
- 提出了一种新的架构单元来解决通道之间相互依赖的问题。它通过显式地对通道之间的相互依赖关系建模,自适应的重新校准通道维的特征响应,从而提高了网络的表达能力。
SENet以2.251% top-5的错误率获得了ILSVRC 2017分类比赛的冠军。SENet是和ResNet一样,都是一种网络框架。它可以直接与其他网络架构一起融合使用,只需要付出微小的计算成本就可以产生显著的性能提升。
对于给定的任何变换 ,其中:
 为输入
为输入feature map,其尺寸为,通道数为 ; 为输出
; 为输出feature map,其尺寸为 ,通道数为 。
,通道数为 。可以构建一个相应的
SE块来对输出feature map 执行特征重新校准:
执行特征重新校准:- 首先对输出
feature mapsqueeze操作,它对每个通道的全局信息建模,生成一组通道描述符。 - 然后是一个
excitation操作,它对通道之间的依赖关系建模,生成一组权重信息(对应于每个通道的权重)。 - 最后输出
feature map 被重新加权以生成SE块的输出。
- 首先对输出
SE块可以理解为注意力机制的一个应用。它是一个轻量级的门机制,用于对通道关系进行建模。通过该机制,网络学习全局信息(全通道、全空间)来选择性的强调部分特征,并抑制其它特征。
7.1.1 squeeze 操作
squeeze操作的作用是:跨空间 聚合特征来产生通道描述符。该描述符嵌入了通道维度特征响应的全局分布,包含了全局感受野的信息。
每个学到的滤波器都是对局部感受野进行操作,因此每个输出单元都无法利用局部感受野之外的上下文信息。
在网络的低层,其感受野尺寸很小,这个问题更严重。
为减轻这个问题,可以将全局空间信息压缩成一组通道描述符,每个通道对应一个通道描述符。然后利用该通道描述符。
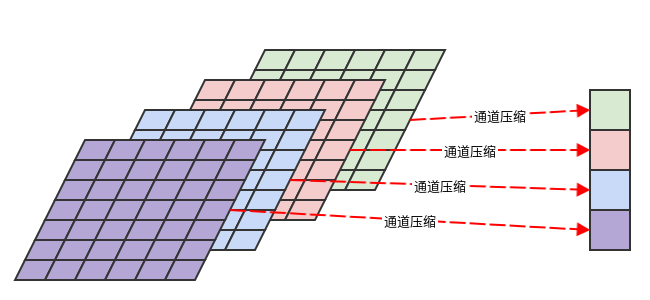
通常基于通道的全局平均池化来生成通道描述符(也可以考虑使用更复杂的聚合策略)。
设所有通道的通道描述符组成一个向量 。则有:

.
7.1.2 excitation 操作
excitation操作的作用是:通过自门机制来学习每个通道的激活值,从而控制每个通道的权重。-
首先,通道描述符 经过线性降维之后,通过一个
ReLU激活函数。降维通过一个输出单元的数量为
 的全连接层来实现,其中 为降维比例。
的全连接层来实现,其中 为降维比例。然后, 激活函数的输出经过线性升维之后,通过一个
sigmoid激活函数。升维通过一个输出单元的数量为
 的全连接层来实现。
的全连接层来实现。
通过对通道描述符 进行降维,显式的对通道之间的相互依赖关系建模。
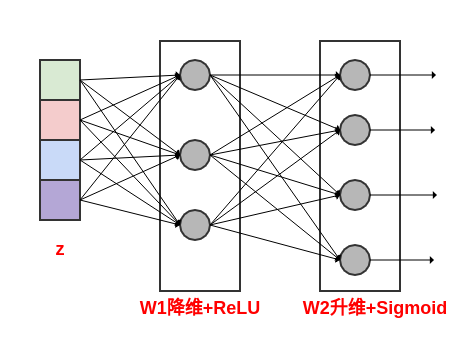
设
excitation操作的输出为向量 ,则有: 。
。其中: 为
sigmoid激活函数, 为降维层的权重, 为升维层的权重,
为降维层的权重, 为升维层的权重, 为降维比例。
为降维比例。在经过
