
十八、自然语言处理
自然语言处理(NLP)是使用计算机分析文本数据的方法。
这是维基百科上的自然语言处理。
NLTK 是用于文本分析的主要 Python 模块。
NLTK 组织网站在,他们有一整本教程在这里。
NLTK
NLTK 为超过 50 种语料库和词汇资源(如 WordNet)提供了易于使用的界面,以及一套用于分类,分词,词干提取,标注,解析和语义推理的文本处理库,用于工业级 NLP 库的包装器,和活跃的讨论论坛。
在这个笔记本中,我们将使用 NLTK 包中的一些有用功能来完成一些基本的文本分析。
要处理文本数据,通常需要使用语料库 - 文本数据集进行比较。 NLTK 有许多这样的数据集可用,但默认情况下不会安装它们(因为它们的完整集合会非常大)。下面我们将下载其中一些数据集。
# 请返回此单元格,取消注释,然后运行此代码。# 这段代码赋予 python 写入磁盘的权限(如果它还没有这样做的权限)。import ssltry:_create_unverified_https_context = ssl._create_unverified_contextexcept AttributeError:passelse:ssl._create_default_https_context = _create_unverified_https_context# 从 NLTK 下载一些有用的数据文件nltk.download('punkt')nltk.download('stopwords')nltk.download('averaged_perceptron_tagger')nltk.download('maxent_ne_chunker')nltk.download('words')nltk.download('treebank')'''[nltk_data] Downloading package punkt to /Users/tom/nltk_data...[nltk_data] Package punkt is already up-to-date![nltk_data] Downloading package stopwords to /Users/tom/nltk_data...[nltk_data] Package stopwords is already up-to-date![nltk_data] Downloading package averaged_perceptron_tagger to[nltk_data] /Users/tom/nltk_data...[nltk_data] Package averaged_perceptron_tagger is already up-to-[nltk_data] date![nltk_data] Downloading package maxent_ne_chunker to[nltk_data] /Users/tom/nltk_data...[nltk_data] Package maxent_ne_chunker is already up-to-date![nltk_data] Downloading package words to /Users/tom/nltk_data...[nltk_data] Package words is already up-to-date![nltk_data] Downloading package treebank to /Users/tom/nltk_data...[nltk_data] Package treebank is already up-to-date!True'''# 设置一些要测试的数据的测试句子sentence = "UC San Diego is a great place to study cognitive science."
分词是将文本数据拆分为“标记”的过程,这些标记是有意义的数据片段。
分词的更多信息在。
词可以在不同的级别完成 - 例如,你可以将文本分词为句子,和/或分词为单词。
# 在单词级别对我们的句子进行分词tokens = nltk.word_tokenize(sentence)# 查看单词分词后的数据print(tokens)# ['UC', 'San', 'Diego', 'is', 'a', 'great', 'place', 'to', 'study', 'cognitive', 'science', '.']
这里是维基百科上的词性标注。
# 对我们的句子进行词性标注tags = nltk.pos_tag(tokens)# 检查我们的数据的 POS 标签print(tags)# [('UC', 'NNP'), ('San', 'NNP'), ('Diego', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('great', 'JJ'), ('place', 'NN'), ('to', 'TO'), ('study', 'VB'), ('cognitive', 'JJ'), ('science', 'NN'), ('.', '.')]# 查看描述所有缩写含义的文档nltk.help.upenn_tagset()'''$: dollar$ -$ --$ A$ C$ HK$ M$ NZ$ S$ U.S.$ US$'': closing quotation mark' ''(: opening parenthesis( [ {): closing parenthesis) ] },: comma,--: dash--.: sentence terminator. ! ?:: colon or ellipsis: ; ...CC: conjunction, coordinating& 'n and both but either et for less minus neither nor or plus sotherefore times v. versus vs. whether yetCD: numeral, cardinalmid-1890 nine-thirty forty-two one-tenth ten million 0.5 one forty-seven 1987 twenty '79 zero two 78-degrees eighty-four IX '60s .025fifteen 271,124 dozen quintillion DM2,000 ...DT: determinerall an another any both del each either every half la many much naryneither no some such that the them these this thoseEX: existential therethereFW: foreign wordlutihaw alai je jour objets salutaris fille quibusdam pas trop Monteterram fiche oui corporis ...IN: preposition or conjunction, subordinatingastride among uppon whether out inside pro despite on by throughoutbelow within for towards near behind atop around if like until belowJJ: adjective or numeral, ordinalthird ill-mannered pre-war regrettable oiled calamitous first separableectoplasmic battery-powered participatory fourth still-to-be-namedmultilingual multi-disciplinary ...JJR: adjective, comparativebleaker braver breezier briefer brighter brisker broader bumper busiercalmer cheaper choosier cleaner clearer