
Contents
- Overview
- The Circuit Breaker
- Resilience through Retrier
- Landscape overview
- Go code - adding circuit breaker and retrier
- Deploy & run
- Hystrix Dashboard and Netflix Turbine
- Turbine & Service discovery
- Summary
Source code
The finished source can be cloned from github:
1. Overview
Consider the following make-believe system landscape where a number of microservices handles an incoming request:
Figure 1 - system landscape
What happens if the right-most service “Service Y” fails? Let’s say it will accept incoming requests but then just keep them waiting, perhaps the underlying data storage isn’t responsive. The waiting requests of the consumer services (Service N & Service A) will eventually time out, but if you have a system handling tens or hundreds of requests per second, you’ll have thread pools filling up, memory usage skyrocketing and irritated end consumers (those who called Service 1) waiting for their response. This may even cascade through the call chain all the way back to the entry point service, effectively grinding your entire landscape to a halt.
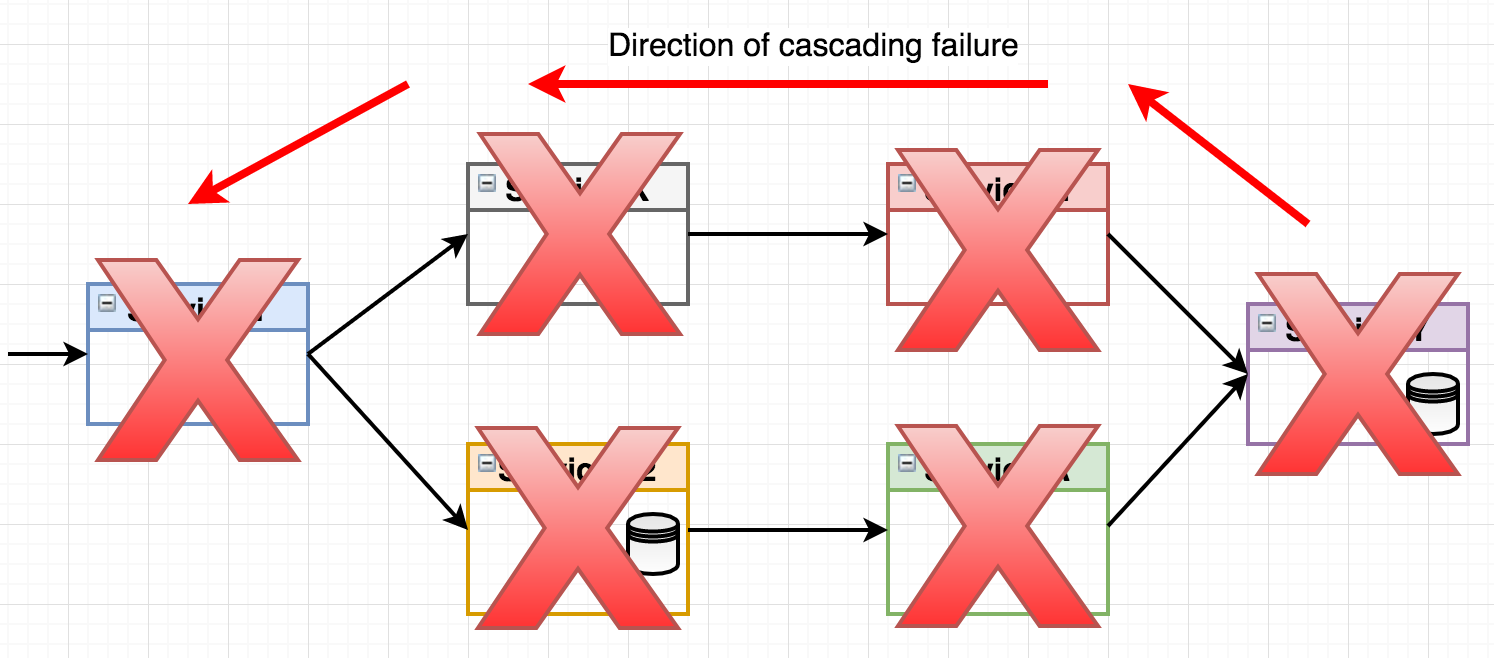 Figure 2 - cascading failure
Figure 2 - cascading failure
While a properly implemented healthcheck will eventually trigger a service restart of the failing service through mechanisms in the container orchestrator, that may take several minutes. Meanwhile, an application under heavy load will suffer from unless we’ve actually implemented patterns to handle this situation. This is where the circuit breaker pattern comes in.
