
Overview
You can find the documentation for each module in our codebase in our
API documentation.
Dopamine is organized as follows:
contains agent implementations.atari
contains Atari-specific code, including code to run experiments and
preprocessing code.
contains additional helper functionality, including logging and
checkpointing.replay_memory
contains the replay memory schemes used in Dopamine.
contains code used to inspect the results of experiments, as well as example
colab notebooks.
The whole of Dopamine is easily configured using the
gin configuration framework.
We provide a number of configuration files for each of the agents. The main
configuration file for each agent corresponds to an “apples to apples”
comparison, where hyperparameters have been selected to give a standardized
performance comparison between agents. These are
dopamine/agents/rainbow/configs/c51.gindopamine/agents/implicit_quantile/configs/implicit_quantile.gin
More details on the exact choices behind these parameters are given in our
.
We also provide configuration files corresponding to settings previously used in
the literature. These are
dopamine/agents/dqn/configs/dqn_nature.gin
()dopamine/agents/dqn/configs/dqn_icml.gin
()dopamine/agents/rainbow/configs/c51_icml.gin
()dopamine/agents/implicit_quantile/configs/implicit_quantile_icml.gin
()
Dopamine provides basic functionality for performing experiments. This
functionality can be broken down into two main components: checkpointing and
logging. Both components depend on the command-line parameter base_dir,
which informs Dopamine of where it should store experimental data.
Checkpointing
By default, Dopamine will save an experiment checkpoint every iteration: one
training and one evaluation phase, following a standard set by Mnih et al.
Checkpoints are saved in the checkpoints subdirectory under base_dir. At a
high-level, the following are checkpointed:
- Experiment statistics (number of iterations performed, learning curves,
etc.). This happens in
,
in the methodrun_experiment. - Agent variables, including the tensorflow graph. This happens in
,
in the methodsbundle_and_checkpoint
and
. - Replay buffer data. Atari 2600 replay buffers have a large memory footprint.
As a result, Dopamine uses additional code to keep memory usage low. The
relevant methods are found indopamine/agents/replay_memory/circular_replay_buffer.py,
and are called
andload.
If you’re curious, the checkpointing code itself is in
.
Logging
At the end of each iteration, Dopamine also records the agent’s performance,
both during training and (if enabled) during an optional evaluation phase. The
log files are generated indopamine/atari/run_experiment.py
and more specifically in
,
and are pickle files containing a dictionary mapping iteration keys
(e.g., "iteration_47") to dictionaries containing data.
A simple way to read log data from multiple experiments is to use the providedread_experiment
method in
.
We provide a
colab
to illustrate how you can load the statistics from an experiment and plot them
against our provided baseline runs.
We provide a
where we illustrate how one can extend the DQN agent, or create a new agent from
scratch, and then plot the experimental results against our provided baselines.
DQN
The DQN agent is contained in two files:
- The agent class, in
dopamine/agents/dqn/dqn_agent.py. - The replay buffer, in
.
The agent class defines the DQN network, the update rule, and also the basic
operations of a RL agent (epsilon-greedy action selection, storing transitions,
episode bookkeeping, etc.). For example, the Q-Learning update rule used in DQN
is defined in two methods, _build_target_q_op and .
Rainbow and C51
The Rainbow agent is contained in two files:
- The agent class in
dopamine/agents/rainbow/rainbow_agent.py,
inheriting from the DQN agent. - The replay buffer in
,
inheriting from DQN’s replay buffer.
The C51 agent is a specific parametrization of the Rainbow agent, whereupdate_horizon (the n in n-step update) is set to 1 and a uniform replay
scheme is used.
Implicit quantile networks (IQN)
The IQN agent is defined by one additional file:
- The raw logs are available
here- You can view this
for instructions on how to load and visualize them.
- You can view this
- The compiled pickle files are available
here- We make use of these compiled pickle files in both
and the
statistics
colabs.
- We make use of these compiled pickle files in both
- The Tensorboard event files are available
- We provide a
colab
where you can start Tensorboard directly from the colab usingngrok.
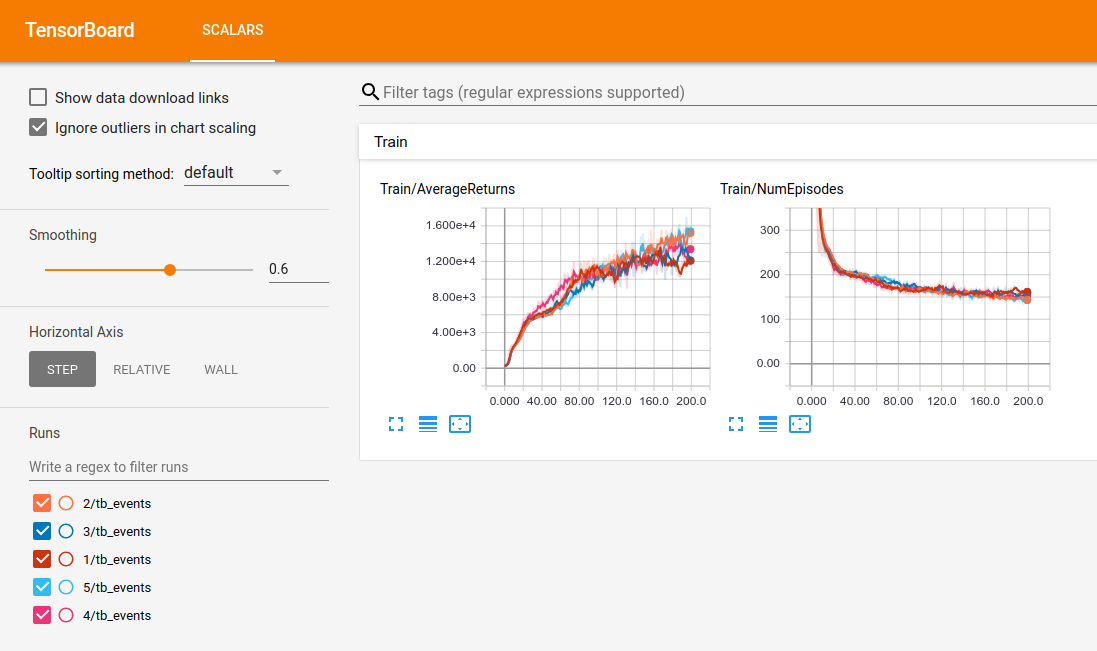
In the provided example your Tensorboard will look something like this:
- We provide a
- The TensorFlow checkpoint files for 5 independent runs of the 4 agents on
all 60 games are available. The format for each of the files is:https://storage.cloud.google.com/download-dopamine-rl/lucid/${AGENT}/${GAME}/${RUN}/tf_ckpt-199.${SUFFIX},
where:AGENTcan be “dqn”, “c51”, “rainbow”, or “iqn”.GAMEcan be any of the 60 games.RUNcan be 1, 2, 3, 4, or 5SUFFIXcan be one ofdata-00000-of-00001,index, ormeta.
- You can also download all of these as a single
.tar.gzfile. Note: these files are quite large, over 15Gb each.

