
-
自回归语言模型 :通过自回归模型来预测一个序列的生成概率。
令序列为 ,则模型计算概率
 ,或者反向概率 。
,或者反向概率 。令
 是通过
是通过 RNN或者Transformer提取的单向上下文representation向量, 是 的
的 embedding向量,则有:给定预训练数据集
 ,模型基于最大对数似然的准则来最优化目标函数:
,模型基于最大对数似然的准则来最优化目标函数:即:预训练数据集
 的生成概率最大。
的生成概率最大。自编码语言模型
autoencoding language model:AE LM:通过自编码模型来从损坏的输入中重建原始数据。令原始序列为 ,添加多个噪音之后的序列为:

令这些被
mask的token为: ,则模型计算概率:
其中 是一个示性函数,当第
 个位置被
个位置被mask时取值为 1;否则取值为 0 。令 为一个
Transformer函数,它将长度为 的序列 映射成一个长度为 的
的序列 映射成一个长度为 的 representation向量序列: ,其中第 个位置的 representation向量为 。令 是 的
是 的 embedding向量,则有:
给定预训练数据集 ,首先通过预处理生成带噪音的数据集
 ,然后模型最大化目标函数:
,然后模型最大化目标函数:
自回归语言模型和自编码语言模型的区别:
- 自回归语言模型是生成式模型,自编码语言模型是判别式模型。
- 自回归语言模型是单向的(前向或者后向),自编码语言模型是双向的,可以使用双向上下文
自回归语言模型和自编码语言模型的缺点:
自回归语言模型是单向模型,它无法对双向上下文进行建模。而下游任务通常需要双向上下文的信息,这使得模型的能力不满足下游任务的需求。
自编码语言模型:
在预训练期间引入噪声
[MASK],而在下游任务中该噪声并不存在,这使得预训练和微调之间产生差距。根据概率分解
 可以看到:自编码语言模型假设序列中各位置处的
可以看到:自编码语言模型假设序列中各位置处的 [MASK]彼此独立,即:预测目标独立性假设。事实上,这和实际情况不符合。如:
这 里 有 很 多 水 果 , 比 如 苹 果 、 香 蕉 、葡 萄经过引入噪声之后:这 里 有 很 多 水 果 , 比 如 [MASK] [MASK] 、 香 蕉 、葡 萄。实际上这两个[MASK]之间并不是相互独立。
XLNet是一种广义自回归语言模型,它结合了自回归语言模型和自编码语言模型的优点,同时避免了它们的局限性。对于每个
token,通过概率分解的排列顺序全组合的形式, 可以 ”见到” 中的所有其它
可以 ”见到” 中的所有其它 token,因此可以捕获到双向上下文。即:在某些排列顺序下,
可以见到它的左侧上下文;在另一些排列顺序下, 可以见到它右侧上下文。XLNet没有引入噪声[MASK],因此预训练阶段和微调阶段不存在差异。XLNet基于乘积规则来分解整个序列的联合概率,消除了自编码语言模型中的预测目标独立性假设。
7.2 Permutation Language Model
XLNet是一个基于全组合的语言模型permutation language modeling。设一个长度为 3 的文本序列
 ,一共 种顺序来实现一个有效的自回归概率分解:
,一共 种顺序来实现一个有效的自回归概率分解:
这等价于先将序号 进行全组合,得到
 种顺序:
种顺序:然后对每一种顺序,按照从左到右执行自回归概率分解。
对于一个长度为
 的文本序列 ,则有
的文本序列 ,则有  种顺序来实现一个有效的自回归概率分解。如果在这些概率分解之间共享模型参数,则模型能够捕捉到所有位置的信息,即:模型能够访问双向上下文。
种顺序来实现一个有效的自回归概率分解。如果在这些概率分解之间共享模型参数,则模型能够捕捉到所有位置的信息,即:模型能够访问双向上下文。这种分解方式也考虑了
token之间的顺序。令 分别代表第一、二、三个位置的随机变量,则有:

其物理意义为:序列 可以有如下的生成方式:
- 首先挑选第一个位置的
token ,然后已知第一个位置的
,然后已知第一个位置的 token条件下挑选第二个位置的token,最后在已知第一个、第二个位置的token条件下挑选第三个位置的token
- ….
