使用 获得数据集并预处理
使用
tf.keras.Model和tf.keras.layers构建模型构建模型训练流程,使用
tf.keras.losses计算损失函数,并使用tf.keras.optimizer优化模型构建模型评估流程,使用
tf.keras.metrics计算评估指标
基础知识和原理
UFLDL 教程 一节;
斯坦福课程 CS231n: Convolutional Neural Networks for Visual Recognition 中的 “Neural Networks Part 1 ~ 3” 部分。
这里,我们使用多层感知机完成 MNIST 手写体数字图片数据集 的分类任务。
先进行预备工作,实现一个简单的 MNISTLoader 类来读取 MNIST 数据集数据。这里使用了 tf.keras.datasets 快速载入 MNIST 数据集。
提示
mnist = tf.keras.datasets.mnist 将从网络上自动下载 MNIST 数据集并加载。如果运行时出现网络连接错误,可以从 或 https://s3.amazonaws.com/img-datasets/mnist.npz 下载 MNIST 数据集 mnist.npz 文件,并放置于用户目录的 .keras/dataset 目录下(Windows 下用户目录为 C:\Users\用户名 ,Linux 下用户目录为 /home/用户名 )。
TensorFlow 的图像数据表示
在 TensorFlow 中,图像数据集的一种典型表示是 [图像数目,长,宽,色彩通道数] 的四维张量。在上面的 DataLoader 类中, 和 self.test_data 分别载入了 60,000 和 10,000 张大小为 28*28 的手写体数字图片。由于这里读入的是灰度图片,色彩通道数为 1(彩色 RGB 图像色彩通道数为 3),所以我们使用 np.expand_dims() 函数为图像数据手动在最后添加一维通道。
多层感知机的模型类实现与上面的线性模型类似,使用 tf.keras.Model 和 tf.keras.layers 构建,所不同的地方在于层数增加了(顾名思义,“多层” 感知机),以及引入了非线性激活函数(这里使用了 , 即下方的 activation=tf.nn.relu )。该模型输入一个向量(比如这里是拉直的 1×784 手写体数字图片),输出 10 维的向量,分别代表这张图片属于 0 到 9 的概率。
- class MLP(tf.keras.Model):
- def __init__(self):
- super().__init__()
- self.flatten = tf.keras.layers.Flatten() # Flatten层将除第一维(batch_size)以外的维度展平
- self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
- self.dense2 = tf.keras.layers.Dense(units=10)
- x = self.flatten(inputs) # [batch_size, 784]
- x = self.dense1(x) # [batch_size, 100]
- x = self.dense2(x) # [batch_size, 10]
- output = tf.nn.softmax(x)
- return output
这里,因为我们希望输出 “输入图片分别属于 0 到 9 的概率”,也就是一个 10 维的离散概率分布,所以我们希望这个 10 维向量至少满足两个条件:
该向量中的每个元素均在
![[0, 1]](/static/images/loading.gif) 之间;
之间;该向量的所有元素之和为 1。
为了使得模型的输出能始终满足这两个条件,我们使用 Softmax 函数 (归一化指数函数, tf.nn.softmax )对模型的原始输出进行归一化。其形式为 。不仅如此,softmax 函数能够凸显原始向量中最大的值,并抑制远低于最大值的其他分量,这也是该函数被称作 softmax 函数的原因(即平滑化的 argmax 函数)。
定义一些模型超参数:
- num_epochs = 5
- batch_size = 50
- learning_rate = 0.001
实例化模型和数据读取类,并实例化一个 tf.keras.optimizer 的优化器(这里使用常用的 Adam 优化器):
然后迭代进行以下步骤:
从 DataLoader 中随机取一批训练数据;
将这批数据送入模型,计算出模型的预测值;
将模型预测值与真实值进行比较,计算损失函数(loss)。这里使用
tf.keras.losses中的交叉熵函数作为损失函数;计算损失函数关于模型变量的导数;
将求出的导数值传入优化器,使用优化器的
apply_gradients方法更新模型参数以最小化损失函数(优化器的详细使用方法见 )。
具体代码实现如下:
- num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
- for batch_index in range(num_batches):
