
- 基于 Java 开发的一个分布式应用程序协调服务
- 采用树状结构对数据进行存储(类似 Linux 文件系统的节点模型)
- 使用场景:主从协调(监听主机节点的状态),服务器上下线动态感知,统一配置管理(监听配置文件节点的状态),统一名称服务,分布式锁(监听本节点的上一顺序节点的状态),分布式队列等
-
图 1 ZooKeeper的层级树状结构
- ZooKeeper 的每个节点称为 Znode,每个 Znode 有一个唯一的路径(以斜杠字符来开头)标识
- 每个 Znode 由 3 部分组成:stat(描述该 Znode 的版本、权限等信息)、data(与该 Znode 关联的数据)、children(该 Znode 下的子节点)
- Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session
- 当节点上的数据发生变化,或者其子节点发生变化时,基于 Watcher 机制,会发出相应的通知给订阅其状态变化的客户端(注意:ZooKeeper 的 Watcher 是一次性的)
- Znode 的类型
- 临时(ephemeral)节点:该节点将在创建这个节点的客户端断开连接后被删除,临时节点不允许有子节点
- 顺序(sequential)节点:在该节点名下附加一个单调递增数
- ZooKeeper 集群间通过 Zab(Zookeeper Atomic Broadcast)协议来保持数据的一致性
- 该协议包括两个阶段:leader election 阶段和 Atomic broadcas 阶段
- 集群中将选举出一个 leader,其他的机器则称为 follower,所有的写操作都被传送给 leader,并通过 broadcas 将所有的更新告诉 follower
- 当 leader 崩溃或者 leader 失去大多数的 follower 时,需要重新选举出一个新的 leader,让所有的服务器都恢复到一个正确的状态
- 当 leader 被选举出来,且大多数服务器完成了和 leader 的状态同步后,leader election 的过程就结束了,将进入 Atomic broadcas 的过程
Atomic broadcas 同步 leader 和 follower 之间的信息,保证 leader 和 follower 具有相同的系统状态
ZooKeeper 提供的原语服务:创建节点、删除节点、更新节点、获取节点信息、权限控制、事件监听
help:查看 zkCli 命令
- get [-w] path:获取 Znode 数据(监视该节点的变化,只监视一次)
- set path data:设置数据
- ls [-s] [-w] [-R] path:列出 Znode 的子节点(-s 状态、-w 监视该节点的节点结构、-R 递归)
- stat [-w] path:检查状态(包含时间戳,版本号,ACL,数据长度和子 Znode 等细项)
- delete [-v version] path:删除指定的 Znode,适用于没有子节点的 Znode
- deleteall path:删除指定的 Znode 并递归其所有子节点
- close
- 第三方客户端工具包 ZkClient、Curator
- 客户端连接 Zookeeper 服务的端口默认是 2181
- Zookeeper 内嵌的管理控制台通过 Jetty 启动,默认端口是 8080
原理
- 利用其 Znode 的特点和 Watcher 机制,实现服务动态注册、机器上线与下线的动态感知,扩容方便,容错性好
- 一旦服务器(服务提供者)与 ZooKeeper 集群断开连接,节点也就不存在了,通过注册相应的 Watcher,服务消费者能够第一时间获知服务提供者机器信息的变更
- 只有当配置信息更新时服务消费者才会去 ZooKeeper 上获取最新的服务地址列表,其它时候使用本地缓存,能大大降低配置中心的压力
服务配置中心节点树
- 服务配置中心节点树分成三层结构
- 最上面一层为根节点,用来聚集服务节点,通过它可以查询到所有的服务
- 服务名称节点挂载的是服务提供者的服务器地址,服务消费者通过负载均衡算法来选择其中一个地址发起远程调用
- 根节点和服务名称采用的是 ZooKeeper 的持久节点(persistent 节点)
服务提供者的地址节点,采用的是非持久节点(ephemeral 节点),一旦服务器宕机或者下线,节点也就随之消失
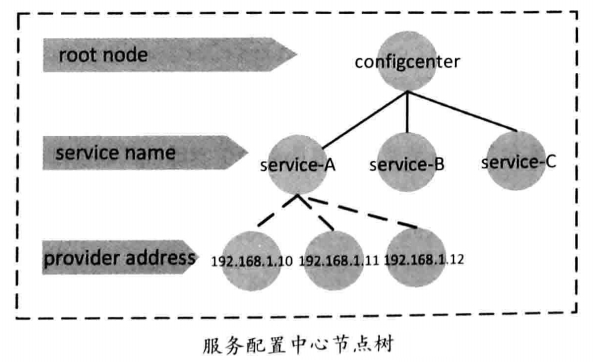
图 3 服务配置中心节点树

使用 ZooKeeper 实现分布式锁
- 在 ZooKeeper 指定节点(locker)下创建临时顺序节点 node_n
- 获取 locker 下所有子节点 children
- 对子节点按节点自增序号从小到大排序
- 判断本节点是不是第一个子节点,若是,则获取锁;若不是,则等待
- 使用 ZooKeeper 感知节点的功能,对本节点的上一个节点进行感知
- 释放锁,并删除该临时节点