closer colder commoner costliercozier creamier crunchier cuter ...JJS: adjective, superlativecalmest cheapest choicest classiest cleanest clearest closest commonestcorniest costliest crassest creepiest crudest cutest darkest deadliestdearest deepest densest dinkiest ...LS: list item markerA A. B B. C C. D E F First G H I J K One SP-44001 SP-44002 SP-44005SP-44007 Second Third Three Two * a b c d first five four one six threetwoMD: modal auxiliarycan cannot could couldn't dare may might must need ought shall shouldshouldn't will wouldNN: noun, common, singular or masscommon-carrier cabbage knuckle-duster Casino afghan shed thermostatinvestment slide humour falloff slick wind hyena override subhumanitymachinist ...NNP: noun, proper, singularMotown Venneboerger Czestochwa Ranzer Conchita Trumplane ChristosOceanside Escobar Kreisler Sawyer Cougar Yvette Ervin ODI Darryl CTCAShannon A.K.C. Meltex Liverpool ...NNPS: noun, proper, pluralAmericans Americas Amharas Amityvilles Amusements Anarcho-SyndicalistsAndalusians Andes Andruses Angels Animals Anthony Antilles AntiquesApache Apaches Apocrypha ...NNS: noun, common, pluralundergraduates scotches bric-a-brac products bodyguards facets coastsdivestitures storehouses designs clubs fragrances averagessubjectivists apprehensions muses factory-jobs ...PDT: pre-determinerall both half many quite such sure thisPOS: genitive marker' 'sPRP: pronoun, personalhers herself him himself hisself it itself me myself one oneself oursourselves ownself self she thee theirs them themselves they thou thy usPRP$: pronoun, possessiveher his mine my our ours their thy yourRB: adverboccasionally unabatingly maddeningly adventurously professedlystirringly prominently technologically magisterially predominatelyswiftly fiscally pitilessly ...RBR: adverb, comparativefurther gloomier grander graver greater grimmer harder harsherhealthier heavier higher however larger later leaner lengthier less-perfectly lesser lonelier longer louder lower more ...RBS: adverb, superlativebest biggest bluntest earliest farthest first furthest hardestheartiest highest largest least less most nearest second tightest worstRP: particleaboard about across along apart around aside at away back before behindby crop down ever fast for forth from go high i.e. in into just laterlow more off on open out over per pie raising start teeth that throughunder unto up up-pp upon whole with youSYM: symbol% & ' '' ''. ) ). * + ,. < = > @ A[fj] U.S U.S.S.R * ** ***TO: "to" as preposition or infinitive markertoUH: interjectionGoodbye Goody Gosh Wow Jeepers Jee-sus Hubba Hey Kee-reist Oops amenhuh howdy uh dammit whammo shucks heck anyways whodunnit honey gollyman baby diddle hush sonuvabitch ...VB: verb, base formask assemble assess assign assume atone attention avoid bake balkanizebank begin behold believe bend benefit bevel beware bless boil bombboost brace break bring broil brush build ...VBD: verb, past tensedipped pleaded swiped regummed soaked tidied convened halted registeredcushioned exacted snubbed strode aimed adopted belied figgeredspeculated wore appreciated contemplated ...VBG: verb, present participle or gerundtelegraphing stirring focusing angering judging stalling lactatinghankerin' alleging veering capping approaching traveling besiegingencrypting interrupting erasing wincing ...VBN: verb, past participlemultihulled dilapidated aerosolized chaired languished panelized usedexperimented flourished imitated reunifed factored condensed shearedunsettled primed dubbed desired ...VBP: verb, present tense, not 3rd person singularpredominate wrap