
线程同步
这个时候,有个单线程模型下不存在的问题就来了:如果多个线程同时读写共享变量,会出现数据不一致的问题。
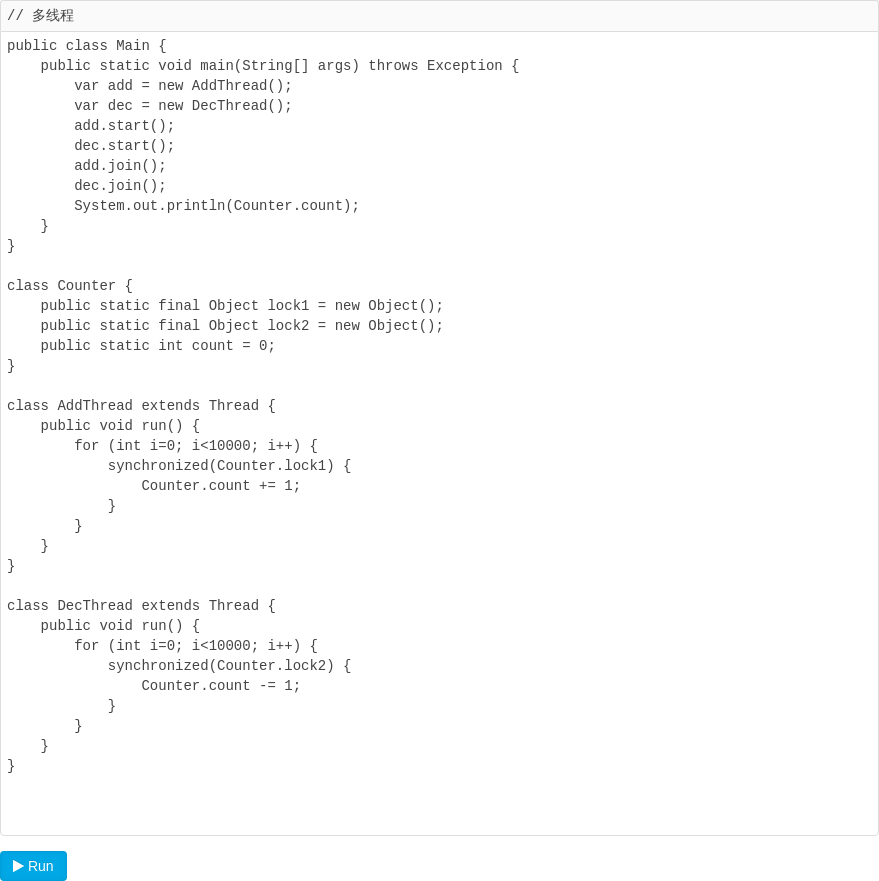
我们来看一个例子:
上面的代码很简单,两个线程同时对一个变量进行操作,一个加10000次,一个减10000次,最后结果应该是0,但是,每次运行,结果实际上都是不一样的。
这是因为对变量进行读取和写入时,结果要正确,必须保证是原子操作。原子操作是指不能被中断的一个或一系列操作。
例如,对于语句:
看上去是一行语句,实际上对应了3条指令:
ILOADIADDISTORE
我们假设n的值是100,如果两个线程同时执行n = n + 1,得到的结果很可能不是102,而是101,原因在于:
┌───────┐ ┌───────┐│Thread1│ │Thread2│└───┬───┘ └───┬───┘│ ││ILOAD (100) ││ │ILOAD (100)│ │IADD│ │ISTORE (101)│IADD ││ISTORE (101)│▼ ▼
如果线程1在执行ILOAD后被操作系统中断,此刻如果线程2被调度执行,它执行ILOAD后获取的值仍然是100,最终结果被两个线程的ISTORE写入后变成了101,而不是期待的102。
这说明多线程模型下,要保证逻辑正确,对共享变量进行读写时,必须保证一组指令以原子方式执行:即某一个线程执行时,其他线程必须等待:
┌───────┐ ┌───────┐│Thread1│ │Thread2│└───┬───┘ └───┬───┘│ ││-- lock -- ││IADD ││ISTORE (101) ││-- unlock -- ││ │-- lock --│ │ILOAD (101)│ │IADD│ │-- unlock --▼ ▼
通过加锁和解锁的操作,就能保证3条指令总是在一个线程执行期间,不会有其他线程会进入此指令区间。即使在执行期线程被操作系统中断执行,其他线程也会因为无法获得锁导致无法进入此指令区间。只有执行线程将锁释放后,其他线程才有机会获得锁并执行。这种加锁和解锁之间的代码块我们称之为临界区(Critical Section),任何时候临界区最多只有一个线程能执行。
可见,保证一段代码的原子性就是通过加锁和解锁实现的。Java程序使用synchronized关键字对一个对象进行加锁:
synchronized保证了代码块在任意时刻最多只有一个线程能执行。我们把上面的代码用synchronized改写如下:
注意到代码:
synchronized(Counter.lock) { // 获取锁...} // 释放锁
它表示用Counter.lock实例作为锁,两个线程在执行各自的synchronized(Counter.lock) { … }代码块时,必须先获得锁,才能进入代码块进行。执行结束后,在synchronized语句块结束会自动释放锁。这样一来,对Counter.count变量进行读写就不可能同时进行。上述代码无论运行多少次,最终结果都是0。
使用synchronized解决了多线程同步访问共享变量的正确性问题。但是,它的缺点是带来了性能下降。因为synchronized代码块无法并发执行。此外,加锁和解锁需要消耗一定的时间,所以,synchronized会降低程序的执行效率。
我们来概括一下如何使用synchronized:
- 找出修改共享变量的线程代码块;
- 选择一个共享实例作为锁;
- 使用