excitation操作之后,通过重新调节 得到SE块的输出。设
SE块的最终输出为 ,则有: 。这里
,则有: 。这里  为
为excitaion操作的输出结果,它作为通道 的权重。 不仅考虑了本通道的全局信息(由 引入),还考虑了其它通道的全局信息(由  引入)。
引入)。
7.1.3 SE 块使用
有两种使用
SE块来构建SENet的方式:简单的堆叠
SE块来构建一个新的网络。在现有网络架构中,用
SE块来替代原始块。下图中,左侧为原始
Inception模块,右侧为SE-Inception模块。下图中,左侧为原始残差模块,右侧为
SE-ResNet模块。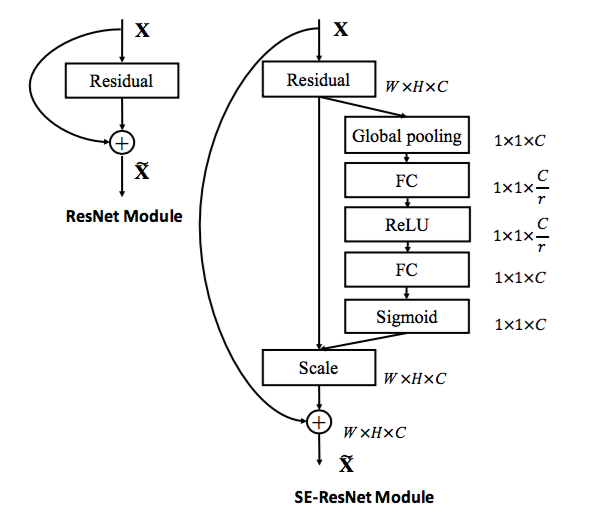
超参数 称作减少比率,它刻画了需要将通道描述符组成的向量压缩的比例。它是一个重要的超参数,需要在精度和复杂度之间平衡。
如下所示为
SE-ResNet-50采用不同的 在 ImageNet验证集上的预测误差(single-crop)。original表示原始的ResNet-50。虽然
SE块可以应用在网络的任何地方,但是它在不同深度中承担了不同的作用。在网络较低的层中:对于不同类别的样本,特征通道的权重分布几乎相同。
这说明在网络的最初阶段,特征通道的重要性很可能由不同的类别共享。即:低层特征通常更具有普遍性。
在网络较高的层中:对于不同类别的样本,特征通道的权重分布开始分化。
这说明在网络的高层,每个通道的值变得更具有类别特异性。即:高层特征通常更具有特异性。
在网络的最后阶段的
SE块为网络提供重新校准所起到的作用,相对于网络的前面阶段的 块来说,更加不重要。这意味着可以删除最后一个阶段的
SE块,从而显著减少总体参数数量,仅仅带来一点点的损失。如:在SE-ResNet-50中,删除最后一个阶段的SE块可以使得参数增加量下降到 4%,而在ImageNet上的top-1错误率的损失小于0.1%。因此:
Se块执行特征通道重新校准的好处可以通过整个网络进行累积。
7.2 网络性能
网络结构:其中
fc,[16,256]表示SE块中的两个全连接层的输出维度。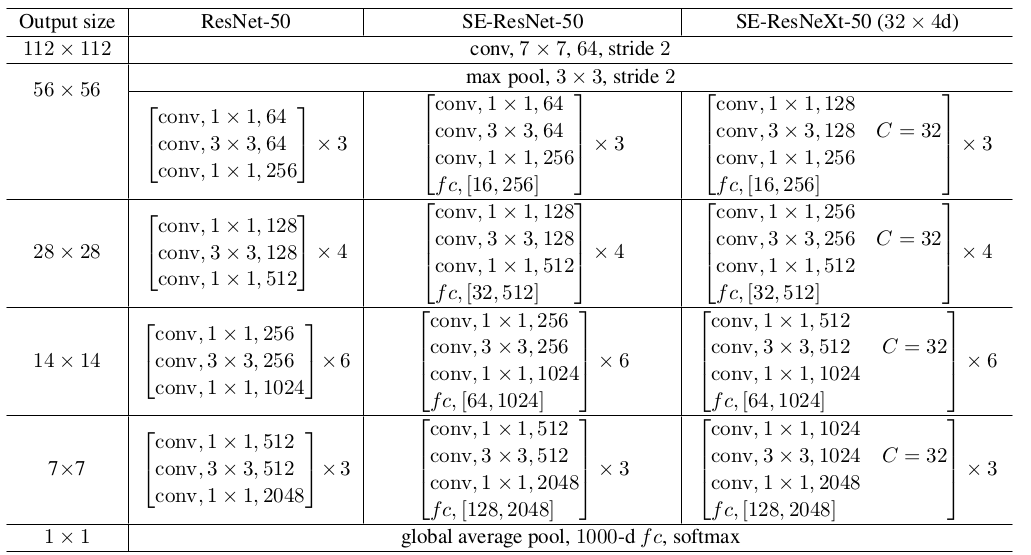
在
ImageNet验证集上的计算复杂度和预测误差比较(single-crop)。original列:从各自原始论文中给出的结果报告。re-implementation列:重新训练得到的结果报告。SENet列:通过引入SE块之后的结果报告。GFLOPs/MFLOPs:计算复杂度,单位为G/M FLOPs。MobileNet采用的是1.0 MobileNet-224,ShuffleNet采用的是1.0 ShuffleNet 1x(g=3)。数据集增强和归一化:
- 随机裁剪成
224x224大小(Inception系列裁剪成299x299)。 - 随机水平翻转。
- 随机裁剪成

在
ImageNet验证集上的预测误差比较(single-crop):

