
十五、聚类
聚类是尝试在数据中查找结构(簇)的过程。
这是来自维基百科的文章。
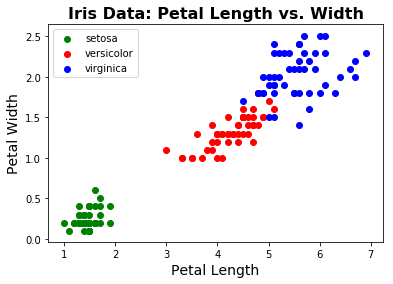
如果我们还不知道物种标签,我们可能会注意到似乎有不同的数据点分组。聚类是尝试在算法上找到这些组的方法。
在这里,我们将使用 KMeans 算法。有关 KMeans 及其工作原理的信息,请参阅维基百科。
数据白化
这是因为 KMeans 是各向同性的:它对待每个方向上的差异同等重要。 因此,如果单位或方差非常不同,这相当于将某些特征/维度加权,使其更重要或更不重要。
为了纠正这种情况,通常,有时需要“白化”数据:通过它各自的标准偏差来标准化每个维度。
看起来它做得很好!除了杂色和维吉尼亚边界之间的一些差异之外,仅给出关于几个特征的信息的情况下,KMeans 能够使用算法重建物种标签。

