
-
随着关系尺度的变化,网络的拓扑结构也发生变化。如下图所示:
- 当考虑家庭、朋友关系这一尺度时只有黄色部分构成一个社区。
- 当考虑学校、企业关系这一尺度时只有蓝色部分(包括黄色部分)构成一个社区。
- 当考虑民族、国家关系这一尺度时所有顶点都构成一个社区。
在这个过程中尺度扮演者关键的角色,它决定了社区的规模以及顶点归属到哪些社区。
在网络
representation学习的任务中,大多数方法都是一刀切:每个顶点得到一个融合了所有尺度的representation,无法明确的捕获网络内结点之间的多尺度关系,因此无法区分网络在各个尺度上的差异。GraRep方法显式的建模多尺度关系,但是计算复杂度太高从而无法扩展到真实世界的大型网络。论文
《Don’t Walk, Skip! Online Learning of Multi-scale Network Embeddings》提出了WALKLETS模型,该模型是一种在线的图reprensentation学习方法,可以捕获网络顶点之间的多尺度关系,并且可扩展性强,支持扩展到百万顶点的大型网络。WALKLETS将每个顶点映射到低维reprensentation向量,该向量捕获了顶点所属社区的潜在层次结构。在预测时可以用单个尺度representationi或者组合多个尺度representation来提供顶点更全面的社区关系。下图来自于
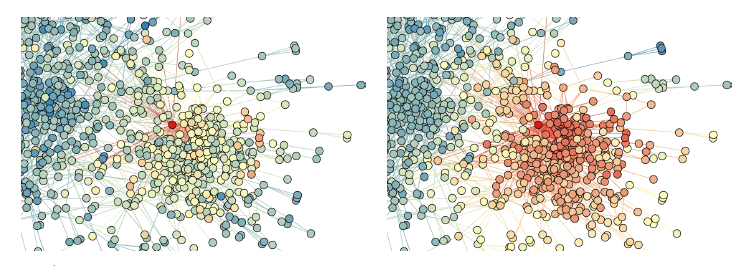
Cora引用网络的一个子网络的二维可视化,中心的红色顶点表示源点,顶点颜色代表该顶点和源点的距离:距离越近颜色越红,距离越远颜色越蓝。- 左图给出了细粒度
representation相似度的结果。在这一尺度下,只有源点的直系邻居才是相似的。 - 右图给出了粗粒度
representation相似度的结果。在这一尺度下,源点附近的很多顶点都是相似的。
- 左图给出了细粒度
我们受到一个事实的启发:通过一个结点可能同时隶属于不同层次的圈子,如家庭、学校、公司等等。针对这些不同的社区进行建模和预测不仅对于了解网络结构至关重要,而且还具有重要的商业价值,如更有效的广告定向。
给定图 ,其中:
 为图的顶点集合, 表示图的一个顶点。
为图的顶点集合, 表示图的一个顶点。 为图的边集合, 表示顶点
为图的边集合, 表示顶点  之间的边,其权重为 。权重衡量了边的重要性。
之间的边,其权重为 。权重衡量了边的重要性。
定义邻接矩阵
 为:
为:这里假设所有的权重都是正的。
定义度矩阵
degree matrix 为一个对角矩阵:
为一个对角矩阵:假设顶点
 转移到顶点 的概率正比于
转移到顶点 的概率正比于  ,则定义转移概率矩阵
,则定义转移概率矩阵 probability transition matrix: 。其中 定义了从顶点 经过一步转移到顶点
定义了从顶点 经过一步转移到顶点  的概率,因此也称为一阶转移概率矩阵。
的概率,因此也称为一阶转移概率矩阵。多尺度
representation学习任务需要学习 个representation ,其中 捕获了网络在尺度
,其中 捕获了网络在尺度  的视图
的视图 view。从直观上看,每个representation都编码了视角网络在不同视图下的相似性,对应于不同尺度下的潜在社区成员关系。DeepWalk采用截断的随机游走序列来对共现顶点pair对建模,其目标是估计顶点 和它邻居结点共同出现的可能性。根据论文《NeuralWord Embedding as Implicit Matrix Factorization》, 它等价于矩阵分解。即:基于层次Softmax的DeepWalk模型的优化目标对应于矩阵 的分解,其中:
