
-
如果有
Harry Potter和J. K. Rowling关系的先验知识,则无需借助很长的上下文就可以很容易的预测出缺失的单词为Harry Potter。 ERNIE: Enhanced Representation through Knowledge Integration改变了BERT的mask策略,通过引入entity-level mask和phrase-level mask来引入先验知识。但是
ERNIE并没有直接添加先验知识,而是隐式的学习实体间的关系、实体的属性等知识。
6.1.1 Entity-level Mask & Phrase-level Mask
与直接嵌入先验知识不同,
ERNIE将短语级phrase-level和实体级entity-level知识通过多阶段学习集成到语言表示中。ERNIE将一个短语phrase或者一个实体entity作为一个单元,每个单元通常由几个token组成。在训练期间,同一个单元中的所有token都会被屏蔽,而不是只有一个token被屏蔽。通过这种方式,
ERNIE在训练过程中隐式的学习短语或实体的先验知识。- 对于英语,论文使用单词分析和分块工具来获取短语的边界;对于中文,论文使用分词工具来获取词的边界。
- 命名实体
entity包括人名、地名、组织名、产品名等。
ERNIE通过三阶段学习来学得短语或实体的先验知识:第一阶段
Basic-level masking:使用基本的掩码策略,做法与BERT完全相同。这个阶段是在基本语言单元的随机
mask上训练,因此很难对高级语义知识建模。第二阶段
Phrase-level masking:使用基本语言单元作为训练输入,但是使用phrase-level的掩码策略。这个阶段模型屏蔽和预测同一个短语的所有基本语言单元 。
第三阶段
Entity-level masking:使用基本语言单元作为训练输入,但是使用entity-level的掩码策略。这个阶段模型屏蔽和预测同一个命名实体的所有基本语言单元 。

ERNIE编码器和BERT相同,但是对于中文语料,ERNIE把CJK编码范围内的字符都添加空格来分隔,然后使用WordPiece来对中文语句词干化。
6.1.2 预处理
ERNIE使用异构语料库进行预训练,其中包括:- 中文维基百科(2100万句子)
- 百度百科(5100万句子),包含书面语编写的百科文章
- 百度新闻(4700万句子),包含电影名、演员名,足球队名等等的最新信息
- 百度贴吧(5400万句子),每个帖子都被视为一个对话
thread
另外,
ERNIE执行汉字繁体到简体的转换、英文字符大写到小写的转换。最终模型的词汇表 17964 个unicode字符。
6.1.3 对话语言模型
对话数据对于语义表示很重要,因为相同回答对应的问题通常是相似的。因此
