
部署负载均衡数据管道
教程 - 在 DC/OS 上构建完整的负载均衡数据管道
本教程演示如何在大约 15 分钟内在 DC/OS 上构建完整的负载均衡数据管道!
概述
在本教程中,您将安装和部署名为 Tweeter 的容器化 Ruby on Rails 应用程序。Tweeter 是类似于 Twitter 的应用程序,您可以使用该应用程序将 140 个字符的消息发布到互联网。然后,使用 Zeppelin 对由 Tweeter 创建的数据执行实时分析。
您将学习:
- 如何安装 DC/OS 服务
- 如何向 DC/OS Marathon 添加应用程序
- 如何通过 Marathon-LB 将公共流量发送到私有应用程序
- 如何发现您的应用程序
- 如何扩展您的应用程序
本教程使用 DC/OS 为群集启动和部署这些微服务:
数据库用于后端以存储 Tweeter 应用程序数据。
Kafka 发布订阅消息服务接收来自 Cassandra 的推文,并将它们发送到 Zeppelin 进行实时分析。
是一种基于 HAProxy 的负载均衡器,仅适用于 Marathon。当您需要外部路由或第 7 层负载均衡功能时,它非常有用。
Zeppelin 是一款交互式分析笔记本,可在后端与 DC/OS Spark 配合使用,以实现交互式分析和可视化。因为 Spark 和 Zeppelin 可能会占用所有群集资源,所以必须为 Zeppelin 服务指定最大内核数。
Tweeter 将推文存储在 DC/OS Cassandra 服务中,实时将推文流式传输到 DC/OS Kafka 服务,并使用 DC/OS 和 Zeppelin 服务执行实时分析。
在 DC/OS 群集上准备和部署 Tweeter
- DC/OS 或 已安装,至少具有 5 个专用代理节点 和 1 个。
- 公共代理节点的公共 IP 地址。在声明了公共代理节点的 DC/OS 已安装后,可以导航到公共代理节点的公共 IP 地址。
- Git:
- ** macOS:** 从 [Git 下载](
- Unix/Linux: 请参阅这些 安装说明。
在此步骤中,您可以从 DC/OS Web 界面 选项卡安装 Cassandra、Kafka、Marathon-LB 和 Zeppelin。您还可以使用 ]11 命令,从 DC/OS CLI 安装 DC/OS 软件包。
查找并单击 cassandra 软件包,单击 REVIEW & RUN,并通过再次单击 REVIEW & RUN,然后单击 RUN SERVICE,接受默认安装。Cassandra 最多可旋转 3 个节点。当模态警报提示时,单击 OPEN SERVICE。
单击 ** Catalog** 选项卡。查找并单击 kafka 软件包,单击 REVIEW & RUN按钮,然后再次单击该按钮,然后单击 RUN SERVICE。Kafka 最多旋转 3 个代理。当模态警报提示时,单击 OPEN SERVICE。
单击 ** Catalog** 选项卡。查找并单击 marathon-lb* 软件包,单击 REVIEW & RUN按钮,然后再次单击该按钮,然后单击 RUN SERVICE。当模态警报提示时,单击 OPEN SERVICE。
如果您在 Enterprise 群集上运行 Marathon-LB 时遇到问题,请尝试按照[这些说明]进行安装。(/mesosphere/dcos/cn/services/marathon-lb/latest/mlb-install/). 根据您的 ,Marathon-LB 可能需要服务身份认证才能访问 DC/OS。
单击 ** Catalog** 选项卡。单击 zeppelin 软件包,然后单击 REVIEW & RUN 按钮。
- 单击左侧的 spark 选项卡,并将
cores_max设置为8. - 单击 REVIEW AND RUN,然后单击 RUN。单击 OPEN SERVICE。
- 单击左侧的 spark 选项卡,并将
在 DC/OS 上部署您的微服务时,单击 Services(服务**)选项卡。当节点上线时,您将看到“运行状况”状态从“空闲”转为“不健康”,最后变为健康状态。这可能需要几分钟。
图 1. 显示 Tweeter 服务的服务选项卡
在此步骤中,您将容器化 Tweeter 应用程序部署到公共节点。
导航至 Tweeter GiThub 存储库并保存