- 首先挑选第三个位置的
token,然后已知第三个位置的token条件下挑选第二个位置的token ,最后在已知第三个、第二个位置的
,最后在已知第三个、第二个位置的 token条件下挑选第一个位置的token
- 首先挑选第一个位置的
对于一个长度为3的文本序列
,传统的自回归语言模型的目标函数是生成概率的对数似然:这仅仅对应于上述 6 种概率分解中的第一个分解。
XLNet与此不同,它考虑所有的 6 种概率分解,其目标函数为:
令 表示位置编号
 的所有可能排列的组合,令 为
的所有可能排列的组合,令 为  的某个排列,如 : 。
的某个排列,如 : 。令
 为该排列的第 个位置编号,如 :
为该排列的第 个位置编号,如 : ;令 为该排列中前
;令 为该排列中前  个位置编号,如 。
个位置编号,如 。令
 为 中的编号位于
为 中的编号位于  的
的 token组成的序列。XLNet考虑所有的概率分解,因此其目标函数为:假设每一种排列是等概率的,均为
 。则有:
。则有:最终
XLNet的目标函数为:
采用期望的形式是因为:如果考虑所有的概率分解,则需要计算 种组合的概率。当序列长度为
 时 组合数量 超过 20 万亿次,计算复杂度太大导致无法计算。
时 组合数量 超过 20 万亿次,计算复杂度太大导致无法计算。所以采用期望的形式,然后利用采样来计算期望,可以使得计算复杂度大大降低。
因此对于给定的输入序列
 ,训练期间每次采样一个顺序 ,然后根据该顺序进行概率分解。
,训练期间每次采样一个顺序 ,然后根据该顺序进行概率分解。参数
 在所有的排列顺序中共享。
在所有的排列顺序中共享。
XLNet仅仅调整了联合概率 的分解顺序,并没有调整序列 本身的
本身的 token顺序。因此在XLNet中保留序列 的原始顺序,并使用原始顺序的position embedding。联合概率
 的分解顺序的调整依赖于
的分解顺序的调整依赖于 Transformer的mask机制。下图为输入序列 中,计算
 的几种排列顺序。(右下角的图形应该为 和
的几种排列顺序。(右下角的图形应该为 和  ) 。
) 。因为在微调阶段遇到的文本序列都是原始顺序的,所以这种方式保证了预训练阶段和微调阶段在输入文本序列的顺序上是一致的:都是原始顺序。
虽然
permutation language model有诸多优点,但是如果直接采用标准的Transformer结构来实现该模型,则会出现问题。考虑输入序列
 ,考虑位置编号 的两种排列顺序:
,考虑位置编号 的两种排列顺序:
当 时,有:

对于第一种排列,条件概率分布 ,其物理意义为:在序列第二个
token为、第五个 token为 的条件下,第一个token为 的概率分布。对于第二种排列,条件概率分布 ,其物理意义为:在序列第二个
token为、第五个 token为 的条件下,第四个token为 的概率分布。对于标准
Transformer,有:因此当已知第二个
token 和第五个 token,无论预测目标位置是第一个位置(对应于 )还是第四个位置(对应于 ),其概率分布都相同。实际上,对于不同的目标位置,其概率分布应该是不同的。该问题产生的本质原因是:
 未能考虑预测目标 的位置,当 代表第一个
