A.1 ndarray对象的内部机理
ndarray如此强大的部分原因是所有数组对象都是数据块的一个跨度视图(strided view)。你可能想知道数组视图arr[::2,::-1]不复制任何数据的原因是什么。简单地说,ndarray不只是一块内存和一个dtype,它还有跨度信息,这使得数组能以各种步幅(step size)在内存中移动。更准确地讲,ndarray内部由以下内容组成:
- 数据类型或dtype,描述在数组中的固定大小值的格子。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要“跨过”的字节数。
图A-1简单地说明了ndarray的内部结构。
一个典型的(C顺序,稍后将详细讲解)3×4×5的float64(8个字节)数组,其跨度为(160,40,8) —— 知道跨度是非常有用的,通常,跨度在一个轴上越大,沿这个轴进行计算的开销就越大:
虽然NumPy用户很少会对数组的跨度信息感兴趣,但它们却是构建非复制式数组视图的重要因素。跨度甚至可以是负数,这样会使数组在内存中后向移动,比如在切片obj[::-1]或obj[:,::-1]中就是这样的。
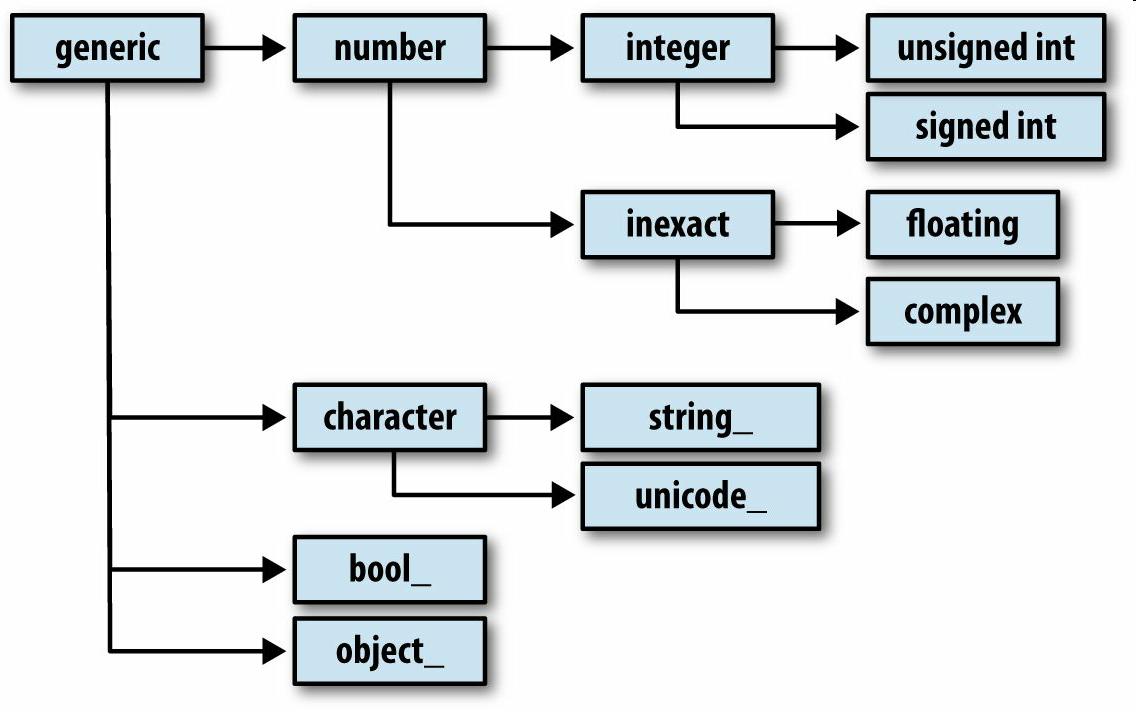
你可能偶尔需要检查数组中所包含的是否是整数、浮点数、字符串或Python对象。因为浮点数的种类很多(从float16到float128),判断dtype是否属于某个大类的工作非常繁琐。幸运的是,dtype都有一个超类(比如np.integer和np.floating),它们可以跟np.issubdtype函数结合使用:
然后得到:
大部分NumPy用户完全不需要了解这些知识,但是这些知识偶尔还是能派上用场的。图A-2说明了dtype体系以及父子类关系。