resort sue twist spill cure lengthen brush terminateappear tend stray glisten obtain comprise detest tease attractemphasize mold postpone sever return wag ...VBZ: verb, present tense, 3rd person singularbases reconstructs marks mixes displeases seals carps weaves snatchesslumps stretches authorizes smolders pictures emerges stockpilesseduces fizzes uses bolsters slaps speaks pleads ...WDT: WH-determinerthat what whatever which whicheverWP: WH-pronounthat what whatever whatsoever which who whom whosoeverwhoseWRB: Wh-adverbhow however whence whenever where whereby whereever wherein whereof why'''
命名实体识别旨在用与相关的实体类型标记单词。
这里是上的命名实体识别。
“停止词”是一种语言中最常见的词语,我们经常希望在文本分析之前将其过滤掉。
这里是维基百科上的停止词。
# 查看英语中的停止词语料库print(nltk.corpus.stopwords.words('english'))# ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
文本编码
NLP的关键组件之一是决定如何编码文本数据。
常见的编码是:
- 词袋(BoW)
- 文本被编码为单词和频率的集合
- 词频-逆向文件频率(TF-IDF)
- TF-IDF是一种加权,用于存储单词和语料库中的共性关系。
我们将浏览 BoW 和 TF-IDF 文本编码的示例。
# 导入%matplotlib inline# 标准 Python 有一些有用的字符串工具import string# 集合是标准 Python 的一部分,包含一些有用的数据对象from collections import Counterimport numpy as npimport matplotlib.pyplot as plt# Scikit-learn 有一些有用的 NLP 工具,例如 TFIDF 向量化器from sklearn.feature_extraction.text import TfidfVectorizer
我们将要查看的数据是 BookCorpus 数据集的一小部分。原始数据集可在此处找到:。
原始数据集是从超过 11,000 本书中收集的,并且已经在句子和单词级别上进行了分词。这里提供和使用的小子集包含前 10,000 个句子。
# 加载数据with open('files/book10k.txt', 'r') as f:sents = f.readlines()# 查看数据 - 打印出第一个和最后一个句子,作为示例print(sents[0])print(sents[-1])'''the half-ling book one in the fall of igneeria series kaylee soderburg copyright 2013 kaylee soderburg all rights reserved .alejo was sure the fact that he was nervously repeating mass along with five wrinkly , age-encrusted spanish women meant that stalin was rethinking whether he was going to pay the price .'''# 预处理:从句子中删除所有额外的空格sents = [sent.strip() for sent in sents]
我们首先看一下文档中的单词频率,然后打印出频率最高的前 10 个单词。
如果你滚动上面的单词列表,你可能会注意到的一点是,它仍然包含标点符号。我们删除那些。
# 'string' 模块(标准库)有一个有用的标点符号列表print(string.punctuation)# !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~# 从计数对象中删除所有标点符号标记for punc in string.punctuation:if punc in counts:counts.pop(punc)# 获得前 10 个最常用的单词top10 = counts.most_common(10)# 提取顶部单词,并计数top10_words = [it[0] for it in top10]top10_counts = [it[1] for it in top10]# 绘制文本中最常用单词的条形图plt.barh(top10_words, top10_counts)plt.title('Term Frequency');plt.xlabel('Frequency');
正如我们所看到的,文档中出现了the,was,a等等。
对于弄清楚这些文档的内容,或者作为使用和理解这些文本数据的方式,这些经常出现的单词并不是很有用。
# 丢弃所有停止词for stop in nltk.corpus.stopwords.words('english'):if stop in counts:counts.pop(stop)# 获取删除停止词的数据中,前 20 个最常用单词top20 = counts.most_common(20)# 绘制文本中最常用单词的条形图plt.barh([it[0] for it in top20], [it[1] for it in top20])plt.title('Term Frequency');plt.xlabel('Frequency');
这看起来可能更相关/有用。我们可以继续探索这个 BoW 模型,但现在让我们转向,并使用 TFIDF 进行探索。
# 初始化 TFIDF 对象tfidf = TfidfVectorizer(analyzer='word',sublinear_tf=True,max_features=5000,tokenizer=nltk.word_tokenize)# 将 TFIDF 转换应用于我们的数据# 请注意,这会接受句子并对其进行分词,然后应用 TFIDFtfidf_books = tfidf.fit_transform(sents).toarray()
TfidfVectorizer 将计算每个单词的逆文档频率(IDF)。
然后 TFIDF 计算为TF * IDF,用于降低频繁出现的单词的权重。该 TFIDF 存储在tfidf_books变量中,该变量是一个n_documents x n_words矩阵,用于以 TFIDF 表示来编码文档。
让我们首先为前 10 个最常出现的单词(来自第一次分析)中的每一个绘制 IDF。
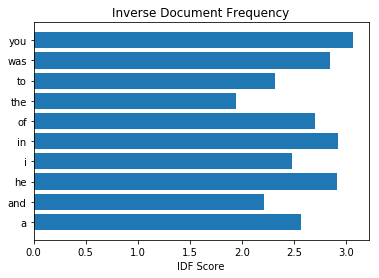
我们将该绘图与以下绘图进行比较,该绘图显示 IDF 最高的前 10 个单词。
# 获得 IDF 得分最高的单词inds = np.argsort(tfidf.idf_)[::-1][:10]top_IDF_tokens = [list(tfidf.vocabulary_)[ind] for ind in inds]top_IDF_scores = tfidf.idf_[inds]# 绘制 IDF 得分最高的单词plt.barh(top_IDF_tokens, top_IDF_scores)plt.xlabel('IDF Score');
正如我们所看到的,与更罕见的单词相比,文档中经常出现的单词获得的 IDF 分数非常低。
在 TF-IDF 之后,我们成功地减少了文档中频繁出现的单词的权重。这允许我们通过最独特的单词来表示文档,这可以是表示文本数据的更有用的方式。