未能考虑预测目标 的位置,当 代表第一个 token,与 代表第四个token,其分布应该不同。解决该问题的方式是:对预测目标
token引入位置信息。重新定义条件概率分布:

其中 定义了序列的一个新的
representation,它考虑了目标位置 。
。如上述例子中:
排列顺序 中,预测
 的条件概率分布为:
的条件概率分布为:排列顺序
 中,预测 的条件概率分布为:
中,预测 的条件概率分布为:
由于 ,因此不同的目标位置,其概率分布会不同。
问题是:如何定义一个合理的
 函数。
函数。当预测 之后的
token 时, 必须对
时, 必须对  进行编码,从而为预测 提供上下文。
进行编码,从而为预测 提供上下文。即:对于预测位置
 的
的token, 必须对 进行编码。
进行编码。
总而言之,是否对 进行编码依赖于当前预测的目标单词的位置
 。但是
。但是 Transformer中,每个token的embedding信息和位置的embedding信息在一开始就融合在一起。解决这一对冲突的方法时
two-stream self attention机制:content stream:提供了内容表达content representation,记作 ,它类似于标准
,它类似于标准 Transformer中的隐状态向量,编码了上下文和 本身。
其中 为
 的内容隐状态向量,它是 维列向量。
的内容隐状态向量,它是 维列向量。query stream:提供了查询表达content representation ,记作 ,它仅编码了 的上下文及其位置 ,并未编码 本身。
,记作 ,它仅编码了 的上下文及其位置 ,并未编码 本身。其中
 为 的
为 的 query隐状态向量,它是 维列向量。
维列向量。
双路
Self-Attention的更新规则:第一层的
query状态向量通过一个参数 来初始化: ,其中 是待学习的参数。
,其中 是待学习的参数。第一层的
content状态向量通过word embedding初始化: 。
。对每一个
self-attention层, ,这两路self-attention通过共享参数来更新:
其中
Attention的计算规则与BERT的Self-Attention一致。query-stream状态更新如下图所示:位置 的query状态更新只可能用到 位置的内容信息(不包括它自身)。
位置的内容信息(不包括它自身)。content-stream状态更新如下图所示:位置 的 content状态更新用到 位置的内容信息(包括它自身)。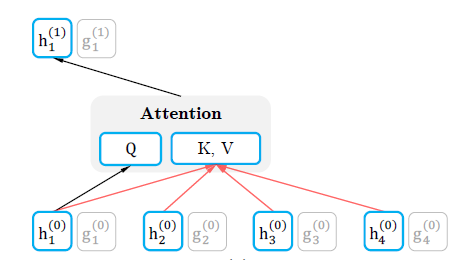
位于最后一层的、位置 的
query状态向量就是我们想要的 函数。- 通过前面定义的
Attention机制,它包含了 位置的内容信息(不包括它自身)。 - 通过指定位置 处的
query状态向量(而不是指定其它位置),它包含了位置 的位置信息。
- 通过前面定义的
整体更新示意图如下所示:
采样顺序为
 ,
,Attention Masks第k行表示 的上下文。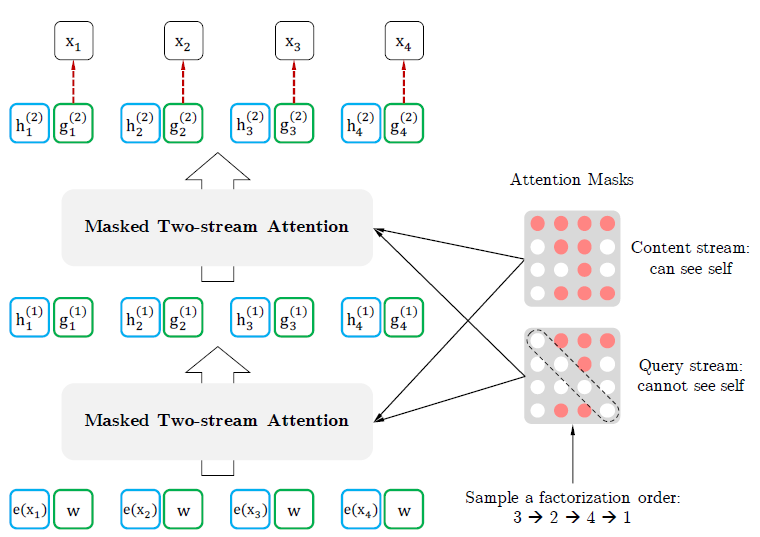