- with tf.GradientTape() as tape:
- y_pred = model(X)
- loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
- loss = tf.reduce_mean(loss)
- print("batch %d: loss %f" % (batch_index, loss.numpy()))
- grads = tape.gradient(loss, model.variables)
- optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
交叉熵(cross entropy)与 tf.keras.losses
交叉熵作为损失函数,在分类问题中被广泛应用。其离散形式为 ,其中 为真实概率分布, 为预测概率分布, 为分类任务的类别个数。预测概率分布与真实分布越接近,则交叉熵的值越小,反之则越大。更具体的介绍及其在机器学习中的应用可参考 这篇博客文章 。
在 tf.keras 中,有两个交叉熵相关的损失函数 tf.keras.losses.categorical_crossentropy 和 tf.keras.losses.sparse_categorical_crossentropy 。其中 sparse 的含义是,真实的标签值 y_true 可以直接传入 int 类型的标签类别。具体而言:
- loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
与
的结果相同。
最后,我们使用测试集评估模型的性能。这里,我们使用 tf.keras.metrics 中的 SparseCategoricalAccuracy 评估器来评估模型在测试集上的性能,该评估器能够对模型预测的结果与真实结果进行比较,并输出预测正确的样本数占总样本数的比例。我们迭代测试数据集,每次通过 update_state() 方法向评估器输入两个参数: y_pred 和 y_true ,即模型预测出的结果和真实结果。评估器具有内部变量来保存当前评估指标相关的参数数值(例如当前已传入的累计样本数和当前预测正确的样本数)。迭代结束后,我们使用 result() 方法输出最终的评估指标值(预测正确的样本数占总样本数的比例)。
在以下代码中,我们实例化了一个 tf.keras.metrics.SparseCategoricalAccuracy 评估器,并使用 For 循环迭代分批次传入了测试集数据的预测结果与真实结果,并输出训练后的模型在测试数据集上的准确率。
- sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
- num_batches = int(data_loader.num_test_data // batch_size)
- for batch_index in range(num_batches):
- start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
- y_pred = model.predict(data_loader.test_data[start_index: end_index])
- sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
- print("test accuracy: %f" % sparse_categorical_accuracy.result())
输出结果:
- test accuracy: 0.947900
可以注意到,使用这样简单的模型,已经可以达到 95% 左右的准确率。
神经网络的基本单位:神经元
如果我们将上面的神经网络放大来看,详细研究计算过程,比如取第二层的第 k 个计算单元,可以得到示意图如下:
该计算单元 有 100 个权值参数 和 1 个偏置参数 。将第 1 层中所有的 100 个计算单元 的值作为输入,分别按权值 加和(即 ),并加上偏置值 ,然后送入激活函数 进行计算,即得到输出结果。
事实上,这种结构和真实的神经细胞(神经元)类似。神经元由树突、胞体和轴突构成。树突接受其他神经元传来的信号作为输入(一个神经元可以有数千甚至上万树突),胞体对电位信号进行整合,而产生的信号则通过轴突传到神经末梢的突触,传播到下一个(或多个)神经元。
神经细胞模式图(修改自 Quasar Jarosz at English Wikipedia [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)])
上面的计算单元,可以被视作对神经元结构的数学建模。在上面的例子里,第二层的每一个计算单元(人工神经元)有 100 个权值参数和 1 个偏置参数,而第二层计算单元的数目是 10 个,因此这一个全连接层的总参数量为 100*10 个权值参数和 10 个偏置参数。事实上,这正是该全连接层中的两个变量 kernel 和 bias 的形状。仔细研究一下,你会发现,这里基于神经元建模的介绍与上文基于矩阵计算的介绍是等价的。

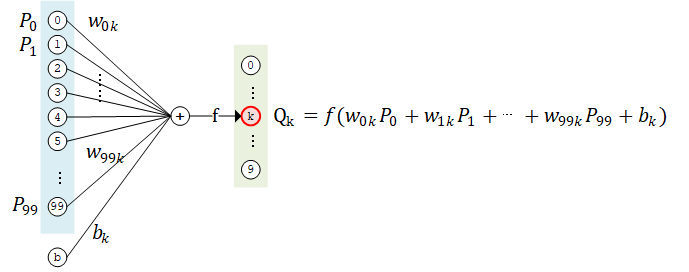{kind=link}