/tweeter/tweeter.jsonMarathon 应用定义文件。将
HAPROXY_0_VHOST定义添加到tweeter.json文件中,该定义具有 节点的公共 IP 地址。在本示例中,DC/OS 群集正在 AWS 上运行:
...],"labels": {"HAPROXY_GROUP": "external","HAPROXY_0_VHOST": "52.34.136.22"}
导航至包含已修改
tweeter.json文件的目录。将 Tweeter 安装及部署到您的 DC/OS 群集中。中的
tweeter.json参数指定应用程序实例的数量。使用以下命令为应用程序增容或减容:dcos marathon app update tweeter instances=<number_of_desired_instances>
在本示例中,服务通过群集节点
node-0.cassandra.mesos:9042与 Cassandra 进行通信,通过群集节点broker-0.kafka.mesos:9557与 Kafka 进行通信。由于HAPROXY_0_VHOST应用定义文件中的tweeter.json定义,流量通过 Marathon-LB 传输。转到 Services 选项卡,验证您的应用程序是否正常运行。
图 2. 已部署的 Tweeter
导航到公共代理 节点端点以查看 Tweeter UI 并发布一篇推文。在本例中,您将浏览器指向
52.34.136.22.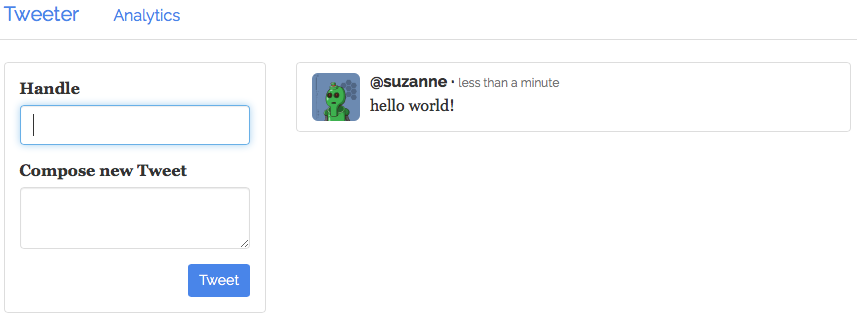
图 3. “Hello world”推文
在此步骤中,您部署的应用程序自动发布来自 Shakespeare 的大量推文。应用程序将逐个发布超过 10 万条推文,因此当您刷新页面时,您会看到它们稳定地进入。
导航至 GiThub 存储库并保存
tweeter/post-tweets.jsonMarathon 应用定义文件。在
post-tweets.json运行后,刷新您的浏览器,查看传入的 Shakespeare 推文。图 4. Shakespeare 推文
post-tweets 应用程序通过流式传输 VIP1.1.1.1:30000. 进行工作。此地址在 cmd 应用定义的 参数中声明。
{"id": "/post-tweets","cmd": "bin/tweet shakespeare-tweets.json http://1.1.1.1:30000",...}
Tweeter 应用程序使用安装在每个 DC/OS 节点上的服务发现和负载均衡器服务。此地址在 tweeter.json 定义 VIP_0. 中定义。
如果您正在使用 DC/OS Enterprise 群集,单击 DC/OS Web 界面中的 Networking -> Service Addresses 选项卡,然后选择 1.1.1.1:30000 虚拟网络,以查看正在执行的负载均衡:
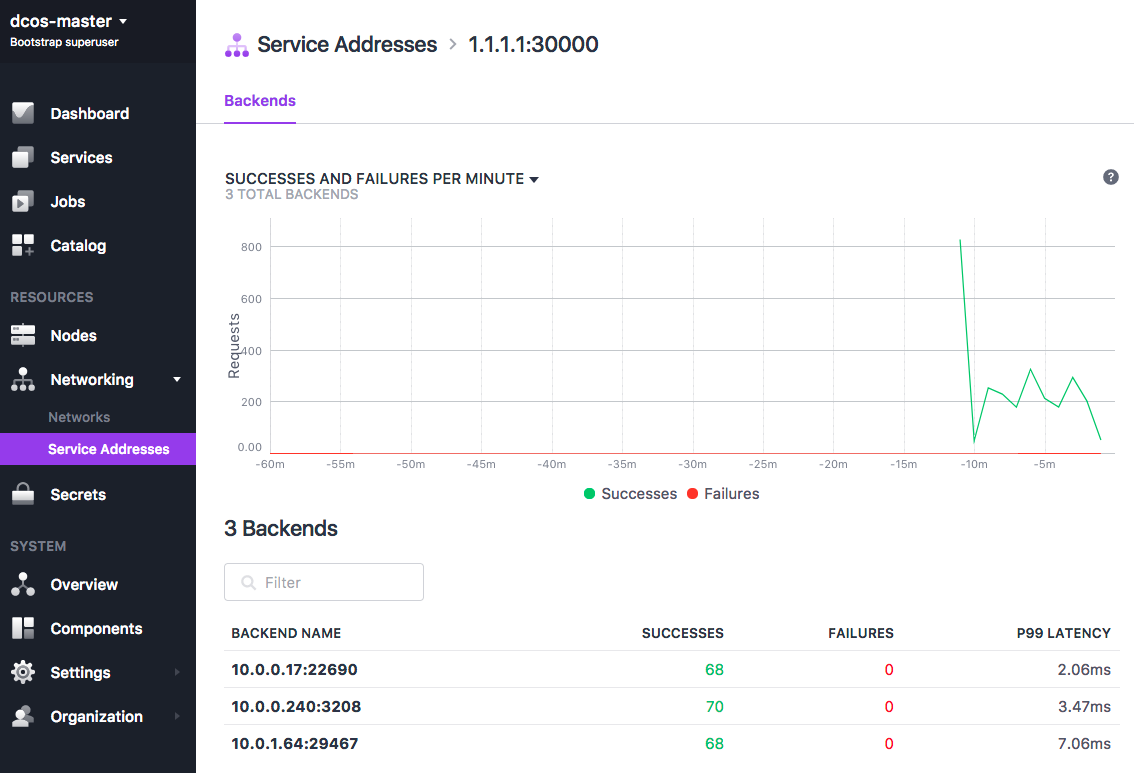
图 5. 扩展的推文
在最后一步中,您将对来自 Kafka 的推文流进行实时分析。
导航至 Tweeter GiThub 存储库并保存
tweeter/post-tweets.jsonMarathon 应用定义文件。导航至 中的 Zeppelin。
https://<master_ip>/service/zeppelin/. 您的主节点 IP 地址是 DC/OS Web 界面的 URL。单击 Import Note 并导入
tweeter-analytics.json. Zeppelin 已预先配置,以在 DC/OS 群集上执行 Spark 作业,因此无需进一步配置或设置。请务必使用https://而不是http://.导航至 Notebook -> Tweeter Analytics。
运行 Load Dependencies 步骤,将所需的库加载到 Zeppelin 中。
运行 Spark Streaming 步骤,其从 ZooKeeper 中读取推文流并将其放入可使用 SparkSQL 查询的临时表中。
运行 Top tweeter SQL 查询,其使用上一步中创建的表来计算每个用户的推文数。当新推文进入时,表会不断更新,因此重新运行查询会每次产生不同的结果。
图 6. Top Tweeters