2. The Circuit Breaker
Figure 3 - circuit breaker
Here we see how a circuit breaker logically exists between Service A and Service Y (the actual breaker is always implemented in the consumer service). The concept of the circuit breaker comes from the domain of electricity. Thomas Edison filed a patent application back in 1879. The circuit breaker is designed to open when a failure is detected, making sure cascading side effect such as your house burning down or microservices crashing doesn’t happen. The hystrix circuit breaker basically works like this:
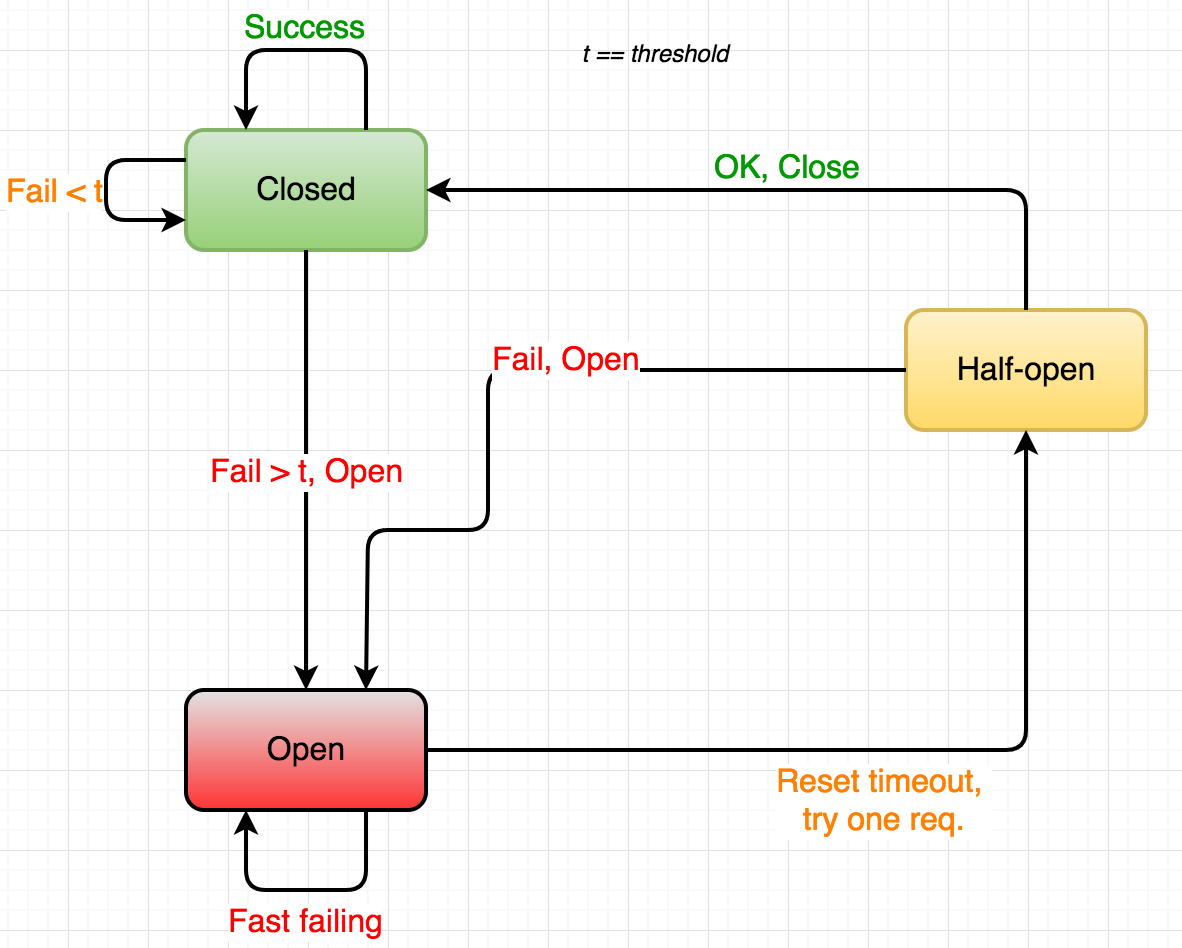 Figure 4 - circuit breaker states
Figure 4 - circuit breaker states
- Closed: In normal operation, the circuit breaker is closed, letting requests (or electricity) pass through.
- Open: Whenever a failure has been detected (n number of failed requests within a time span, request(s) taking too long, massive spike of current), the circuit opens, making sure the consumer service short-circuits instead of waiting for the failing producer service.
Half-open: Periodically, the circuit breaker lets a request pass through. If successful, the circuit can be closed again, otherwise it stays open.
There’s two key take-aways with Hystrix when the circuit is closed:Hystrix allows us to provide a fallback function that will be executed instead of running the normal request. This allows us to provide a fallback behaviour. Sometimes, we can’t do without the data or service of the broken producer - but just as often, our fallback method can provide a default result, a well-structured error message or perhaps calling a backup service.
- Stopping cascading failures. While the fallback behaviour is very useful, the most important part of the circuit breaker pattern is that we’re immediately returning some response to the calling service. No thread pools filling up with pending requests, no timeouts and hopefully less annoyed end-consumers.
3. Resilience through Retrier
The circuit breaker makes sure that if a given producer service goes down, we can both handle the problem gracefully and save the rest of the application from cascading failures. However, in a microservice environment we seldom only have a single instance of a given service. Why consider the first attempt as a failure inside the circuit breaker if you have many instances where perhaps just a single one has problems? This is where the retrier comes in:
In our context - using Go microservices within a Docker Swarm mode landscape - if we have let’s say 3 instances of a given producer service, we know that the Swarm Load-balancer will automatically round-robin requests addressed to a given service. So instead of failing inside the breaker, why not have a mechanism that automatically performs a configurable number of retries including some kind of backoff?
