
分组匹配
实际上(…)还有一个重要作用,就是分组匹配。
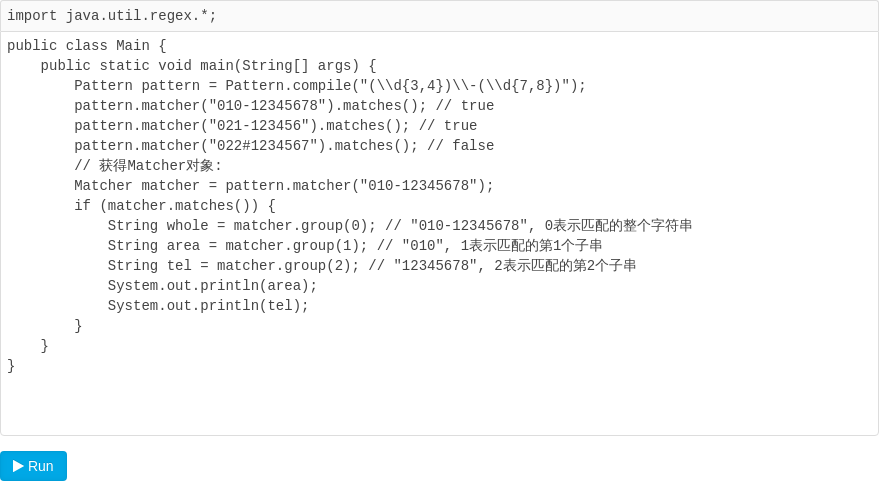
我们来看一下如何用正则匹配区号-电话号码这个规则。利用前面讲到的匹配规则,写出来很容易:
虽然这个正则匹配规则很简单,但是往往匹配成功后,下一步是提取区号和电话号码,分别存入数据库。于是问题来了:如何提取匹配的子串?
当然可以用String提供的indexOf()和substring()这些方法,但它们从正则匹配的字符串中提取子串没有通用性,下一次要提取learn\s(java|php)还得改代码。
正确的方法是用(…)先把要提取的规则分组,把上述正则表达式变为(\d{3,4})-(\d{6,8})。
现在我们没办法用String.matches()这样简单的判断方法了,必须引入java.util.regex包,用对象匹配,匹配后获得一个Matcher对象,如果匹配成功,就可以直接从Matcher.group(index)返回子串:
运行上述代码,会得到两个匹配上的子串010和12345678。
要特别注意,Matcher.group(index)方法的参数用1表示第一个子串,2表示第二个子串。如果我们传入0会得到什么呢?答案是010-12345678,即整个正则匹配到的字符串。
我们在前面的代码中用到的正则表达式代码是String.matches()方法,而我们在分组提取的代码中用的是java.util.regex包里面的Pattern类和Matcher类。实际上这两种代码本质上是一样的,因为String.matches()方法内部调用的就是和Matcher类的方法。
使用Matcher时,必须首先调用matches()判断是否匹配成功,匹配成功后,才能调用group()提取子串。
利用提取子串的功能,我们轻松获得了区号和号码两部分。
利用分组匹配,从字符串"23:01:59"提取时、分、秒。
下载练习: (推荐使用IDE练习插件快速下载)
group(0)表示匹配的整个字符串;


