采取这种简单的映射方式来处理任意的自然语言。
即使是采取这种简单的转化,我们仍然可以格式化描述各种
bAbI任务,包括任务19(路径查找任务)。我们提供的baseline表明:这种符号化方式无助于RNN/LSTM解决问题,但是GGS-NNs可以基于这种方式以少量的训练样本来解决问题。bAbI任务19为路径查找path-finding任务,该任务几乎是最难的任务。其符号化的数据集中的一个示例:E s AB n CE w FB w Eeval path B A w,s
- 开始的
4行描述了四种类型的边,s,n,w,e分别表示东,南,西,北。在这个例子中,e没有出现。 - 最后一行表示一个路径查找问题:
path表示问题类型为路径查找;B, A为问题参数;w,s为答案序列,该序列是一个方向序列。该答案表示:从B先向西(到达顶点E)、再向南可以达到顶点A。
我们还设计了两个新的、类似于
bAbI的任务,这些任务涉及到图上输出一个序列。这两个任务包括:最短路径问题和欧拉回路问题。最短路径问题需要找出图中两个点之间的最短路径,路径以顶点的序列来表示。
我们首先生成一个随机图并产生一个
story,然后我们随机选择两个顶点A和B,任务是找出顶点A和B之间的最短路径。为了简化任务,我们限制了数据集生成过程:顶点
A和B之间存在唯一的最短路径,并且该路径长度至少为2(即A和B的最短路径至少存在一个中间结点)。如果图中的一个路径恰好包括每条边一次,则该路径称作欧拉路径。如果一个回路是欧拉路径,则该回路称作欧拉回路。
对于欧拉回路问题,我们首先生成一个随机的、
2-regular连接图,以及一个独立的随机干扰图。然后我们随机选择两个顶点A和B启动回路,任务是找出从A到B的回路。为了增加任务难度,这里添加了干扰图,这也使得输出的回路不是严格的“欧拉回路”。
正则图是每个顶点的
degree都相同的无向简单图,2-regular正则图表示每个顶点都有两条边。
对于
RNN和LSTM这两个baseline,我们将符号数据集转换为token序列:n6 e1 n1 eol n6 e1 n5 eol n1 e1 n2 eol n4 e1 n5 eol n3 e1 n4eol n3 e1 n5 eol n6 e1 n4 eol q1 n6 n2 ans 1
其中
n<id>表示顶点、e<id>表示边、q<id>表示问题类型。额外的token中,eol表示一行的结束end-of-line、ans代表答案answer、最后一个数字1代表监督的类别标签。我们添加
ans从而使得RNN/LSTM能够访问数据集的完整信息。训练配置:
本节中的所有任务,我们生成
1000个训练样本(其中有50个用于验证,只有950个用于训练)、1000个测试样本。在评估模型时,对于单个样本包含多个问题的情况,我们单独评估每个问题。
我们首先以
50个训练样本来训练各个模型,然后逐渐增加训练样本数量为100、250、500、950(最多950个训练样本)。由于
bAbI任务成功的标准是测试准确率在95%及其以上,我们对于每一个模型报告了测试准确率达到95%所需要的最少训练样本,以及该数量的训练样本能够达到的测试准确率。在所有任务中,我们展开传播过程为
5个时间步。对于
bAbI任务4、15、16、18、19,我们的GG-NNs模型的顶点状态向量 的维度分别为4、5、6、3、6。对于最短路径和欧拉回路任务,我们的
GG-NNs模型的顶点状态向量 维度为
维度为 20。对于所有的
GGS-NNs,我们简单的令 共享同一个传播模型。所有模型都基于
Adam优化器训练足够长的时间,并使用验证集来选择最佳模型。
单输出任务:
bAbI的任务(Tow Argument Relations)、任务15(Basic Deduction)、任务16(Basic Induction)、任务18(Size Reasoning) 这四个任务都是单输出任务。对于任务
4、15、16,我们使用node-level GG-NNs;对于任务18我们使用graph-level GG-NNs。所有
GG-NNs模型包含少于600个参数。我们在符号化数据集上训练
RNN和LSTM模型作为baseline。RNN和LSTM使用50维的embedding层和50维的隐层,它们在序列末尾给出单个预测输出,并将输出视为分类问题。这两个模型的损失函数为交叉熵,它们分别包含大约
5k个参数(RNN)和30k个参数 (LSTM)。
预测结果如下表所示。对于所有任务,
GG-NNs仅需要50个训练样本即可完美的预测(测试准确率100%);而RNN/LSTM要么需要更多训练样本(任务4)、要么无法解决问题(任务15、16、18)。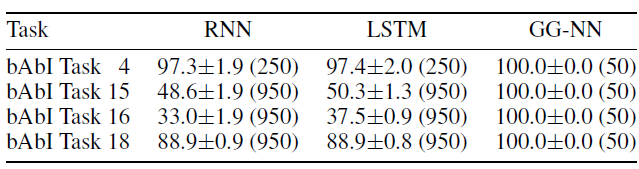
对于任务
4,我们进一步考察训练数据量变化时,RNN/LSTM模型的性能。可以看到,尽管RNN/LSTM也能够几乎完美的解决任务,但是GG-NNs可以使用更少的数据达到100%的测试准确率。序列输出任务:所有
bAbI任务中,任务19(路径查找任务)可以任务是最难的任务。我们以符号数据集的形式应用GGS-NNs模型,每个输出序列的末尾添加一个额外的end标签。在测试时,网络会一直预测直到预测到end标签为止。另外,我们还对比了最短路径任务和欧拉回路任务。
下表给出了任务的预测结果。可以看到
RNN/LSTM都无法完成任务,GGS-NNs可以顺利完成任务。另外GGS-NNs仅仅利用50个训练样本就可以达到比RNN/LSTM更好的测试准确率。
为什么
RNN/LSTM相对于单输出任务,在序列输出任务上表现很差?欧拉回路任务是
RNN/LSTM最失败的任务,该任务的典型训练样本如下:3 connected-to 77 connected-to 31 connected-to 22 connected-to 15 connected-to 77 connected-to 50 connected-to 44 connected-to 01 connected-to 00 connected-to 18 connected-to 66 connected-to 83 connected-to 66 connected-to 35 connected-to 88 connected-to 54 connected-to 22 connected-to 4eval eulerian-circuit 5 7 5,7,3,6,8
这个图中有两个回路
3-7-5-8-6和1-2-4-0,其中3-7-5-8-6是目标回路,而1-2-4-0是一个更小的干扰图。为了对称性,所有边都出现两次,两个方向各一次。对于
RNN/LSTM,上述符号转换为token序列:n4 e1 n8 eol n8 e1 n4 eol n2 e1 n3 eol n3 e1 n2 eol n6 e1 n8 eoln8 e1 n6 eol n1 e1 n5 eol n5 e1 n1 eol n2 e1 n1 eol n1 e1 n2 eoln9 e1 n7 eol n7 e1 n9 eol n4 e1 n7 eol n7 e1 n4 eol n6 e1 n9 eoln9 e1 n6 eol n5 e1 n3 eol n3 e1 n5 eol q1 n6 n8 ans 6 8 4 7 9
注意:这里的顶点
ID和原始符号数据集中的顶点ID不同。RNN/LSTM读取整个序列,并在读取到ans这个token的时候开始预测第一个输出。然后在每一个预测步,使用ans作为输入,目标顶点ID(视为类别标签) 作为输出。这里每个预测步的输出并不会作为下一个预测步的输入。我们的
GGS-NNs模型使用相同的配置,其中每个预测步的输出也不会作为下一个预测步的输入,仅有当前预测步的注解 延续到下一个预测步,因此和RNN/LSTM的比较仍然是公平的。这使得我们的GGS-NNs有能力得到前一个预测步的信息。一种改进方式是:在
RNN/LSTM/GGS-NNs中,每个预测步可以利用前一个预测步的结果。这个典型的样本有
80个token,因此我们看到RNN/LSTM必须处理很长的输入序列。如第三个预测步需要用到序列头部的第一条边3-7,这需要RNN/LSTM能够保持长程记忆。RNN中保持长程记忆具有挑战性,LSTM在这方面比RNN更好但是仍然无法完全解决问题。该任务的另一个挑战是:输出序列出现的顺序和输入序列不同。实际上输入数据并没有顺序结构,即使边是随机排列的,目标顶点的输出顺序也不应该改变。
bAbI任务19路径查找、最短路径任务也是如此。GGS-NNs擅长处理此类“静态”数据,而RNN/LSTM则不然。实际上RNN/LSTM更擅长处理动态的时间序列。如何将GGS-NNs应用于动态时间序列,则是将来的工作。
6.2.2 讨论
思考
GG-NNs正在学习什么是有启发性的。为此我们观察如何通过逻辑公式解决bAbI任务15。为此考虑回答下面的问题:要进行逻辑推理,我们不仅需要对 `story 里存在的事实进行逻辑编码,还需要将背景知识编码作为推理规则。如:
 。
。我们对任务的编码简化了将
story解析为Graph的过程,但是它并不提供任何背景知识。因此可以将GG-NNs模型视为学习背景知识的方法,并将结果存储在神经网络权重中。当前的
GG-NNs必须在读取所有fact事实之后才能回答问题,这意味着网络必须尝试得出所见事实的所有后果,并将所有相关信息存储到其顶点的状态中。这可能并不是一个理想的形式,最好将问题作为初始输入,然后动态的得到回答问题所需要的事实。