的分解,其中:其中:
 是一个
是一个one-hot向量,其第 个元素为1其余元素为零。 表示向量的第 个元素。
表示向量的第 个元素。
由于
 的不同幂次 代表了不同的尺度,可以看到
的不同幂次 代表了不同的尺度,可以看到 DeepWalk已经隐式的建模了从尺度1到尺度K的多尺度依赖关系,这表明DeepWalk学到的表达能够捕获社交网络中的短距离依赖性和长距离依赖性。尽管如此,DeepWalk捕获的多尺度representation仍然有以下缺陷:仅保留全局
representation:DeepWalk得到的是一个覆盖网络所有尺度的全局表达,因此无法访问不同尺度的表达。
WALKLETS扩展自DeepWalk,但是显式的对多尺度依赖性进行建模。也是基于截断的随机游走序列对网络进行建模,但是它对采样过程进行修改:在随机游走序列上跳过
 个顶点来显式构建 阶关系。
个顶点来显式构建 阶关系。如下图所示:
左图为
DeepWalk的采样过程:给定一条截断的随机游走序列,我们将所有的 阶关系顶点
阶关系顶点pair对加入语料库来训练。右图为
WALKLETS的采样过程:给定一条截断的随机游走序列,我们采样了 个语料库: 语料库:所有一阶关系顶点
语料库:所有一阶关系顶点pair对加入该语料库。- 语料库:所有二阶关系(跳过一个顶点)顶点
pair对加入该语料库。 - …
 语料库:所有 阶关系(跳过
语料库:所有 阶关系(跳过  个顶点)顶点
个顶点)顶点pair对加入该语料库。
不同的语料库独立训练,分别得到不同尺度下的顶点表达。
本质上第 个语料库的优化目标对应于矩阵
 的矩阵分解。
的矩阵分解。
WALKLETS除了采样策略与DeepWalk不同之外,优化方式、搜索策略都与DeepWalk相同。WALKLETS和DeepWalk都使用随机梯度下降SGD来优化目标函数。WALKLETS和DeepWalk通常应用于无权图,但是可以通过将梯度乘以边的权重从而扩展到加权图。也可以通过边采样技术从而扩展到加权图。WALKLETS和DeepWalk都使用深度优先搜索策略。相比于宽度优先搜索,深度优先搜索可以编码更长距离的信息,从而能够学得更高阶的representation。- 也可以引入
node2vec的有偏随机游走策略来扩展WALKLETS。 - 也可以直接计算 从而根据 阶转移概率矩阵来采样生成 阶顶点
pair对。但是这种方式只适合小型网络,因为大型网络计算 的算法复杂度太高。
- 也可以引入
7.2 实验
7.2.1 可视化
数据集为
Cora数据集,该数据集包含来自七个类别的2708篇机器学习论文。论文之间的链接代表引用关系,共有
5429个链接。从标题、摘要中生成短文本作为文档,并经过停用词处理、低频词处理(过滤文档词频低于 10个的单词),并将每个单词转化为
one-hot向量。最终每篇文档映射为一个
1433维的binary向量,每一位为0/1表示对应的单词是否存在。
我们首先以顶点
 作为源点,观察其它所有顶点和源点以
作为源点,观察其它所有顶点和源点以representation的cosin相似度作为距离的分布。可以看到:随着尺度的扩大(从 到
 ),一个社区逐渐形成。这说明更大尺度的
),一个社区逐渐形成。这说明更大尺度的representation可以更好的捕获网络的底层结构特征,从而有助于解决下游任务。