Figure 5 - retrier
Perhaps somewhat simplified - the sequence diagram should hopefully explain the key concepts:
- The retrier runs inside the circuit breaker.
- The circuit breaker only considers the request failed if all retry attempts failed. Actually, the circuit breaker has no notion of what’s going on inside it - it only cares about whether the operation it encapsulates returns an error or not.
In this blog post, we’ll use the package of go-resilience.
4. Landscape overview
In this blog post and the example code we’re going to implement later, we’ll add circuit breakers to the accountservice for its outgoing calls to the quotes-service and a new service called imageservice. We will also install services running the Netflix Hystrix and Netflix Turbine hystrix stream aggregator. More on those two later.
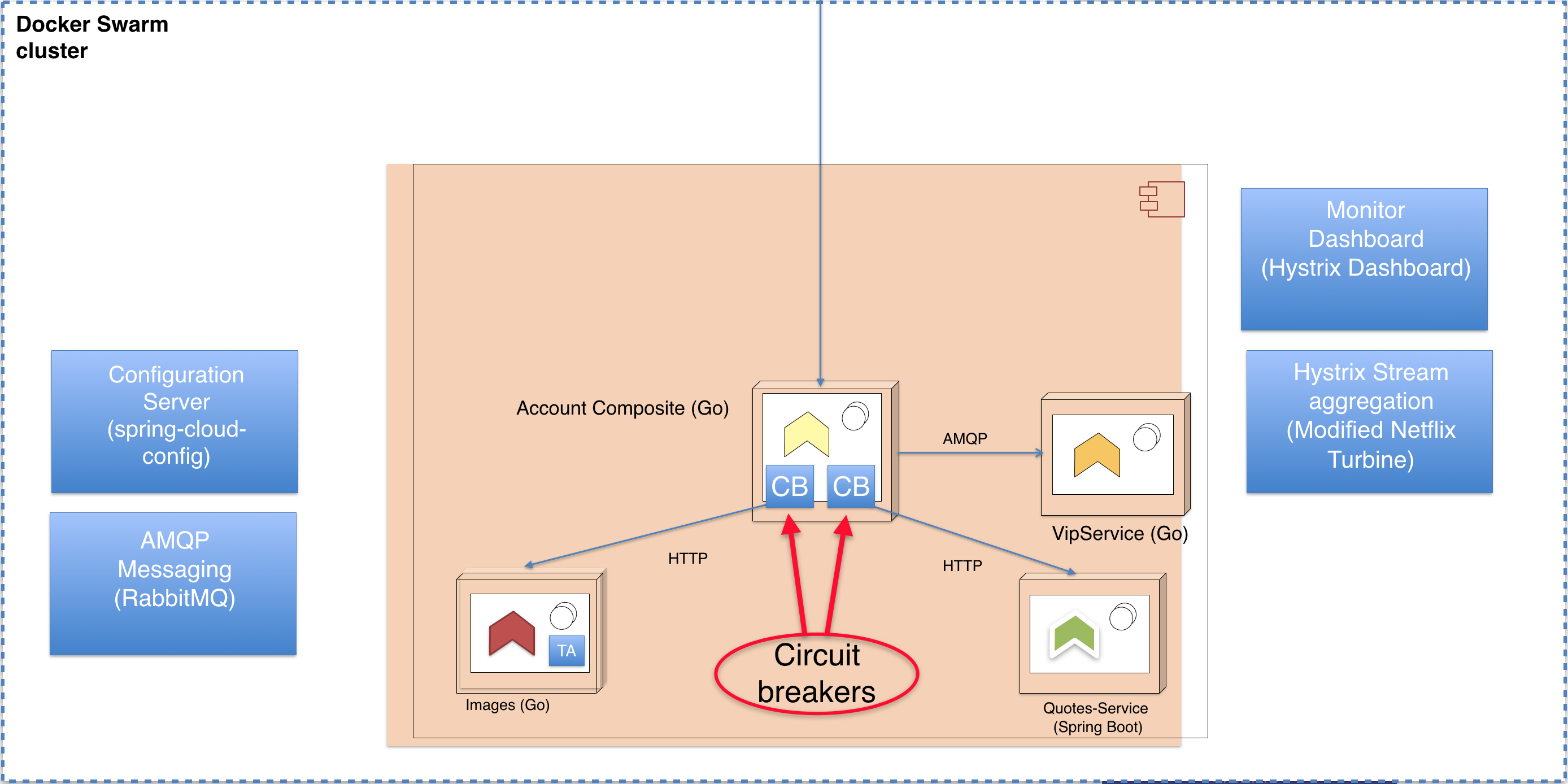 Figure 6 - landscape overview
Figure 6 - landscape overview
5. Go code - adding circuit breaker and retrier
Finally time for some Go code! In this part we’re introducing a brand new underlying service, the imageservice. However, we won’t spend any precious blog space describing it. It will just return an URL for a given “acountId” along with the IP-address of the serving container. It provides a bit more complexity to the landscape which is suitable for showcasing how we can have multiple named circuit breakers in a single service.
