
-
系统整体框架如图所示。
Probalistic Feature Inclusion:概率性特征引入模块,主要用于降低特征数量来优化内存。Parallelized Model Training:多模型并行训练模块,主要用于超参数选择中,提高多模型并行训练的效率。Calibration:模型校准模块,主要用于对校准模型的系统性预测偏差。Progressive Validation Metrics:模型性能分析模块,主要用于分析模型在验证集上的性能。Model Serving Replicas:模型部署模块,主要用于部署模型到线上。
6.1.1 稀疏解
在2013年左右,大多数在线学习框架使用逻辑回归模型并采用在线梯度下降
Oneline gradient descent:OGD算法来训练。设样本
 ,其标记为 ;模型参数为
,其标记为 ;模型参数为  。则:
。则:逻辑回归预测的点击概率为:
交叉熵损失函数为:

损失函数的梯度为:
当采用
OGD时,设第 轮迭代的样本为 ,模型参数为
轮迭代的样本为 ,模型参数为  ,则有:
,则有:在线训练算法需要关注三个方面的因素:
训练速度快。如果训练速度太慢,无法保证在线训练的实时性。
参数稀疏性。模型参数稀疏,即大量的参数为零。这带来两个好处:
- 内存代价低,因为只需要存储非零的参数值。
- 推断时,计算速度快,因为只需要计算参数非零对应的特征。
- 模型表现好。如果模型预测能力严重下降,则没有应用价值。
OGD算法的训练速度很快,但是它并不能产生稀疏解。由于随机梯度下降中采用的梯度不再是真实梯度的方向,因此即使增加了L1正则化项也无法得到稀疏解。FOBOS、梯度截断等方法能够产生稀疏解,但是它们降低了模型的预测能力。RDA在模型的预测能力和稀疏解之间取得平衡。Follow The (Proximally) Regularized Leader: FTRL既取得稀疏解,又能保证模型的预测能力。
下表中,
aucloss = 1 - auc。
记参数的梯度为 。设第
轮迭代的参数梯度为 ,其第  维分量为 。
维分量为 。在
OGD中,参数更新方程为:
6.1.2 特征优化
在超高维度领域(如:计算广告、推荐、搜索)中,特征规模可以达到上亿甚至百亿。
事实上,绝大多数特征都是非常罕见的。论文提到:谷歌的一些模型中,在数十亿样本中约一半的特征仅仅出现一次。
而且,这些罕见特征永远不会有任何实际应用价值。因为它出现的频次极为稀疏,没有任何统计意义。
一种简单的操作是将这些罕见特征剔除。问题是:我们事先并不知道有哪些特征是罕见特征。
可以统计样本中的特征,当特征出现次数低于指定阈值 次(如:3次)时,判定为罕见特征。
- 这种操作需要读取全部数据(数十亿级),并进行特征统计。对于在线训练,这种操作的代价较大。
- 如果直接剔除罕见特征,我们永远无法获知这种简单丢弃对于模型预测能力带来的影响。因为这些罕见特征从未在模型中出现过。
论文提出
Probabilistic Feature Includsion:当特征首次出现时,以一定的概率导入。这实现了罕见特征预处理的效果,但是避免了其缺陷。有两种导入方式:
泊松导入
Poisson Inclusion:当遇到一个新特征时,以概率 添加到模型中。
添加到模型中。- 一旦添加了一个新特征,我们在随后步骤中更新其统计计数、更新其
OGD系数。 - 任何新特征被添加到模型之前,期望看到特征出现的次数为 。
- 一旦添加了一个新特征,我们在随后步骤中更新其统计计数、更新其
Bloom Filter Inclusion:使用布隆过滤器来检测一个特征首次出现了 次。一旦发现,则将该特征添加到模型中。
次。一旦发现,则将该特征添加到模型中。该方法也是概率性的,因为布隆过滤器可能会误报。
两种方式的实验结果如下。可以看到:二者都可以降低模型大小,但是
Bloom Filter Inclusion在模型大小和模型预测能力下降之间取得平衡。
