
理论上主库有更新时,备库都存在延迟,且延迟时间为备库执行时间+网络传输时间即t4-t2。
那么mysql是怎么来计算备库延迟的?
先来看show slave status中的一些信息,io线程拉取主库binlog的位置:
sql线程执行relay log的位置:
Relay_Log_Pos: 253
sql线程执行的relay log相对于主库binlog的位置:
Relay_Master_Log_File: mysql-bin.000001Exec_Master_Log_Pos: 107
源码实现
Seconds_Behind_Master计算的源码实现如下:
大致可以看出是通过时间和位点来计算的,下面详细分析下。
if里面条件表示如果io线程拉取主库binlog的位置和sql线程执行的relay log相对于主库binlog的位置相等,那么认为延迟为0。一般情况下,io线程比sql线程快。但如果网络状况特别差,导致sql线程需等待io线程的情况,那么这两个位点可能相等,会导致误认为延迟为0。
再看else里:
clock_diff_with_masterio线程启动时会向主库发送sql语句“SELECT UNIX_TIMESTAMP()”,获取主库当前时间,然而用备库当前时间减去此时间或者主备时间差值即为clock_diff_with_master。这里如果有用户中途修改了主库系统时间或修改了timestamp变量,那么计算出备库延迟时间就是不准确的。
非并行复制: 备库sql线程读取了relay log中的event,event未执行之前就会更新last_master_timestamp,这里时间的更新是以event为单位。
rli->last_master_timestamp= ev->when.tv_sec + (time_t) ev->exec_time;
并行复制:
并行复制更新gap checkpiont时,会推进lwm点,同时更新last_master_timestamp为lwm所在事务结束的event的时间。因此,并行复制是在事务执行完成后才更新last_master_timestamp,更新是以事务为单位。同时更新gap checkpiont还受slave_checkpoint_period参数的影响。
这导致并行复制下和非并行复制统计延迟存在差距,差距可能为 + 事务在备库执行的时间。这就是为什么在并行复制下有时候会有很小的延迟,而改为非并行复制时反而没有延迟的原因。
另外当sql线程等待io线程时且gaq队列为空时,会将last_master_timestamp设为0。同样此时认为没有延迟,计算得出seconds_Behind_Master为0。
io线程拉取binlog的位点
Master_Log_File 读取到主库ROTATE_EVENT时会更新(process_io_rotate)Read_Master_Log_Pos:io线程每取到一个event都会从event中读取pos信息并更新mi->set_master_log_pos(mi->get_master_log_pos() + inc_pos);
sql线程执行relay log的位置
sql线程执行的relay log相对于主库binlog的位置
Relay_Master_Log_Filesql线程处理ROTATE_EVENT时更新(Rotate_log_event::do_update_pos)Exec_Master_Log_Pos 和Relay_Log_Pos同时更新并行复制时,事务完成时更新(Rotate_log_event::do_update_pos/ Xid_log_event::do_apply_event/stmt_done)
谈到位点更新就有必要说到两个事件:HEARTBEAT_LOG_EVENT 和 ROTATE_EVENT。
HEARTBEAT_LOG_EVENT HEARTBEAT_LOG_EVENT我们的了解一般作用是,在主库没有更新的时候,每隔
master_heartbeat_period时间都发送此事件保持主库与备库的连接。而HEARTBEAT_LOG_EVENT另一个作用是,在gtid模式下,主库有些gtid备库已经执行同时,这些事件虽然不需要再备库执行,但读取和应用binglog的位点还是要推进。因此,这里将这类event转化为HEARTBEAT_LOG_EVENT,由HEARTBEAT_LOG_EVENT帮助我们推进位点。ROTATE_EVENT
主库binlog切换产生的ROTATE_EVENT,备库io线程收到时会也有切换relay log。此rotate也会记入relay log,sql线程执行ROTATE_EVENT只更新位点信息。备库io线程接受主库的HEARTBEAT_LOG_EVENT,一般不用户处理。前面提到,gtid模式下,当HEARTBEAT_LOG_EVENT的位点大于当前记录的位点时,会构建一个ROTATE_EVENT,从而让sql线程推进位点信息。
if (mi->is_auto_position() && mi->get_master_log_pos() < hb。log_pos&& mi->get_master_log_name() != NULL){write_ignored_events_info_to_relay_log(mi->info_thd, mi); //构建ROTATE_EVENT......}
另外,在replicate_same_server_id为0时,备库接收到的binlog与主库severid相同时,备库会忽略此binlog,但位点仍然需要推进。为了效率,此binlog不需要记入relay log。而是替换为ROTATE_EVENT来推进位点。
延迟现象
不考虑网络延迟。
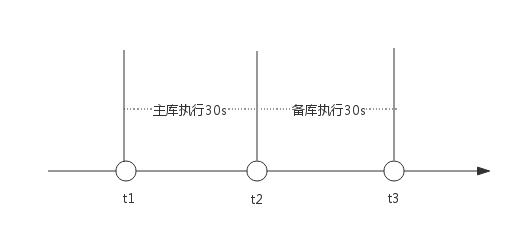
并行复制时
执行DDL:t2时刻主库执行完,t2至t3备库执行show slave status,Seconds_Behind_Master值一直为0
执行大事务:t2时刻主库执行完,t2至t3备库执行show slave status,Seconds_Behind_Master值一直为0
这是因为执行语句之前主备是完全同步的,gaq队列为空,会将
last_master_timestamp设为0。而执行DDL过程中,gap checkpoint一直没有推进,last_master_timestamp一直未0,直到DDL或大事务完成。 所以t2至t3时刻Seconds_Behind_Master值一直为0。而t3时刻有一瞬间last_master_timestamp是会重置的,但又因slave_checkpoint_period会推进checkpoint,gaq队列变为空,会将last_master_timestamp重设为0。 因此t3时刻可能看到瞬间有延迟(对于DDL是延迟30s,对于大事务时延迟60s)。这似乎很不合理,gaq队列为空,会将
last_master_timestamp设为0,这条规则实际可以去掉。
BUG#72376, PREVIOUS_GTIDS_LOG_EVENT 事件记录在每个binlog的开头,表示先前所有文件的gtid集合。relay-log本身event记录是主库的时间,但relay log开头的PREVIOUS_GTIDS_LOG_EVENT事件,是在slave端生成的,时间也是以slave为准的。因此不能用此时间计算last_master_timestamp。修复方法是在relay log写PREVIOUS_GTIDS_LOG_EVENT事件是标记是relay log产生的,在统计last_master_timestamp时,发现是relay产生的事件则忽略统计。
总结
Seconds_Behind_Master的计算并不准确和可靠。并行复制下Seconds_Behind_Master值比非并行复制时偏大。因此当我们判断备库是否延迟时,根据Seconds_Behind_Master=0不一定可靠。但是,当我们进行主备切换时,在主库停写的情况下,我们可以根据位点来判断是否完全同步。