Let’s dive into our “accountservice” and the /goblog/accountservice/service/handlers.go file. From the code of the GetAccount func, we want to call the underlying quotes-service and the new imageservice using go-hystrix and go-resilience/retrier. Here’s the starting point for the quotes-service call:
body, err := cb.CallUsingCircuitBreaker("quotes-service", "http://quotes-service:8080/api/quote?strength=4", "GET")// Code handling response or err below, omitted for clarity...}
5.1 Circuit breaker code
The cb.CallUsingCircuitBreaker func is something I’ve added to our /common/circuitbreaker/hystrix.go file. It’s a bit on the simplistic side, but basically wraps the go-hystrix and retries libraries. I’ve deliberately made the code more verbose and non-compact for readbility reasons.
func CallUsingCircuitBreaker(breakerName string, url string, method string) ([]byte, error) {output := make(chan []byte, 1) // Declare the channel where the hystrix goroutine will put success responses.errors := hystrix.Go(breakerName, // Pass the name of the circuit breaker as first parameter.// 2nd parameter, the inlined func to run inside the breaker.func() error {req, _ := http.NewRequest(method, url, nil)// For hystrix, forward the err from the retrier. It's nil if successful.return callWithRetries(req, output)},// 3rd parameter, the fallback func. In this case, we just do a bit of logging and return the error.func(err error) error {logrus.Errorf("In fallback function for breaker %v, error: %v", breakerName, err.Error())circuit, _, _ := hystrix.GetCircuit(breakerName)logrus.Errorf("Circuit state is: %v", circuit.IsOpen())return err})// Response and error handling. If the call was successful, the output channel gets the response. Otherwise,// the errors channel gives us the error.select {case out := <-output:logrus.Debugf("Call in breaker %v successful", breakerName)return out, nilcase err := <-errors:return nil, err}}
As seen above, go-hystrix allows us to name circuit breakers, which we also can provide fine-granular configuration for given the names. Do note that the hystrix.Go func will execute the actual work in a new goroutine, where the result sometime later is passed through the unbuffered (e.g. blocking) output channel to the code snippet, which will effectively block until either the output or errors channels recieves a message.
func callWithRetries(req *http.Request, output chan []byte) error {// Create a retrier with constant backoff, RETRIES number of attempts (3) with a 100ms sleep between retries.r := retrier.New(retrier.ConstantBackoff(RETRIES, 100 * time.Millisecond), nil)// This counter is just for getting some logging for showcasing, remove in production code.attempt := 0// Retrier works similar to hystrix, we pass the actual work (doing the HTTP request) in a func.err := r.Run(func() error {attempt++// Do HTTP request and handle response. If successful, pass resp.Body over output channel,// otherwise, do a bit of error logging and return the err.resp, err := Client.Do(req)if err == nil && resp.StatusCode < 299 {responseBody, err := ioutil.ReadAll(resp.Body)if err == nil {output <- responseBodyreturn nil}return err} else if err == nil {err = fmt.Errorf("Status was %v", resp.StatusCode)}logrus.Errorf("Retrier failed, attempt %v", attempt)return err})return err}
5.3 Unit testing
I’ve created three unit tests in the /goblog/common/circuitbreaker/hystrix_test.go file which runs the CallUsingCircuitBreaker() func. We won’t go through all test code, one example should be enough. In this test we use gock to mock responses to three outgoing HTTP requests, two failed and at last one successful:
defer gock.Off()buildGockMatcherTimes(500, 2) // First two requests respond with 500 Server Errorbody := []byte("Some response")buildGockMatcherWithBody(200, string(body)) // Next (3rd) request respond with 200 OKhystrix.Flush() // Reset circuit breaker stateConvey("Given a Call request", t, func() {// Call single time (will become three requests given that we retry thrice)bytes, err := CallUsingCircuitBreaker("TEST", "http://quotes-service", "GET")Convey("Then", func() {// Assert no error and expected responseSo(err, ShouldBeNil)So(bytes, ShouldNotBeNil)So(string(bytes), ShouldEqual, string(body))})})})}
The console output of the test above looks like this:
The other tests asserts that hystrix fallback func runs if all retries fail and another test makes sure that the hystrix circuit breaker is opened if sufficient number of requests fail.
5.4 Configuring Hystrix
Hystrix circuit breakers can be configured in a variety of ways. A simple example below where we specifiy the number of failed requests that should open the circuit and the retry timeout:
hystrix.ConfigureCommand("quotes-service", hystrix.CommandConfig{SleepWindow: 5000,RequestVolumeThreshold: 10,})
See the for details. My /common/circuitbreaker/hystrix.go “library” has some code for automatically trying to pick configuration values fetched from the config server using this naming convention:
hystrix.command.[circuit name].[config property] = [value]
Example: (in accountservice-test.yml)
hystrix.command.quotes-service.SleepWindow: 5000
6. Deploy and run
In the git branch of this part, there’s updated microservice code and ./copyall.sh which builds and deploys the new imageservice. Nothing new, really. So let’s take a look at the circuit breaker in action.