ERNIE采用对话语言模型Dialogue Language Model:DLM任务对query - response对话进行建模,通过引入dialogue embedding来识别对话中的角色。Q表示query的embedding,R表示response的embedding。ERNIE不仅可以表示单轮对话QR,还可以表示多轮对话,如QRQ,QRR,QQR等等。
和
MLM任务类似,DLM任务随机mask掉query或者response中的token,然后根据query和response来预测缺失的单词。通过这种方式,
DLM帮助ERNIE去学习对话中的隐含关系,从而增强了模型学习语义表达的能力。- 也可以将
query或者response用一个随机挑选的句子替代,然后预测该对话是真的还是假的。 DLM任务的结构和MLM任务的结构是兼容的,因此可以直接替代MLM任务。
- 也可以将
6.1.4 实验
为了与
BERT-base比较,ERNIE选择了同样的模型尺寸:Transformer-Layer共12层,网络中隐向量均为768维, 网络的multi-head为 12 头。ERNIE在 5 项中文NLP任务中的表现如下图所示。这5项任务包含:自然语言推理natural language inference:NLI,语义相似度semantic similarity,命名实体识别named entity recognition:NER,情感分析 ,问答question answering:QA。其中:自然语言推理数据集采用
Cross-lingual Natural Language Inference :XNLI数据集:包含一个众包的MultiNLI数据集,每一对被人工标记了蕴含关系,并被翻译成包括汉语在内的 14 种语言。标签包含:矛盾
contradicition、中立neutral、蕴含entailment。语义相似度数据集采用
Large-scale Chinese Question Matching Corpus:LCQMC数据集:每一对句子被人工标记一个二元标签,表示语义是否相似。命名实体识别数据采用
MSRA-NER数据集:由微软亚研院发布,包含几类实体:人名、地名、组织名称等。情感分析采用
ChnSentiCorp数据集:包含了酒店、书籍、电脑等多个领域的评论及其人工标注的二元情感分类。QA采用NLPCC-DBQA数据集:包含了一些问题及对应的人工筛选出来的答案。
ERNIE对各种level的mask的实验结果如下图所示,其中10% of all表示使用1/10的语料库进行训练。结果表明:
- 使用更大的预训练集,效果会更好。