6.1.3 固定精度浮点数
通常我们用32位或者64位浮点数来存储模型参数。实际中发现:几乎所有的参数取值都在
[-2, +2]之间。同时,分析表明:对模型参数取如此高的精度完全没有必要。论文抛弃了32位/64位浮点数,采用 16 位固定精度的
q2.13格式来表示模型参数:1个bit表示正负、2个bit表示整数部分、13 个bit表示小数部分。采用16位浮点数带来的精度下降会导致
OGD过程中产生累积舍入误差。事实上在使用32位浮点数(而不是64位浮点数)时,我们也能够观察到舍入误差。
一个简单的随机舍入策略可以缓解该问题:

其中:
- 为原始的参数。
 为引入随机舍入策略调整后的参数,它以
为引入随机舍入策略调整后的参数,它以 q2.13格式存储。- 为一个随机数,它从
0~1均匀分布随机采样。
最终在没有损失模型预测能力的情况下,相比于64位双精度浮点数,采用
q2.13精度之后模型大小降低了 75%。
6.1.4 多模型并行训练
有时候我们需要训练多个模型,这些模型采用相同的算法但是不同的超参数来训练,这些模型称作变种模型。最后选择最佳的超参数及对应的模型。
一个简单的方式是:先用给定的算法训练好一个模型,然后用该模型作为变种模型的初始化点来训练变种模型。
这种方式比较简单,容易实现。但是缺点是:无法处理特征裁剪等改变模型结构的超参数调整。
实际上有一些数据可以在多个模型之间共享,如:训练样本。另一些数据无法在多个模型之间共享,如:每个模型的参数值。
我们可以在同一张表中存储每个模型的参数值,然后在每次迭代中同时更新所有模型的参数。这使得我们可以同时并行训练多个模型。
- 对于被裁剪特征的模型,对应参数表的位置恒为0。 这是通过设定该模型该维度的学习率为 0 来实现的。
- 一些通用的计数(如:特征索引、特征计数) 可以在多个模型之间共享,从而降低了大量内存。
- 通过这种方式不仅节省了内存,还节省了网络带宽(因为每个样本只需要读取一次)
更进一步的,我们可以为每个维度仅存储一个参数,而不是为维度在每个模型上存储一个参数。
此时该参数由包含该特征的所有变种模型共享,称作 。
设维度
 由所有变种模型共享,则训练期间:
由所有变种模型共享,则训练期间:-
其中
 为模型数量, 为所有模型在特征 上共享的参数, 表示模型
为模型数量, 为所有模型在特征 上共享的参数, 表示模型  的具体参数。
的具体参数。 计算最新的共享参数值:
实验结果显示:这种方式和上一点提到方法的模型预测能力几乎相同,但是这里的参数存储量降低了一个量级。
-
6.2 维度独立的学习率
如果某些特征的数据较多,则它应该学习速度快一点,因此需要给它一个较快的学习率衰减;如果某些特征的数据较少,则它应该学习速度慢一点,因此需要给它一个较慢的学习率衰减。
因此定义学习率:

其中 为超参数。
 是为了保证初始阶段的学习率不会太高,其取值通常选择为 1 。
是为了保证初始阶段的学习率不会太高,其取值通常选择为 1 。- 取值由具体的数据集和特征来决定,变化很大。
 通过超参数搜索来获取最佳的值,其中重点搜索 。因为算法对
通过超参数搜索来获取最佳的值,其中重点搜索 。因为算法对  取值比较敏感,而对 取值不敏感。
取值比较敏感,而对 取值不敏感。
通过实验表明:相较于全局学习率,基于维度的学习率可以将
aucloss降低11.2%。为计算每个维度的学习率我们需要计算梯度的累积平方。
假设特征
出现时,点击事件和不点击事件是相互独立的(虽然实际上很难成立,但是不影响下面的推导过程)。设特征 出现时,有
 次点击、 次未点击。则点击概率为:
次点击、 次未点击。则点击概率为:
设我们采用逻辑回归模型。则有梯度:
考虑到特征
出现,即: ,则有:样本
 点击时,梯度:
点击时,梯度:样本
未点击时,梯度:
则维度
的累积梯度平方为:其中第二步是假设:每次点击的概率
 都是相同的,等于 。
都是相同的,等于 。因此可以基于每个特征上发生的点击/不点击计数来近似梯度的累积平方,从而调整学习率。