微调阶段:仅仅使用
content stream self-attention,并采用Transformer-XL的推断机制。
7.4 Partial Prediction
permutation language model会带来优化困难:由于位置排列的各种组合导致收敛速度很慢。为解决该问题,模型仅预测位置排列 最后面的几个位置对应的
token。首先根据拆分点
 拆分 为:
拆分 为: (不预测)、 (预测)。
(不预测)、 (预测)。然后调整模型的优化目标为:

这称作 部分预测。
对于拆分点之前的
token,无需计算它们的query representation,这会大大节省内存,降低计算代价。部分预测选择后半部分来预测的原因是:
- 后半部分的
token具有较长的上下文,使得上下文信息更丰富,从而为模型提供了更丰富的输入特征,更有利于模型对上下文的特征抽取。 - 推断阶段,真实的序列一般都具有较长的上下文。根据第一点的结论,模型更有利于对这些序列的特征抽取。
- 后半部分的
拆分点 的选择由超参数
 来选择。定义:
来选择。定义:即:拆分点之后的
token数量比上总token数量等于 。 越大,则需要预测的
。 越大,则需要预测的 token数量越少。
考虑到
XLNet是自回归语言框架,天然的匹配Transformer-XL思想,因此引入Transformer XL。这也是XLNet的名字的由来。具体而言,
XLNet引入了 相对位置编码和segment-level递归机制。XLNet引入相对位置编码比较简单,它直接采用了Transformer XL中的做法。XLNet引入segment-level递归机制比较复杂,因为XLNet中需要考虑位置的重排。令一个很长的文本序列中前后相邻的两个
segment为:
令位置编号 重排后的结果为
 , 重排后的结果为
, 重排后的结果为  。
。计算
content stream:首先基于 来处理前一个
segment,,并缓存每一层的隐向量 。
。然后基于 来处理后一个
segment,并计算每一层的隐向量:
其中
[]表示沿着序列维度拼接。其中相对位置编码仅仅依赖于原始的序列位置,而不是重排后的顺序。因此 中各状态向量的位置对应于原始的排列顺序。
因此一旦获取了
 ,上述
,上述 Attention的计算就独立于 。这使得缓存 时,不必关心前一个
时,不必关心前一个 segment的混排顺序。
计算
query stream:和content stream处理方式相同。
7.6 多输入
许多下游任务有多个输入部分,如
QA任务的输入包含两部分:一个question、以及包含answer的一段话。类似
BERT,XLNET将这两部分输入A和B拼接成一个整体 :[A,SEP,B,SEP,CLS]。 其中SEP作为这两部分的分隔符,CLS作为整体的标记符。在
segment-level递归阶段,每个部分只使用对应上下文的状态缓存。与
BERT采用segment绝对编码不同,XLNet基于Transformer-XL的思想,采用相对segment编码relative segment encoding:RES。给定序列的两个位置