In this scenario, we’ll run a little that by default will run 10 requests per second to the /accounts/{accountId} endpoint.
> go run *.go -zuul=false
(Never mind that -zuul property, that’s for a later part of the blog series.)
Let’s say we have 2 instances of the imageservice and quotes-service respectively. With all services running OK, a few sample responses might look like this:
If we kill the quotes-service:
> docker service scale quotes-service=0
We’ll see almost right away (due to connection refused) how the fallback function has kicked in and are returning the fallbackQuote:
{name":"Person_23","servedBy":"10.255.0.19","quote":{"quote":"May the source be with you, always.","ipAddress":"circuit-breaker"},"imageUrl":"http://imageservice:7777/file/cake.jpg"}
What’s a lot more interesting is to see how the application as a whole reacts if the quote-service starts to respond really slowly. There’s a little “feature” in the quotes-service that allows us to specify a hashing strength when calling the quotes-service.
http://quotes-service:8080/api/quote?strength=4
Such a request is typically completed in about 10 milliseconds. By changing the strength query-param to ?strength=13 the quotes-service will use a LOT of CPU and need slightly less than a second to complete. This is a perfect case for seeing how our circuit breaker reacts when the system comes under load and probably is getting CPU-starved. Let’s use Gatling for two scenarios - one where we’ve disabled the circuit breaker and one with the circuit breaker active.
No circuit breaker, just using the standard http.Get(url string):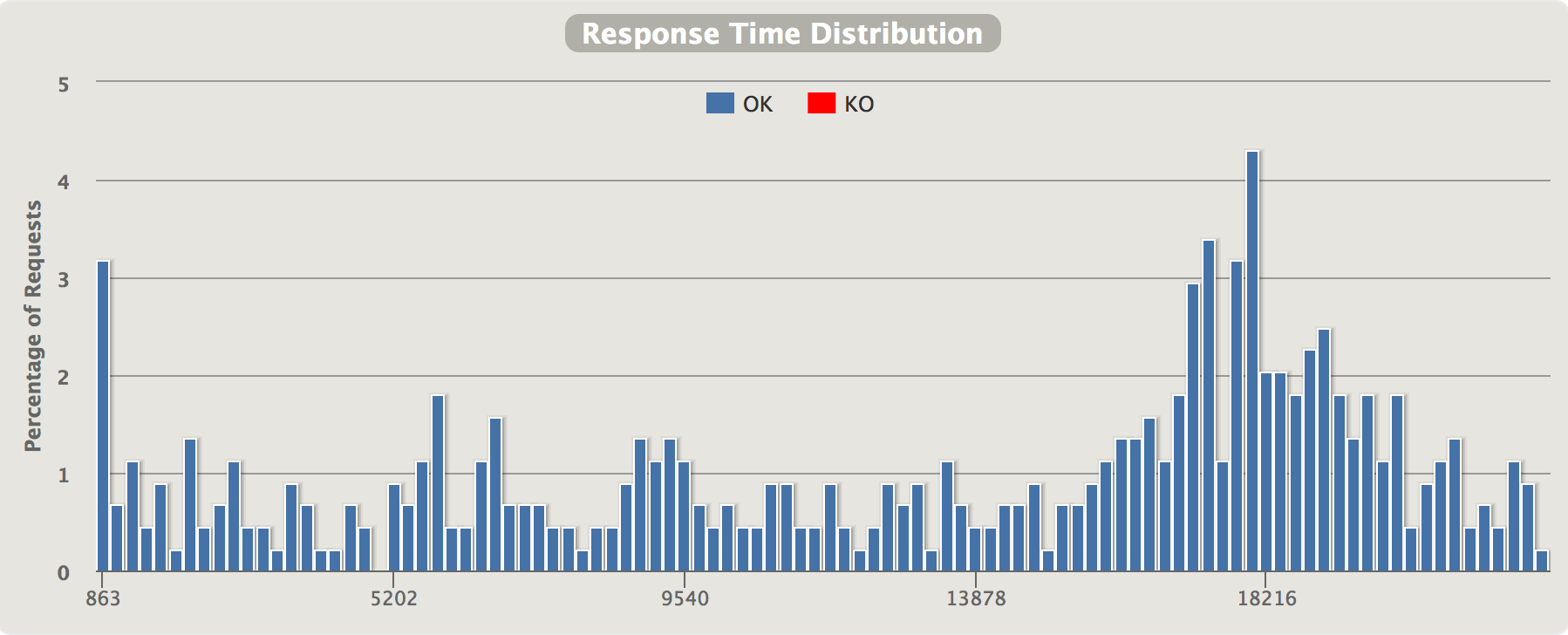
The very first requests needs slightly less than a second, but then latencies increases, topping out at 15-20 seconds per request. Peak throughput of our two quotes-service instances (both using 100% CPU) is actually not more than approx 3 req/s since they’re fully CPU-starved (and in all honesty - they’re both running on the same Swarm node on my laptop having 2 CPU cores shared across all running microservices).