ERNIE引入DLM任务的实验结果如下图所示,其中:10% of all表示使用1/10的语料库来训练,但是这10%采用了不同的挑选策略:Baike(100%):这10%全部由百度百科语料组成。Baike(84%) / news(16%):这10%由84%的百度百科语料、16%的百度新闻语料组成。Baike(71.2%)/news(13%)/forum Dialogure(15.7%):这10%由71.2%的百度百科、13%的百度新闻、15.7%的百度贴吧对话语料组成。
- 所有结果是在
XNLI任务上执行5次随机重启的fine-tuning的均值。

完形填空实验:将命名实体从段落中移除,然后模型需要预测被移除的实体。
ERNIE在完形填空实验的结果如下图所示。例 1 中,
BERT试图复制上下文中出现的名称,而ERNIE记得文章中提到的关于实体关系的知识。例 2 和 5 中,
BERT能根据上下文成功地学习模式,从而可以正确预测命名实体类型,但是预测了错误的实体。例 3、4、6中,
BERT用几个与句子相关的字符填充mask,完全未能学习到缺失的实体对应的概念。除了例 4 之外,
ERNIE都预测到了正确的实体。对于例 4,虽然
ERNIE预测错了实体,但是它给出的结果具有相同的语义类型。
6.2 ERNIE 2.0
ERNIE 2.0提出了一个持续学习框架framework,它通过持续的多任务学习来学习预训练模型。- 与其它预训练模型相同,它也是采取预训练阶段和微调阶段的两阶段模式。
- 与其它预训练模型不同,其预训练阶段的预训练任务可以持续的、增量的构建,从而帮助模型有效的学习词法
lexical、句法syntactic和语义semantic表示。
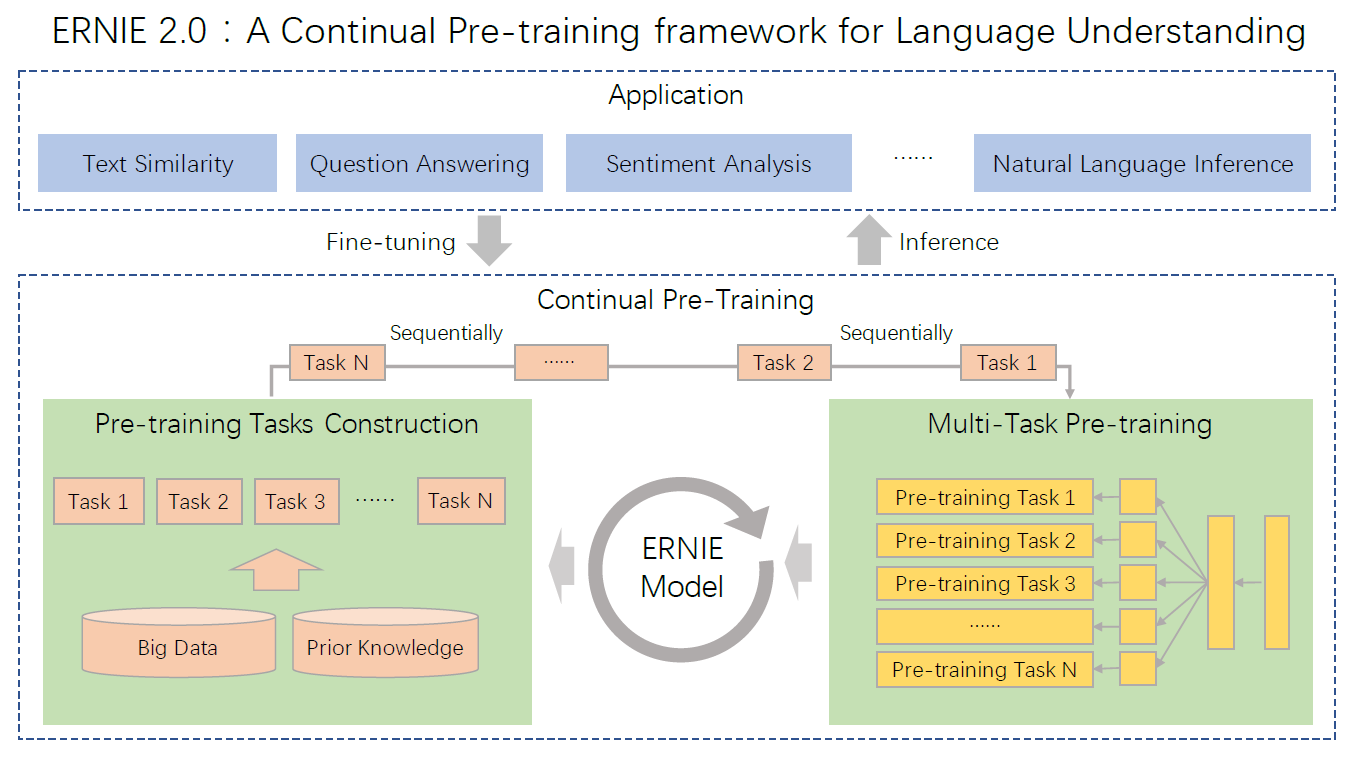
ERNIE 2受到人类学习过程的启发:人类能够不断积累那些通过学习获得的经验,然后基于过去的经验可以拓展出新的技能。同样的,
ERNIE 2预期模型通过多个任务训练之后,在学习新任务时能够记住以前学得的知识。常见的预训练模型基于单词的共现或者句子的共现来训练模型,而
ERNIE 2基于词法、句法、语义上的信息来训练模型。- 命名实体可能包含一些概念,可用于捕获词法信息
- 句子之间的顺序、句子之间的相似度包含了一些语言结构,可用于捕获句法信息
- 文档之间的语义相似性、句子之间的对话关系包含了一些语言的语义,可用于捕获语义信息。
6.2.1 模型结构
持续预训练阶段包含两个步骤:
不断构建包含大量数据和先验知识的无监督预训练任务,其中包括:
word-aware单词相关的任务、structure-aware句子结构相关的任务、semantic-aware句子语义相关的任务。这些任务仅仅依赖于无需人工标注的自监督
self-supervised语料,或者弱监督weak-supervised语料。通过多任务学习不断更新
ERNIE模型。首先通过一个简单的预训练任务来训练模型。
然后每次添加一个新的预训练任务时,用前一个模型的参数来初始化当前模型。