7.2.2 多标签分类
数据集:
BlogCatalog:该数据集包含BlogCatalog网站上博客作者之间的社交关系,标签代表通过元数据推断出来的博客兴趣。网络包含10312个顶点、333983条边、39种不同标签。DBLP Network:该数据集包含学者之间的论文合作关系。每个顶点代表一个作者,边代表一个作者对另一位作者的引用次数。网络包含29199个顶点、133664条边、4种不同标签。Flickr数据集:网站用户之间的关系网络。标签代表用户的兴趣组,如“黑白照片”。网络包含80513个顶点、58999882条边、195种不同标签。YouTube数据集:YouTube网站用户之间的社交网络。标签代表用户的视频兴趣组,如“动漫、摔跤”。网络包含1138499个顶点、2990443条边、47种不同标签。
基准模型:
DeepWalk:使用截断的随机游走序列来学习顶点的表达,学到的representation捕获了多个尺度的社区成员关系的线性组合。LINE:类似于DeepWalk,但是这里我们仅仅考虑一阶邻近度,即只考虑 。-
本质上该方法和
WALKLET是类似的,但是它不是在线学习方法,且无法扩展到大规模网络。
网络参数:
我们使用随机梯度下降法求解最优化目标,并且使用 的
 正则化,默认的初始化学习率为
正则化,默认的初始化学习率为 0.025。每个顶点的游走序列数量为
1000,每个序列的长度为11,维度 为128。对于
WALKLETS我们分别考虑尺度为1,2,3的representation。同时我们也会考虑多个尺度表达的融合,此时我们分别将每个尺度的表达向量拼接起来,然后使用
PCA降到128维。通过这种方式我们和其它方法进行可解释的比较。
我们随机抽取
 比例的标记样本作为训练集,剩下的顶点作为测试集,采用基于
比例的标记样本作为训练集,剩下的顶点作为测试集,采用基于 one vs rest的逻辑回归来执行多标签分类任务。每种情况随机重复执行十次,取平均的
MICRO-F1作为评估指标。这里不报告准确率以及MACRO-F1得分,因为这些指标的趋势都相同。实验结果如下:BlogCatalog网络:使用 的WALKLETS超越了所有其它模型。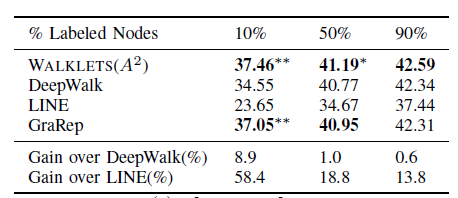
DBLP网络:使用 的WALKLETS超越了除GraRep之外的所有其它模型。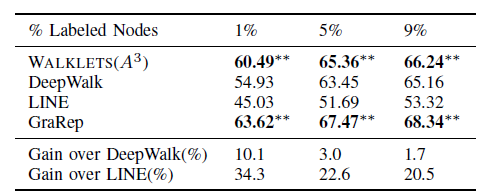
Flickr网络:使用 的WALKLETS超越了所有其它模型。GraRep无法处理该数据集,因为内存不足。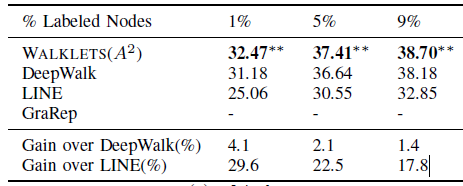
Youtube网络: 联合使用 的WALKLETS超越了所有其它模型。GraRep无法处理该数据集,因为内存不足。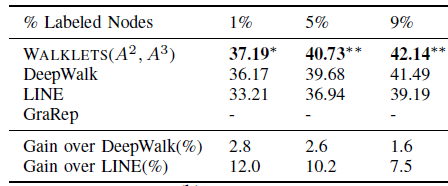
我们继续考察
WALKLETS通过采样来逼近 的有效性。给定图
 ,我们首先显式的计算 阶转移矩阵 ,然后通过
,我们首先显式的计算 阶转移矩阵 ,然后通过WALKLETS的随机游走过程来预估 ,并计算这两个矩阵的差异:
我们在 数据集上进行评估,游走参数如前所述。我们分别给出平均误差和标准差。
可以看到在各种尺度下,误差的均值和标准差都很低,这表明通过随机游走序列能够得到转移矩阵的一个良好近似。并且通过增加随机游走序列的数量,这种误差会进一步降低。