i,j,如果二者在同一个部分,则使用相同的segment编码 ;否则使用不同的segment编码 。即:只考虑两个位置是否在同一个输入部分,而不考虑每个位置来自于哪个输入部分。
。即:只考虑两个位置是否在同一个输入部分,而不考虑每个位置来自于哪个输入部分。其中:
 为
为 query向量- 是一个待学习的参数,表示偏置向量
 是为标准的
是为标准的 attention score的一部分
相对
segment编码的优点:泛化效果较好。
支持预训练期间两部分输入、但微调期间多部分输入的场景。
绝对
segment编码不支持这种场景,因为预训练期间它只对绝对位置Seg 1,Seg 2编码,而微调期间的Seg3,...编码是未知的。
7.1.1 BERT vs XLNet
BERT和XLNet都只是预测序列中的部分token。BERT只能预测部分token,因为如果预测序列中的所有token,则它必须把所有token给mask。此时的输入全都是mask,无法学到任何东西。XLNet通过部分预测来降低计算代价,提高收敛速度。
BERT和XLNet的部分预测都要求上下文足够长,这是为了降低优化难度,提高收敛速度。独立性假设使得
BERT无法对mask token的关系建模。对于句子
New York is a city,假设BERT和XLNet对New York建模: 。对于
BERT,其目标函数为:
假设
XLNet的混排顺序为:a is city New York。则对应的目标函数为:
因此
XLNet能够捕捉到(New,York)之间的依赖性,而BERT无法捕捉。虽然
BERT能够捕捉到(New,city)、(York,city)这类依赖性,但是很显然XLNet也可以。给定一个序列
,定义序列 的一组目标 token的集合为 ,对应的非目标
,对应的非目标 token的集合为 。BERT和XLNet都是最大化 :
:XLNet的目标函数:其中
 表示位置重排之后,排列在 位置之前的那些单词。
表示位置重排之后,排列在 位置之前的那些单词。
可以看到:对于
XLNet,目标单词 不仅可以捕捉到非目标
不仅可以捕捉到非目标 token集合 中的token的相关性,还可以捕捉到目标token集合 中的部分 token的相关性。
7.7.2 AR VS XLNet
传统的自回归语言模型只已知前文来预测后文,而无法根据后文来预测前文。这种局限性在实际任务中可能会遇到。
如:给一段话
Thom Yorke is the singer of Radiohead,给一个问题Who is the singer of Radiohead。由于
Thom Yorke出现在序列的前面,因此在传统自回归语言模型中它不依赖于Radiohead。因此难以获得正确答案。由于
XLNet引入了位置全排列,因此它可以对任意顺序建模,即不仅可以对 建模,也可以对 建模。
建模。
7.8 实验
7.8.1 数据集和超参数
XLNet-Large与 拥有相同的结构超参数,因此具有差不多的模型大小。XLNet-Base与BERT--Base拥有相同的结构超参数,因此也具有差不多的模型大小。XLNet-Large预训练语料库:与BERT一致,XLNet使用BooksCorpus和英文维基百科作为预训练语料库,一共13 GB的纯文本。除此之外,