每当引入一个新的预训练任务时,它就会和先前的任务一起训练,从而确保模型不会忘记它之前所学到的知识。这样
ERNIE就能够不断学习和积累在学习过程中获得的知识。
持续预训练阶段的训练框架包含一系列用于编码上下文信息的
encoder层,这可以通过RNN/LSTM/Transformer来实现。encoder层的参数在所有预训练任务中共享和更新。每个预训练任务都有自己的损失函数。其中损失函数有两种类型:
sequence-level损失函数:每个序列一个loss,如句子情感分析任务。token-level损失函数:每个token一个loss,如机器阅读理解任务。
微调阶段:使用每个下游任务的具体监督语料来进行微调,最终每个下游任务都有自己的微调模型。
ERNIE 2给不同的预训练任务分配task id,对每个task训练一个唯一的task embedding。因此
ERNIE 2的输入embedding包含了token embedding, segment embedding, position embedding, task embedding这四种embedding。而在微调阶段,因为下游任务通常与预训练任务不同,此时选择任意一个
task id的task embedding来初始化即可。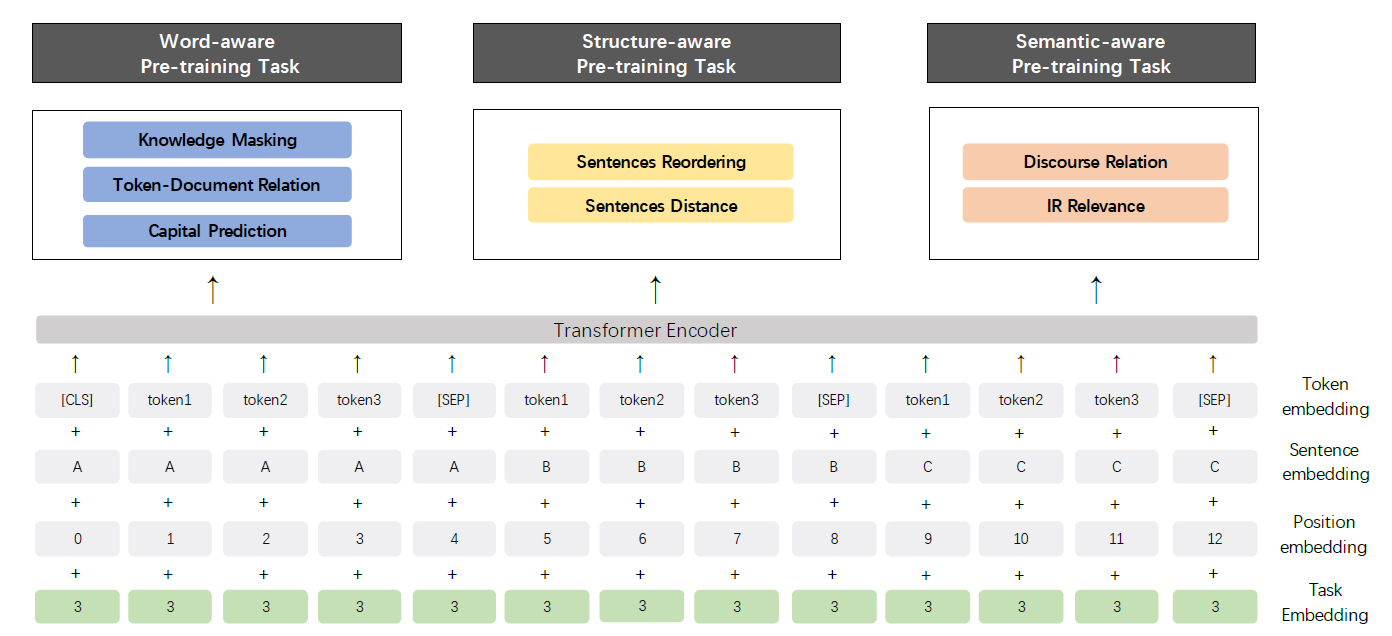
预训练任务:
word-aware单词相关的任务:捕捉词法信息。Knowledge Masking Task:在ERNIE 1.0中使用的预训练任务,通过知识集成来提高模型表达能力。该任务通过引入短语 和命名实体
mask来预测整个短语或者命名实体,从而帮助模型学习到局部上下文(短语、命名实体内部字符)和全局上下文 (短语之间、命名实体之间)的依赖信息。Capitalization Prediction Task:预测一个单词是大写单词还是小写单词。大写单词通常具有特定的语义价值。因此通过该任务的学习,模型有利于命名实体识别任务。
Token-Document Relation Prediction Task:预测一个段落中的token是否出现在原始文档的其它段落中。通常如果一个单词出现在文档的很多地方,则该单词是常用词或者文档的关键词。因此通过该任务,模型能够在一定程度上捕获文档关键词。
structure-aware句子结构相关的任务:捕获句法信息。Sentence Reordering Task:学习同一篇文档句子之间的顺序关系。给定的段落被随机切分成 1 到 个部分,然后被随机混洗。模型需要预测其正确的句子顺序。
该问题视为一个
 分类问题,其中 。
分类问题,其中 。Sentence Distance Task:学习文档级别的句子之间的距离关系。给定两个句子,如果它们在同一个文档中且相邻则标记为