6.2.2 With circuit breaker
Circuit breaker, with Timeout set to 5000 ms. I.e - when enough requests have waited more than 5000 ms, the circuit will open and the fallback Quote will be returned. (Note the tiny bars around the 4-5 second mark on the far right - that’s requests from when the circuit was in “semi-open”-state and a few of the early requests before the circuit opened)In this diagram, we see the distribution of response time halfway through the test. At the marked data point, the breaker is certainly open and the 95%th percentile is 10ms, while the 99%th percentile is over 4 seconds. In other words, about 95% of requests are handled within 10ms but a small percentage (probably half-open retries) are using up to 5 seconds before timing out.
(Note the tiny bars around the 4-5 second mark on the far right - that’s requests from when the circuit was in “semi-open”-state and a few of the early requests before the circuit opened)In this diagram, we see the distribution of response time halfway through the test. At the marked data point, the breaker is certainly open and the 95%th percentile is 10ms, while the 99%th percentile is over 4 seconds. In other words, about 95% of requests are handled within 10ms but a small percentage (probably half-open retries) are using up to 5 seconds before timing out.
During the first 15 seconds or so, the greenish/yellowish part, we see that more or less all requests are linearily increasing latencies approaching the 5000 ms threshold. The behaviour is - as expected - similar to when we were running without the circuit breaker. I.e. - requests can be successfully handled but takes a lot of time. Then - the increasing latencies trip the breaker and we immediately see how response times drops back to a few milliseconds instead of ~5 seconds for the majority of the requests. As stated above, the breaker lets a request through every once in a while when in the “half-open” state. The two quotes-service instances can handle a few of those “half-open” requsts, but the circuit will open again almost immediately since since the quotes-service instances cannot serve more than a few req/s before the latencies gets too high again and the breaker is tripped anew.
We see two neat things about circuit breakers in action here:
- The open circuit breaker keeps latencies to a minimum when the underlying quotes-service has a problem, it also “reacts” quite quickly - significantly faster than any healthcheck/automatic scaling/service restart will.
- The 5000 ms timeout of the breaker makes sure no user has to wait ~15 seconds for their response. The 5000 ms configured timeout takes care of that. (Of course, you can handle timeouts in other ways than just using circuit breakers)
7. Hystrix Dashboard and Netflix Turbine
One neat thing about Hystrix is that there’s a companion Web application called Hystrix Dashboard that can provide a graphical representation of what’s currently going on in the circuit breakers inside your microservices.