XLNet还包括Giga5(16GB纯文本)、ClueWeb 2012-B、Common Crawl语料库来预训练。XLNet使用启发式过滤策略来去掉ClueWeb 2012-B和Common Crawl中的太短或者低质量的文章,最终分别包含19GB纯文本和78 GB纯文本。- 在使用
SentencePiece词干化之后,最终维基百科、BooksCorpus,Giga5,Clueweb,Common Crawl分别获取了2.78B,1.09B,4.75B, 4.30B,19.97B的subword pieces,一共32.89B。
XLNet-Base预训练语料库:仅仅在BookCorpus和维基百科上预训练。训练参数:
序列长度 512,
memory length(用于segment-level递归的缓存状态向量) 384 。XLNet-Large在 512 块TPU v3芯片上训练 50万步,采用Adam optimizer和线性学习率衰减,batch size为 2048,一共大约 2.5天。实验观察表明:训练结束时模型仍然欠拟合,继续训练虽然能够降低预训练损失函数,但是无法改善下游任务的表现。这表明模型仍然没有足够的能力来充分利用大规模的数据。
但是在论文并没有预训练一个更大的模型,因为代价太大且对下游任务的微调效果可能提升有限。
XLNet-Large中,部分预测的常数K=6。由于引入
segment-level递归机制,论文使用了双向数据输入pipeline,其中前向和后向各占批处理大小的一半。
span-based predicition:- 首先采样一个长度 。
- 然后随机选择一个连续的长度为
B的区间的token作为预测目标 - 最后选择包含该区间的
 长度的一段
长度的一段 token作为一个序列样本。
7.8.2 实验结果
RACE数据集:包含了12到18岁中国初中、高中英语考试中的近10万个问题,答案由人工专家生成。涉及到挑战性的推理问题,所以它是最困难的阅读理解数据集之一。另外,该数据集每篇文章平均超过300个段落,远远超过其它流行的阅读理解数据集(如
SQuAD) 。 因此该数据集对于长文本理解来说是个具有挑战性的baseline。XLNet在该数据集上的微调结果如下图所示,其中:- 微调阶段的序列长度为 640
- 所有
BERT和XLNet都是在 24层网络下实现,其模型大小几乎相同。 *表示使用了多个训练模型的集成(取均值);Middle和High表示初中和高中水平的难度。
XLNet在该数据集上相比BERT提升巨大的原因可能有两个:XLNet的自回归语言模型解决了BERT的两个缺点:预测目标独立性假设、预训练阶段和微调阶段不一致 。XLNet引入Transformer-XL提升了长文本建模能力。
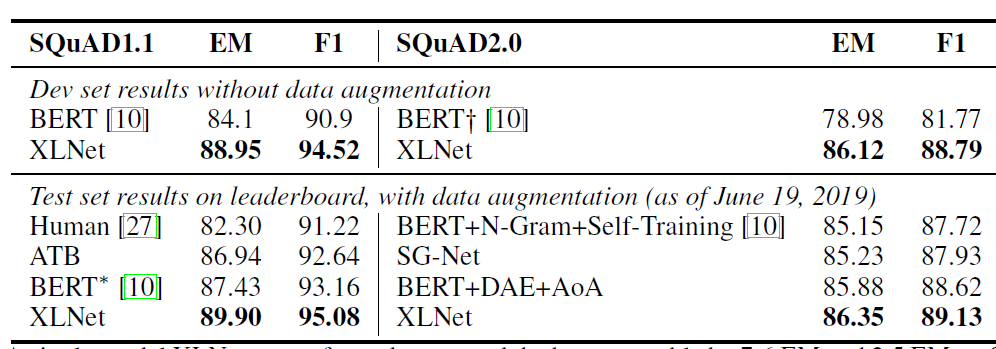
SQuAD数据集:一个大型阅读理解数据集,包含SQuAD 1.1和SQuAD 2.0。其中SQuAD 1.1中的问题总是有答案,而SQuAD 2.0中的问题可能没有答案。为了微调