0;如果在同一个文档中且不相邻则标记为1;如果不在同一个文档中则标记为2。
6.2.2 实验
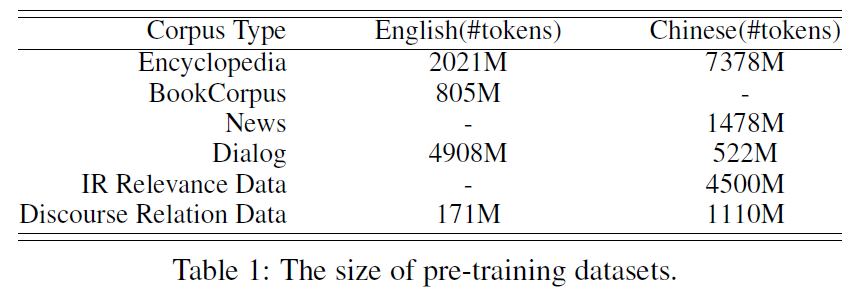
预训练数据:
- 英文训练语料库:除了
BERT用到的英文维基百科、BookCorpus数据集,ERNIE 2还使用了Reddit,Discovery数据集。 - 中文训练语料库:采用百度搜索引擎收集到的各种数据,包括:百度百科、新闻数据、对话数据、检索日志、对话关系。
- 英文训练语料库:除了
预训练配置:
为了和
BERT比较,模型尺寸几乎相同.base model尺寸为:12 层Transformer、12 头、隐向量 768 维large model尺寸为:24 层Transformer、16 头、隐向量 1024 维
采用
Adam优化器,参数为: 。batch size包含 393216 个token。通过采用
float16精度的操作来加快训练和降低内存使用。ERNIE 2.0的base model在 48块NVidia V100 GPU显卡上训练,large model在 64 块NVidia V100 GPU显卡上训练。
英文微调任务:在
GLUE上微调,其中包括以下任务及其标记数据:Corpus of Linguistic Acceptability: CoLA:预测一个句子是否符合语法规范。标记数据由来自23个语言学领域的 10657个句子组成,人工标注其是否语法上可接受。
Stanford Sentiment Treebank:SST-2:预测评论的情感。标记数据由 9645 条电影评论组成,人工标注情感标签。
Multi-genre Natural Language Inference:MNLI:预测句子之间的蕴含关系。标记数据由众包的 43.3 万句子对组成,人工标注了句子之间的蕴含关系。
Recognizing Textual Entailment:RTE:类似MNLI,但是标记数据的规模更小Winograd Natural Language Inference:WNLI:预测两段文本之间的共指信息。Quora Question Pairs:预测两个句子是否语义相同。标记数据从
Quora问答社区提取的40万句子对组成,人工标注了句子之间是否语义相同。Microsoft Research Paraphrase Corpus:MRPC:预测两个句子是否语义相同。标记数据由互联网新闻中提取的 5800对句子组成,人工标注句子之间是否语义相同。
Semantic Textual Similarity Benchmark:STS-B:预测两个句子之间语义是否相似。标记数据包含从图片标题、新闻标题、用户论坛的文本,用于评估语义相似性。