It works by producing HTTP streams of the state and statistics of each configured circuit breaker updated once per second. The Hystrix Dashboard can however only read one such stream at a time and therefore Netflix Turbine exists - a piece of software that collects the streams of all circuit breakers in your landscape and aggregates those into one data stream the dashboard can consume:
In Figure 7, note that the Hystrix dashboard requests the /turbine.stream from the Turbine server, and Turbine in it’s turn requests /hystrix.stream from a number of microservices. With Turbine collecting circuit breaker metrics from our accountservice, the dashboard output may look like this:
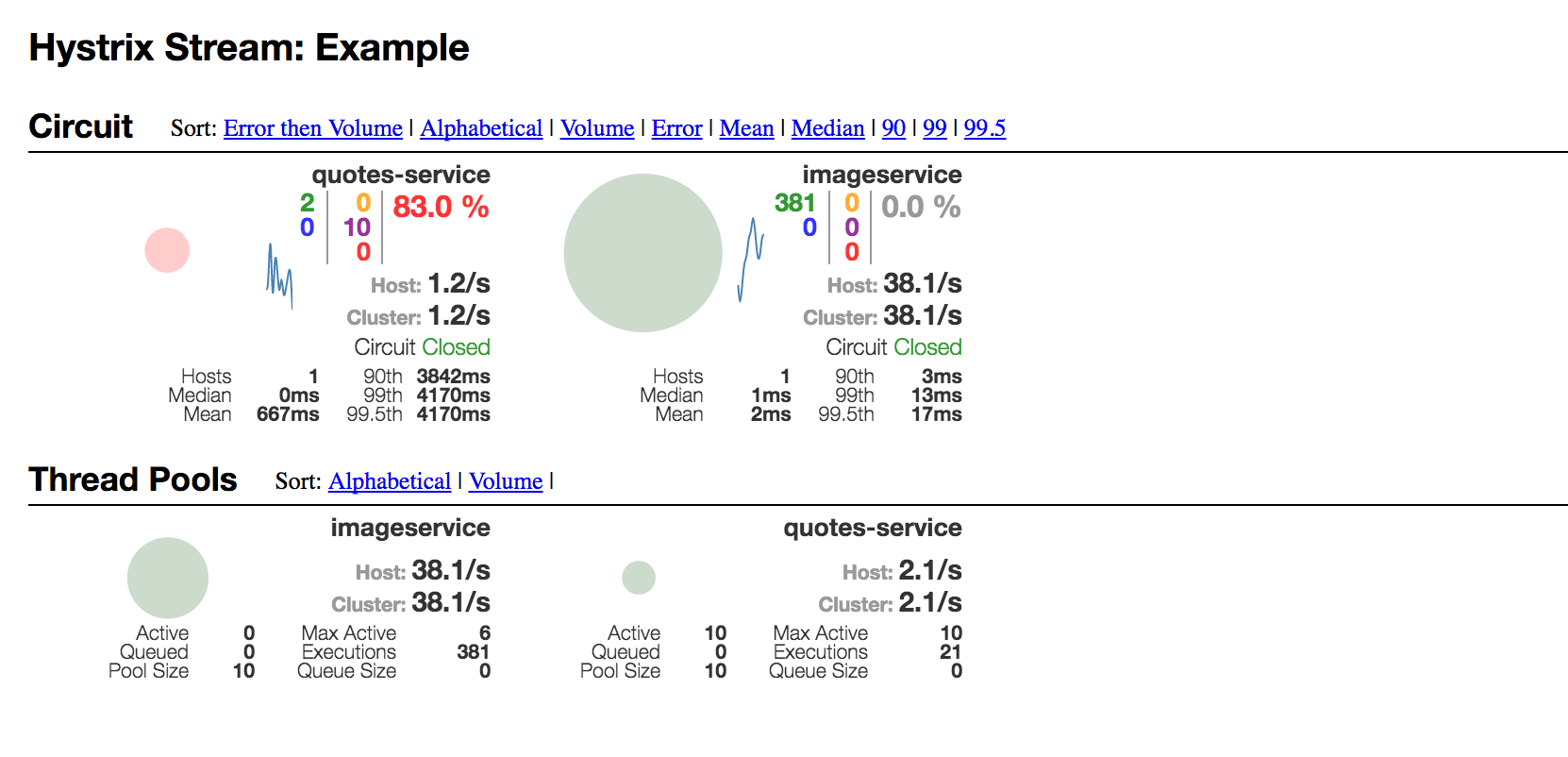 Figure 8 - Hystrix dashboard
Figure 8 - Hystrix dashboard
The GUI of Hystrix Dashboard is definitely not the easiest to grasp at first. Above, we see the two circuit breakers inside accountservice and their state in the middle of one of the load-test runs above. For each circuit breaker, we see breaker state, req/s, average latencies, number of connected hosts per breaker name and error percentages. Among things. There’s also a thread pools section below, though I’m not sure they work correctly when the root statistics producer is the go-hystrix library rather than a hystrix-enabled Spring Boot application. After all - we don’t really have the concept of thread pools in Go when using standard goroutines.
Here’s a short video of the “quotes-service” circuit breaker inside the accountservice when running part of the load-test used above: (click on the image to start the video)
All in all - Turbine and Hystrix Dashboard provides a rather nice monitoring function that makes it quite easy to pinpoint unhealthy services or where unexpected latencies are coming from - in real time. Always make sure your inter-service calls are performed inside a circuit breaker.
8. Turbine and Service Discovery
There’s one issue with using Netflix Turbine & Hystrix Dashboard with non-Spring microservices and/or container orchestrator based service discovery. The reason is that Turbine needs to know where to find those /hystrix.stream endpoints, for example . In an ever-changing microservice landscape with services scaling up and down etc, there must exist mechanisms that makes sure which URLs Turbine tries to connect to to consume hystrix data streams.
By default, Turbine relies on Netflix Eureka and that microservices are registering themselves with Eureka. Then, Turbine can internally query Eureka to get possible service IPs to connect to.
In our context, we’re running on Docker Swarm mode and are relying on the built-in service abstraction Docker in swarm mode provides for us. How do we get our service IPs into Turbine?
Luckily, Turbine has support for plugging in custom discovery mechanisms. I guess there’s two options apart from doubling up and using Eureka in addition to the orchestrator’s service discovery mechanism - something I thought was a pretty bad idea back in .
8.1.1 Discovery tokens
This solution uses the AMQP messaging bus (RabbitMQ) and a “discovery” channel. When our microservices having circuit breakers start up, they figure out their own IP-address and then sends a message through the broker which our custom Turbine plug-in can read and transform into something Turbine understands.