SQuAD 2.0,论文联合使用了两个损失函数:- 一个逻辑回归的损失函数,用于预测该问题是否有答案。这是一个文本分类问题。
- 一个标准的
span extraction loss用于预测答案的位置。
XLNet在该数据集上的微调结果如下图所示:*表示集成模型(多个模型的平均输出)前两行直接比较
BERT和XLNET,没有采用数据集增强,直接在验证集上的比较。验证集采用
SQuQD 1.1。由于SQuAD 1.1始终有答案 ,因此评估时模型只考虑span extraction loss这一路的输出。后四行采用了数据集增强,通过
NewsQA来增强数据。因为排行榜排名靠前的模型都采取了数据集增强。结果在排行榜的测试集上评估。
文本分类任务:
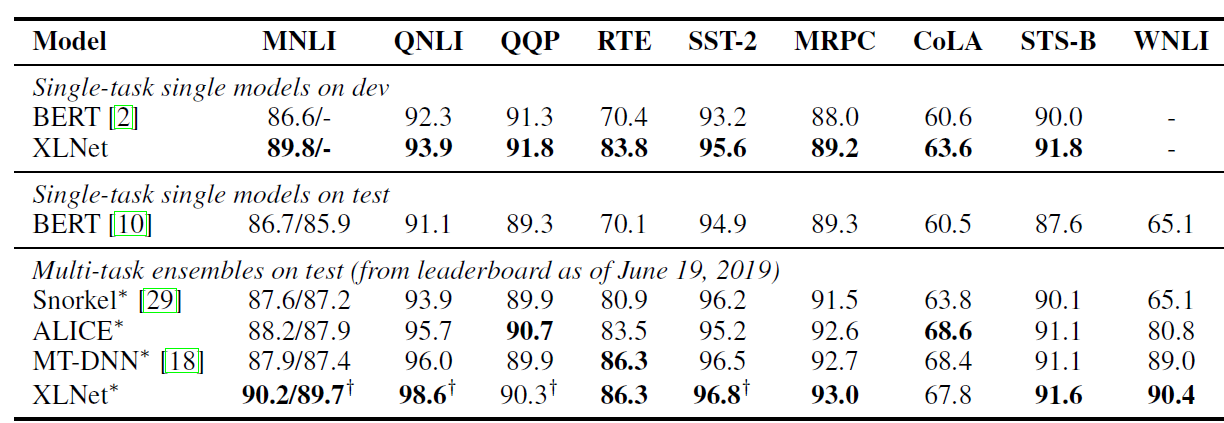
XLNet在IMDB,Yelp-2,Yelp-5,DBpedia,AG,Amazon-2,Amazon-5等数据集上的表现如下。GLUE数据集:9 个 NLP 任务的集合。XLNet的表现如下图所示。前三行表示单任务单模型的表现:针对每个任务,使用该任务的数据微调一个模型。
最后四行表示多任务集成模型的表现:
多任务:先在多个任务的数据集上联合训练模型,并在其它任务的数据集上微调网络。
其中
XLNet采用MNLI,SST-2,GNLI,QQP这四个最大的数据集来联合训练。集成模型:用不同的初始化条件训练多个模型,并用这些模型的平均输出作为最终输出。
BERT和XLNet采用 24 层网络,其模型大小相差无几。
ClueWeb09-B数据集:包含了TREC 2009-2012 Web Tracks,一共5千万doc及其query,用于评估的文档排序doc ranking能力。该任务是用标准检索方法对检索到的前100份文档进行rerank。由于文档排序主要涉及到文档的低层表示而不是高层语义,因此该数据集用于评估词向量质量。
论文使用预训练的
XLNet来提取doc和query的词向量,无需微调阶段,结果如下图所示。结果表明:
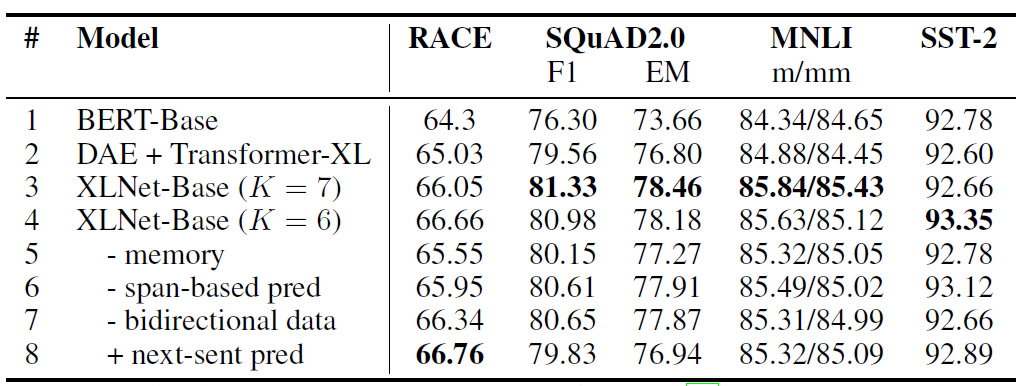
XLNet比BERT学到了更好的低级词向量。消融实验主要验证了以下几个目的:
- 相比较于
BERT的自编码语言模型,XLNet的Permutation Language Model是否有效。 - 是否有必要引入
Transformer-XL及其segment-level递归。 - 一些实现细节:
span-based predicition, 双向输入piepeline,next-sentence-predicition的必要性。
所有模型都在维基百科和
BooksCorpus数据集上预训练,模型采用 12层Base模型。实验结果如下图所示。结果表明:- 从第一/二行的比较来看:
Transformer-XL在长文本上表现优异。 - 从第四/五行的比较来看:如果没有内存缓存机制则性能下降,对于长文本任务尤为明显。
- 从第四/六/七行的比较来看:如果放弃
span-based predicition和 双向输入pipeline,则效果也会下降。 - 论文意外发现:
NSP任务不一定能改善性能;相反,除了 任务之外它会损害性能。
- 相比较于

