
输出集合
区分这两种操作是非常重要的,因为对于Stream来说,对其进行转换操作并不会触发任何计算!我们可以做个实验:
因为s1是一个Long类型的序列,它的元素高达922亿个,但执行上述代码,既不会有任何内存增长,也不会有任何计算,因为转换操作只是保存了转换规则,无论我们对一个Stream转换多少次,都不会有任何实际计算发生。
而聚合操作则不一样,聚合操作会立刻促使Stream输出它的每一个元素,并依次纳入计算,以获得最终结果。所以,对一个Stream进行聚合操作,会触发一系列连锁反应:
我们对s4进行reduce()聚合计算,会不断请求s4输出它的每一个元素。因为s4的上游是s3,它又会向s3请求元素,导致s3向s2请求元素,向s1请求元素,最终,s1从Supplier实例中请求到真正的元素,并经过一系列转换,最终被reduce()聚合出结果。
可见,聚合操作是真正需要从Stream请求数据的,对一个Stream做聚合计算后,结果就不是一个Stream,而是一个其他的Java对象。
reduce()只是一种聚合操作,如果我们希望把Stream的元素保存到集合,例如List,因为List的元素是确定的Java对象,因此,把Stream变为List不是一个转换操作,而是一个聚合操作,它会强制Stream输出每个元素。
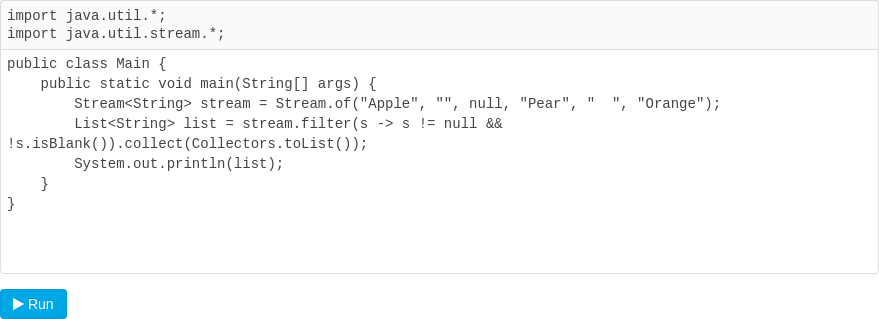
把Stream的每个元素收集到List的方法是调用collect()并传入Collectors.toList()对象,它实际上是一个Collector实例,通过类似reduce()的操作,把每个元素添加到一个收集器中(实际上是ArrayList)。
类似的,collect(Collectors.toSet())可以把的每个元素收集到Set中。
输出为数组
把Stream的元素输出为数组和输出为List类似,我们只需要调用toArray()方法,并传入数组的“构造方法”:
注意到传入的“构造方法”是String[]::new,它的签名实际上是IntFunction<String[]>定义的String[] apply(int),即传入int参数,获得String[]数组的返回值。
如果我们要把Stream的元素收集到Map中,就稍微麻烦一点。因为对于每个元素,添加到Map时需要key和value,因此,我们要指定两个映射函数,分别把元素映射为key和value:
分组输出
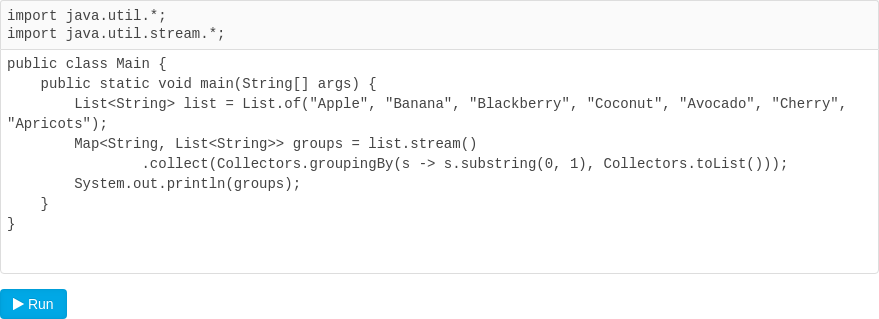
分组输出使用Collectors.groupingBy(),它需要提供两个函数:一个是分组的key,这里使用s -> s.substring(0, 1),表示只要首字母相同的String分到一组,第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List,上述代码运行结果如下:
可见,结果一共有3组,按"A","B","C"分组,每一组都是一个List。
假设有这样一个Student类,包含学生姓名、班级和成绩:
如果我们有一个Stream<Student>,利用分组输出,可以非常简单地按年级或班级把Student归类。
Stream可以输出为集合:
Stream通过collect()方法可以方便地输出为List、、Map,还可以分组输出。