允许这样做的原因:学习率是模型的超参数,其取值不必非常精确。
实验表明:这种方式得到的学习率,与采用梯度平方和得到的学习率,二者表现相当。
在多模型并行训练中,由于所有变种模型都具有相同的特征点击/不点击计数,因此存储
 的成本被摊销,总的存储成本较低。
的成本被摊销,总的存储成本较低。
在典型的推荐、搜索等场景中,点击率
CTR通常远低于 50%。这意味着正样本非常少。因此,正样本在CTR预估任务的学习中更具有价值。因此我们可以通过负降采样来显著减少训练集大小,同时保证对模型预测能力的影响降到最低。
- 所有正类样本被保留。
负降采样会导致模型产生预测偏差。这种偏差可以通过为每个样本赋予一个权重来解决:
- 正样本权重为
1 - 负样本权重为
这种权重放大了每个样本的损失,因此也同步地放大了梯度。
实验表明:即使是非常大比例的负降采样(
 值非常小),对最终模型的准确率的影响也是微乎其微的。而且和具体的 值无关。
值非常小),对最终模型的准确率的影响也是微乎其微的。而且和具体的 值无关。- 正样本权重为
6.4 模型评估
虽然可以直接利用实时流量来评估模型效果,但是这种评估的代价太大:在实时流量中上新模型可能会降低这些流量的收入,因为新模型的效果在评估之前是未知的,可能更好,但是大多数情况下是更坏。
可以通过历史日志来评估模型效果。由于不同的评估指标衡量了模型在不同方面的能力,因此我们评估了一组指标:
aucloss(即:1-auc)、logloss、平方误差。论文使用
progressive validation渐进式验证(也称为在线损失online loss),而未采用交叉验证。假设当前待学习的样本为
 , 为了学习该样本,
, 为了学习该样本,oneline learning模型会首先预测该样本,得到预测值 。然后基于预测值计算损失 和参数梯度 。最后根据参数梯度来更新参数。
和参数梯度 。最后根据参数梯度来更新参数。在这个过程中,我们可以很容易的将样本的预测值
记录下来供后续的模型评估。我们每个小时汇总一次,得到该小时内每个样本的真实值、预测值。基于这些数据得到小时级别的模型评估指标。
因此可以得到随时间推进的模型能力变化趋势。
这种方式中,每个样本都被用来训练,同时每个样本也被用来预测:训练完 来预测
 、训练完 来预测
、训练完 来预测  、…
、…这使得我们可以将
100%的数据用于训练和验证。相比较于传统的交叉验证只有部分数据用于验证,这里的验证集更大,得到的验证结果也更具有统计意义。这很重要,因为某些性能的改进可能需要在大规模的验证集上评估才有意义(如:改进可能很小,比如千分之五),置信度才比较高。
用绝对值来评估模型能力可能会产生误导。
假如某个场景点击率是
50%,另一个场景点击率是2%。事实上前者的logloss的绝对值可能会超过后者。因为logloss及其它指标可能会根据问题的难度(即贝叶斯风险)而变化。这个问题非常重要。因为
CTR会根据不同国家/地区,以及query而不同。query在一天中的不同时段的分布不同,因此评估指标的均值会在一天之内发生变化。因此我们更关注相对变化:模型的评估指标相对于
baseline的变化。根据论文的经验,随着时间的推进,相对变化会更加稳定。需要注意的是:我们必须在同一批数据上产生的同一个指标才有比较意义。
如:
A模型在某个时间段上得到的模型指标,和B模型在另一个时间段上得到的模型指标之间不可比较。因为A模型和B模型的评估数据都不同。大规模机器学习的一个隐藏陷阱是:统计指标可能受到数据中某些属性分布的影响。
如:给定一个验证集,模型
A的准确率比模型B更高。很有可能该验证集中 “女性” 用户非常多,而模型A对于 “女性” 用户的预测比模型B更准。因此我们不仅要给出模型在整体验证集上的评估指标,还要再验证集数据的每个分区上给出评估指标。如:模型在每个国家上的评估指标、模型在每个性别上的评估指标、模型在每个主题上的评估指标 ….
