
从另一个角度来看,这种模式下索引的数据结构也做了分区处理,因此有时也被称为本地分区索引(Local Partitioned Index)。本地索引的结构如下图所示:
在上图中,employee 表按照 emp_id 做了范围分区,同时也在 emp_name 上创建了本地索引。
全局索引
和分区表的本地索引相比,分区表的全局索引不再和主表的分区保持一对一的关系,而是将所有主表分区的数据合成一个整体来看,索引中的一个键可能会映射到多个主表分区中的数据(当索引键有重复值时)。更进一步,全局索引可以定义自己独立的数据分布模式,既可以选择非分区模式也可以选择分区模式;在分区模式中,分区的方式既可以和主表相同也可以和主表不同。因此,全局索引又分为以下两种形式:
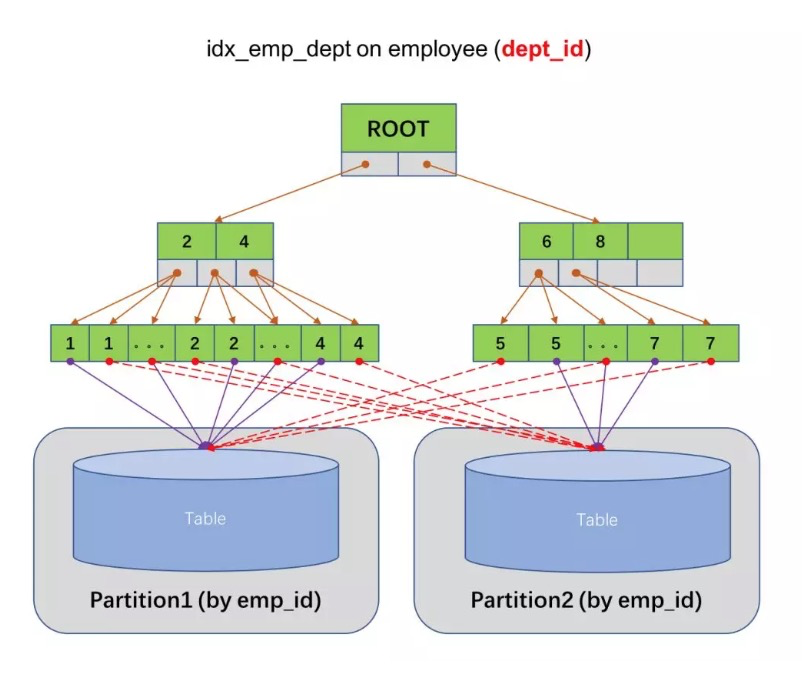
在上图中,虽然 employee 表按照 emp_id 做了分区,但是创建在 dept_id 上的全局索引并没有分区,因此同一个键值可能会映射到多个分区中。
- 全局分区索引(**Global Partitioned Index**)
索引数据按照指定的方式做分区处理,比如做哈希(Hash)分区或者范围(Range)分区,将索引数据分散到不同的分区中。但索引的分区模式是完全独立的,和主表的分区没有任何关系,因此对于每个索引分区来说,里面的某一个键都可能映射到不同的主表分区(当索引键有重复值时),索引分区和主表分区之间是“多对多”的对应关系。全局分区索引的结构如下图所示:
由于全局索引的分区模式和主表的分区模式完全没有关系,看上去全局索引更像是另一张独立的表,因此也会将全局索引叫做索引表,理解起来会更容易一些(和主表相对应)。
在了解了本地索引和全局索引的基本概念之后,我们直接给出什么场景需要全局索引的结论。全局索引主要使用在两个场景:
- 业务的查询无法得到分区键的条件谓词,且业务表没有高并发的同时写入,为避免进行全分区的扫描,可以根据查询条件构建全局索引,使用新的分区。
需要意识到的是,全局索引虽然为全局唯一、数据重新分区带来了可能,解决了一些业务需要根据不同维度进行查询的强需求,但是为此付出的代价是每一笔数据的写入都有可能变成跨机的分布式事务,在高并发的写入场景下它将极大的影响系统的写入性能。当业务的查询可以拥有分区键的条件谓词时,我们依旧推荐构建本地索引,通过数据库优化器的分区裁剪功能,排除掉不符合条件的分区。这样的做法为了同时兼顾查询和写入的性能,让系统的总体性能达到一个均衡的状态。