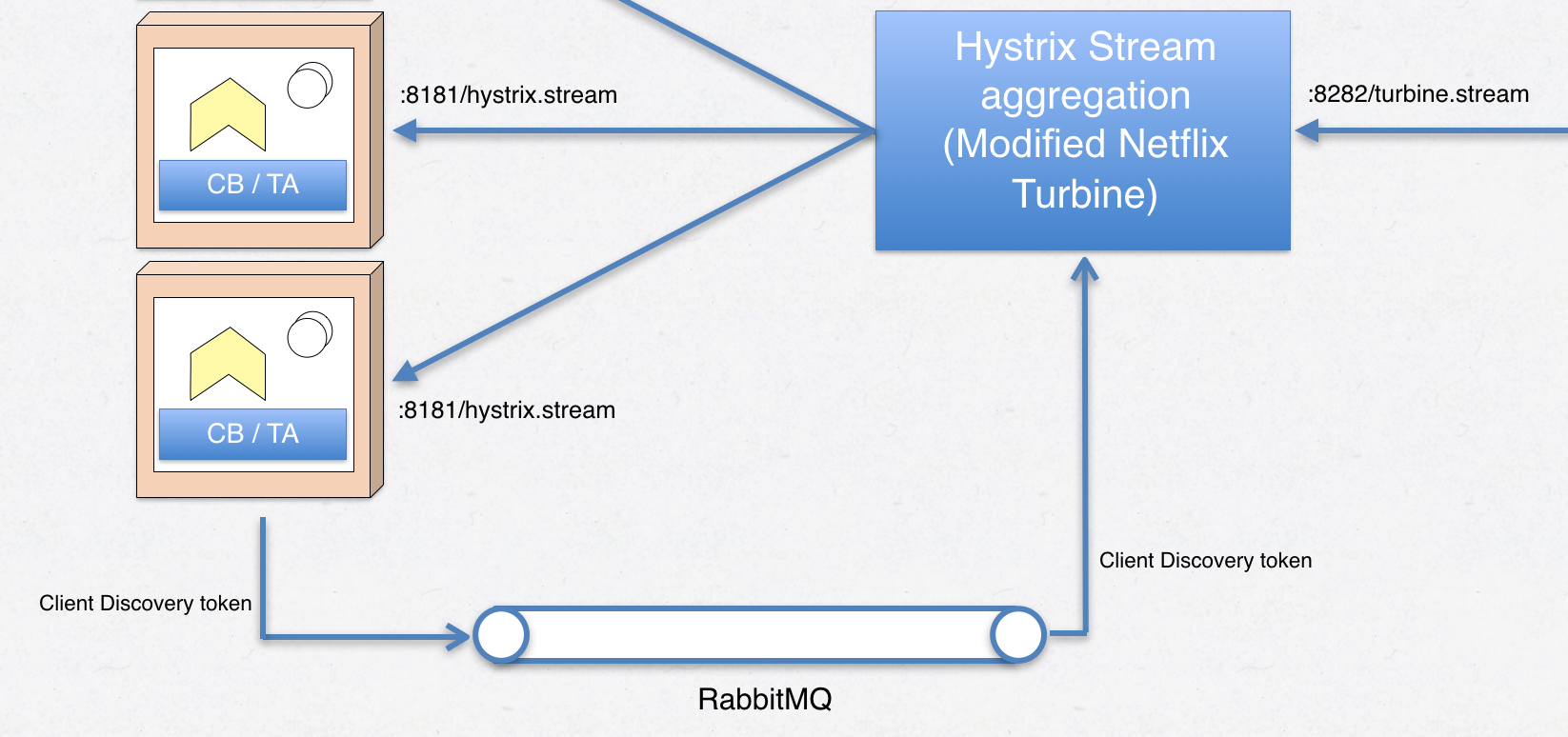 Figure 9 - hystrix stream discovery using messaging
Figure 9 - hystrix stream discovery using messaging
The registration code that runs at accountservice startup:
func publishDiscoveryToken(amqpClient messaging.IMessagingClient) {// Get hold of our IP adress (reads it from /etc/hosts) and build a discovery token.ip, _ := util.ResolveIpFromHostsFile()token := DiscoveryToken{State: "UP",Address: ip,}bytes, _ := json.Marshal(token)// Enter an eternal loop in a new goroutine that sends the UP token every// 30 seconds to the "discovery" channel.go func() {for {amqpClient.PublishOnQueue(bytes, "discovery")time.Sleep(time.Second * 30)}}()}
Full source of my little circuitbreaker library that wraps go-hystrix and go-resilience can be found here.
8.1.2. Docker Remote API
An other option is to let a custom Turbine plugin use the Docker Remote API to get hold of containers and their IP-addresses, which then can be transformed into something Turbine can use. This should work too, but has some drawbacks such as tying the plugin to a specific container orchestrator as well as having run Turbine on a Docker swarm mode manager node.
8.2 The Turbine plugin
The and some basic docs for the Turbine plugin I’ve written can be found on my personal github page. Since it’s Java-based I’m not going to spend precious blog space describing it in detail in this context.
You can also use a pre-built container image I’ve put on hub.docker.com. Just launch as a Docker swarm service.
An executable jar file and a Dockerfile for the Hystrix dashboard exists in /goblog/support/monitor-dashboard. The customized Turbine is easiest used from my container image linked above.
I’ve updated my shell scripts to launch the custom Turbine and Hystrix Dashboards. In springcloud.sh:
Also, the accountservice Dockerfile now exposes port 8181 so Hystrix streams can be read from within the cluster. You shouldn’t map 8181 to a public port in your docker service create command.
8.3.2 Troubleshooting
I don’t know if Turbine is slightly buggy or what the matter is, but I tend to having to do the following for Hystrix Dashboard to pick up a stream from Turbine:
- Sometimes restart my turbine service, easiest done using docker service scale=0
- Have some requests going through the circuit breakers. Unsure if hystrix streams are produced by go-hystrix if there’s been no or no ongoing traffic passing through.
- Making sure the URL one enters into Hystrix Dashboard is correct. works for me.
9. Summary
In the next part of the , we’ll be introducing two new concepts: The Zuul EDGE server and distributed tracing using Zipkin and Opentracing.