synchronized(lockObject) { … }。在使用synchronized的时候,不必担心抛出异常。因为无论是否有异常,都会在synchronized结束处正确释放锁:
public void add(int m) {synchronized (obj) {if (m < 0) {throw new RuntimeException();}this.value += m;} // 无论有无异常,都会在此释放锁
我们再来看一个错误使用synchronized的例子:
结果并不是0,这是因为两个线程各自的synchronized锁住的不是同一个对象!这使得两个线程各自都可以同时获得锁:因为JVM只保证同一个锁在任意时刻只能被一个线程获取,但两个不同的锁在同一时刻可以被两个线程分别获取。
因此,使用synchronized的时候,获取到的是哪个锁非常重要。锁对象如果不对,代码逻辑就不对。
我们再看一个例子:
上述代码的4个线程对两个共享变量分别进行读写操作,但是使用的锁都是Counter.lock这一个对象,这就造成了原本可以并发执行的Counter.studentCount += 1和Counter.teacherCount += 1,现在无法并发执行了,执行效率大大降低。实际上,需要同步的线程可以分成两组:AddStudentThread和DecStudentThread,AddTeacherThread和DecTeacherThread,组之间不存在竞争,因此,应该使用两个不同的锁,即:
和DecStudentThread使用lockStudent锁:
synchronized(Counter.lockStudent) {...}
AddTeacherThread和DecTeacherThread使用lockTeacher锁:
JVM规范定义了几种原子操作:
- 基本类型(
long和double除外)赋值,例如:int n = m; - 引用类型赋值,例如:
List<String> list = anotherList。
long和double是64位数据,JVM没有明确规定64位赋值操作是不是一个原子操作,不过在x64平台的JVM是把long和double的赋值作为原子操作实现的。
单条原子操作的语句不需要同步。例如:
public void set(int m) {synchronized(lock) {this.value = m;}}
就不需要同步。
对引用也是类似。例如:
public void set(String s) {this.value = s;}
上述赋值语句并不需要同步。
但是,如果是多行赋值语句,就必须保证是同步操作,例如:
class Pair {int first;int last;public void set(int first, int last) {synchronized(this) {this.first = first;this.last = last;}}
有些时候,通过一些巧妙的转换,可以把非原子操作变为原子操作。例如,上述代码如果改造成:
就不再需要同步,因为this.pair = ps是引用赋值的原子操作。而语句:
int[] ps = new int[] { first, last };
这里的ps是方法内部定义的局部变量,每个线程都会有各自的局部变量,互不影响,并且互不可见,并不需要同步。
多线程同时读写共享变量时,会造成逻辑错误,因此需要通过同步;
同步的本质就是给指定对象加锁,加锁后才能继续执行后续代码;
注意加锁对象必须是同一个实例;