Question Natural Language Inference:预测一对给定文本之间的关系是否是问题和对应的答案。AX:一个辅助的手工制作的诊断测试工具,用于对模型分析。
数据集的大小如下图所示,其中
#Train,#Dev,#Test分别给出了训练集、验证集、测试集大小,#Label给出了类别集合的大小。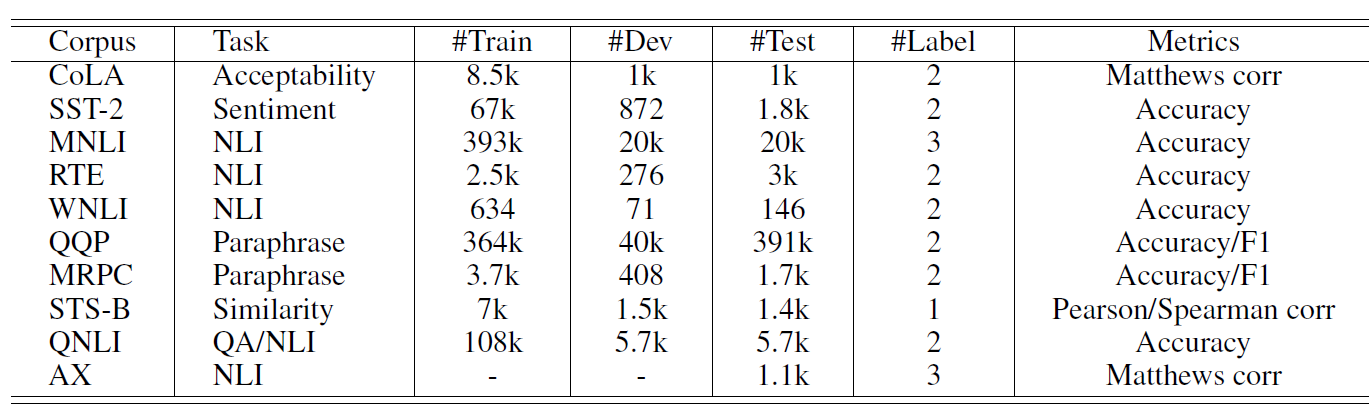
微调超参数参数:
微调结果:
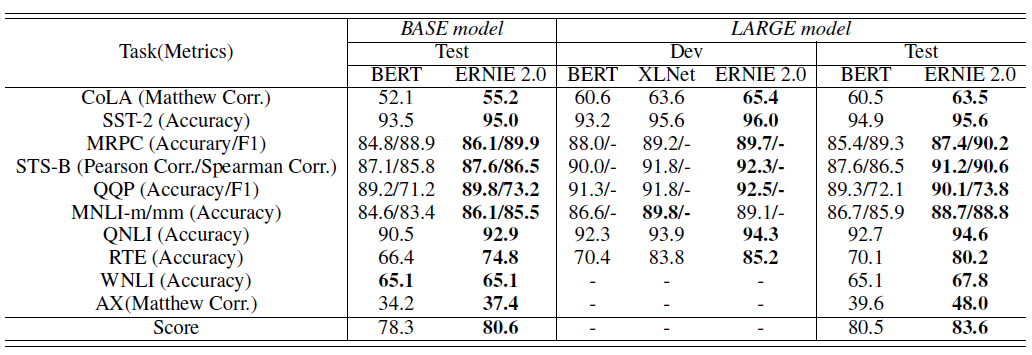
中文微调任务:包括机器阅读理解、命名实体识别、自然语言推理、语义相似度、情感分析和问答等 9 个中文
NLP任务。机器阅读理解
Machine Reading Comprehension:MRC:典型的文档级建模任务,用于从给定文本中提取出连续的片段来回答问题。数据集:
Chinese Machine Reading Comprehension 2018 : CMRC 2018:由中国信息处理学会、IFLYTEK和哈工大发布的机器阅读理解数据集。Delta Reading Comprehension Dataset:DRCD:由Delta研究所发布的繁体中文机器阅读理解数据集,通过工具将它转换为简体中文。DuReader:百度在 2018年ACL发布的大规模中文机器阅读理解、问答数据集,所有问题是从真实的、匿名的用户的query中得到的,问题的回答是人工生成的。
命名实体识别
Named Entity Recognition:NER:单词级别的建模任务,识别出文本中的命名实体。数据集:微软亚洲研究院发布的
MSRA-NER数据集自然语言推理
Natural Language Inference:NLI:句子级别的建模任务,判定两个给定句子之间的蕴含关系。数据集:
XNLI数据集。情感分析
Sentiment Analysis:SA:句子级别的建模任务,用于判定给定的句子情感是积极的还是消极的。数据集:
ChnSentiCorp数据集。该数据集包含酒店、书籍和PC等多个领域的评论。语义相似度
Semantic Similarity:SS:句子级别的建模任务,用于判断给定两个句子是否语义相似。数据集:
LCQMC:哈工大 2018年发布的语义相似数据集
问答
Question Answering:QA:句子级别的建模任务,用于给每个问题挑选一个正确答案。数据集:
NLPCC-DBQA,该数据集 2016年在NLPCC上发布。
数据集的大小如下图所示,其中 分别给出了训练集、验证集、测试集大小,
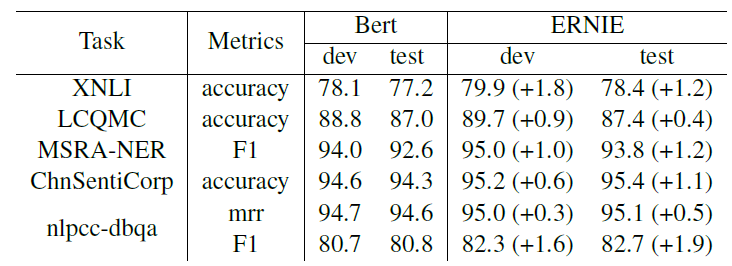
#Label给出了类别集合的大小。中文微调超参数:
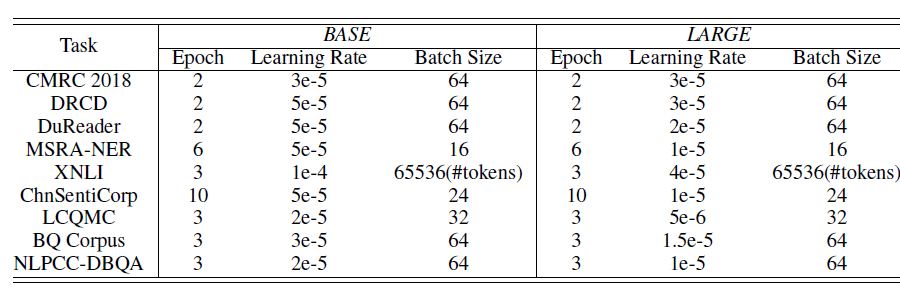
中文微调结果:

