
-
table_name:一个字符串,指定了数据库的表名con:一个SQLAlchemy conectable或者一个database string URI,指定了连接对象它就是SQLAlchemy中的Engine对象。schema:一个字符串,给出了SQL schema(在mysql中就是database)coerce_float:一个布尔值,如果为True,则试图转换结果到数值类型parse_dates:一个列表或者字典。指定如何解析日期:- 列名的列表:这些列将被解析为日期
- 字典
{col_name:format_str}:给出了那些列被解析为日期,以及解析字符串
columns:一个列表,给出了将从sql中提取哪些列
read_sql_query可以选择select query语句。因此你可以执行多表联合查询。sql:一个SQL查询字符串,或者SQLAlchemy Selectable对象。params:一个列表,元组或者字典。用于传递给sql查询语句。比如:sql为uses %(name)s...,因此params为{'name':'xxxx'}- 其他参数见
read_sql_table
read_sql是前两者的一个包装,它可以根据sql参数,自由地选择使用哪个方式。sql:一个数据表名,或者查询字符串,或者SQLAlchemy Selectable对象。如果为表名,则使用read_sql_table;如果为后两者,则使用read_sql_query
-
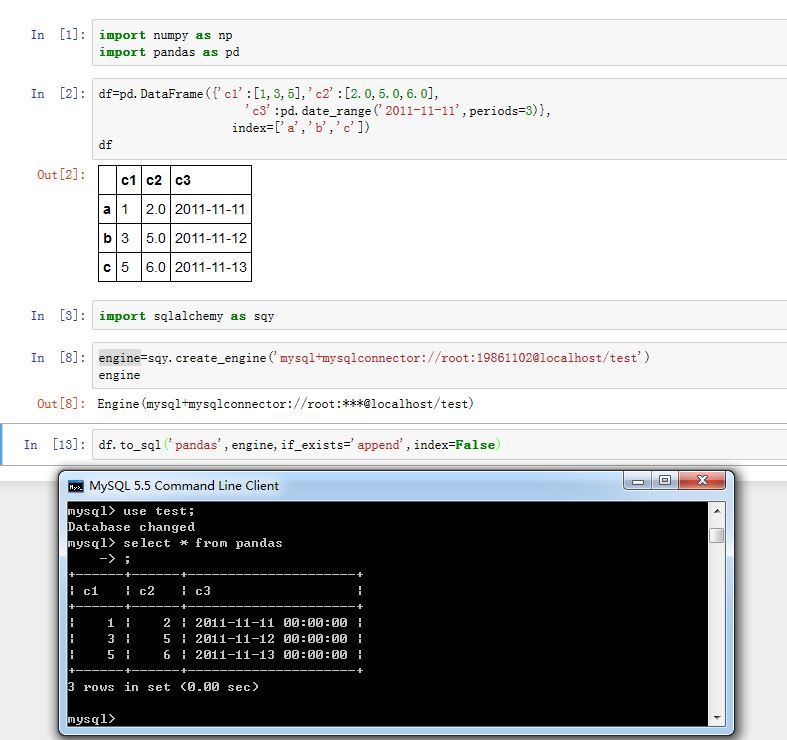
con:一个或者一个database string URI,指定了连接对象。它就是SQLAlchemy中的Engine对象。flavor:被废弃的参数schema:一个字符串,指定了SQL schemaif_exists:一个字符串,指定当数据表已存在时如何。可以为:'fail':什么都不做(即不存储数据)'replace':删除数据表,创建新表,然后插入数据'append':如果数据表不存在则创建数据表然后插入数据。入股数据表已存在,则追加数据index:一个布尔值。如果为True,则将index作为一列数据插入数据库index_label:index的存储名。如果index=True,且index_label=None,则使用index.namedtype:一个字典。给出了各列的存储类型。
6. SQL
本文档使用 BookStack 构建