在很多应用场景中,我们不仅要预估
CTR,还要衡量预估结果的置信度。通常采用置信区间来评估不确定性,但是在这里不适用。
-
而
FTRL模型是在线学习,不再满足独立同分布IID的样本假设,因此甚至无法定义收敛性。并且模型是经过正则化的。 标准的方法需要求解一个 矩阵的逆,这里
n的规模达到数十亿甚至百亿,因此无法计算。
-
论文提出不确定性得分来评估结果的置信度。
假设我们对样本进行归一化,使得样本每个特征的取值都归一化到 1 以内。即: 。
对于逻辑回归模型,损失函数的梯度为:
 。 考虑到 因此有:
。 考虑到 因此有:  。
。当采用维度独立的学习率时,有: 。
因此给定样本
 ,其预估的不确定性为:
,其预估的不确定性为:因此对于样本
,定义模型预测的不确定性得分为:其物理意义是:由于学习的不充分导致预测结果的不确定性。因为一旦学习充分,则模型参数
 非常稳定,在前后两次迭代之间的变化几乎为零。
非常稳定,在前后两次迭代之间的变化几乎为零。这种方式定义的置信度指标计算非常方便。
为验证这种置信度指标的有效性,论文执行以下实验:
首先在真实数据集 上训练模型
A然后丢弃真实数据的标记
 ,用模型
,用模型 A的预测结果 来代替 ,从而产生了替代数据集 在数据集
 上用
上用 FTRL算法训练模型B。对于样本 ,假设模型
A的预测结果为p,模型B的预测结果为 。
。则得分误差为:
其中
 是 的反函数,它根据预测概率计算得分
是 的反函数,它根据预测概率计算得分  。
。的物理意义为:由于标记噪声的引入,导致模型预测的波动范围。
最后计算
 ,观察该指标是否和得分误差 相符。
,观察该指标是否和得分误差 相符。
实验结果表明:
 和得分误差 比较比配,而且置信度指标计算量非常小。
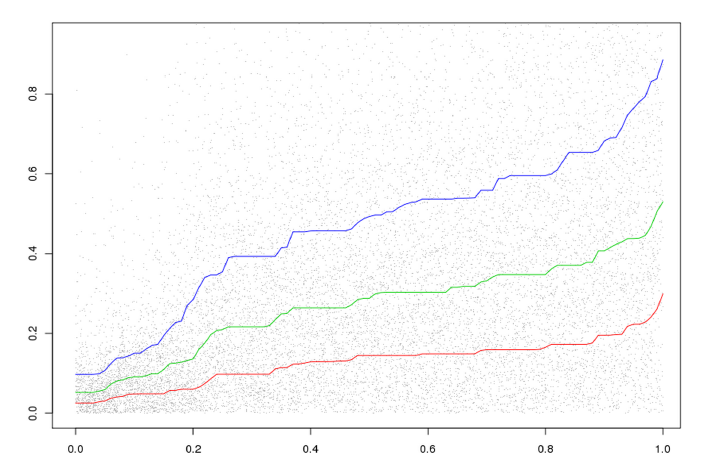
和得分误差 比较比配,而且置信度指标计算量非常小。如下图所示:
横坐标表示每一个样本的得分误差
 ,纵坐标表示每个样本的不确定性分 。
,纵坐标表示每个样本的不确定性分 。其中每一种得分都归一化成
0~1之间。曲线分别代表:
25%, 50%, 75%百分位的得分误差对应的样本连接而成的曲线。可以看到:得分误差
和不确定性分 成正向关系:得分误差越大,不确定性分越大。
6.6 模型校准
很多因素可能会导致模型产生系统性偏差,如:模型的前提假设不成立、优化算法本身的缺陷、训练或预测期间无法获取某些重要特征。
为解决该问题,论文提出模型校准模块来校准预测的
CTR,使得预测CTR和经验CTR适配。假设模型在数据集 上的平均预测
CTR为 ,数据集 的经验 CTR为 ,其中 。预测偏差
,其中 。预测偏差 bias为 。
。模型校准是提供一个校准函数 ,使得校准后的平均预测
CTR尽可能接近 。一个简单方法是基于泊松回归来矫正。定义:
其中
 都是待学习的参数,通过泊松回归在数据集 上学习。
都是待学习的参数,通过泊松回归在数据集 上学习。一个通用的方法是:利用分段线性函数来拟合
bias曲线,其中必须满足 是单调递增函数。如:采用
是单调递增函数。如:采用 isotonic回归。这种方式的优点是:通用性更强。无论平均预测
CTR较高还是较低,它都能很好的校准。
对于数据集,我们通常需要对不同数据区间对应的子集进行校准。因为很有可能模型对 “女性” 用户预测的平均
CTR偏高,对“男性”用户预测的平均CTR偏低,但是整体预测的平均CTR较好。这时我们需要分别针对 “女性” 用户、“男性” 用户分别进行模型校准。
论文还研究了一些探索方向,但是这些方向是无效的,并不能带来很好的效果。
基于特征哈希
feature hasing技术可以大规模降低训练的内存代价。但是实验发现:这种方式会带来模型预测能力的明显下降,因此无法应用。
基于
dropout的正则化并不会带来任何好处,甚至会降低模型预测能力。其根本原因是:数据特征非常稀疏,经过
dropout之后更为稀疏。在计算机视觉任务中,输入特征是非常密集的,且标签是比较干净的。
此时
dropout将高度相关的特征分离开,从而产生更健壮的分类器。而在
CTR预估任务中,输入特征是非常稀疏的,且标签是带噪音的。此时
dropout会显著降低学习的数据量,降低学习效果。
样本归一化:论文尝试将样本归一化 ,最终效果不理想。
猜测的原因:维度独立的学习率和样本归一化相互作用,导致效果下降。

