
场景引入
假设某公司有一个非常重要的超大的数据库(超过10TB),面临如下场景:
该数据库中存储了近10年的用户支付信息(payment),非常重要
每年的数据归档存储在年表中,历史年表中的数据只读不写(历史payment信息无需再修改),只有当前年表数据既读又写
每次数据库全备耗时太长,超过20小时;数据库还原操作耗时更长,超过30小时
如何优化设计这个数据库以及备份恢复系统,可以使得备份、还原更加高效?
文件组的详细介绍不是本次分享的重点,但是作为本文介绍的核心技术,有必要对其优点、创建以及使用方法来简单介绍SQL Server中的文件组。
SQL Server支持将表、索引数据存放到非Primary文件组,这样当数据库拥有多个文件组时就具备了如下好处:
分散I/O压力到不同的文件组上,如果不同文件组的文件位于不同的磁盘的话,可以分散磁盘压力。
针对不同的文件组进行DBCC CHECKFILEGROUP操作,并且同一个数据库可以多个进程并行处理,减少大数据维护时间。
可以针对文件组级别进行备份和还原操作,更细粒度控制备份和还原策略。
创建数据库时创建文件组
我们可以在创建数据库时直接创建文件组,代码如下:
注意: 为了保证数据库文件组I/O的负载均衡能力,请将所有文件的初始大小和自动增长参数保持一致,以保证轮询调度分配算法正常工作。
单独创建创建组
如果数据库已经存在,我们也同样有能力添加文件组,代码如下:
USE masterGOALTER DATABASE [TestFG] ADD FILEGROUP [FG2013];-- Add data file to FG2013ALTER DATABASE [TestFG]ADD FILE (NAME = FG2013, SIZE = 5MB , FILEGROWTH = 50MB ,FILENAME = N'C:\SQLServer\Data\FG2013.ndf')TO FILEGROUP [FG2013]GOUSE [TestFG]GOSELECT * FROM sys.filegroups
最终文件组信息,展示如下:
文件组创建完毕后,我们可以将表和索引放到对应的文件组。比如: 将聚集索引放到PRIMARY文件组;表和索引数据放到FG2010文件组,代码如下:
USE [TestFG]GOCREATE TABLE [dbo].[Orders_2010]([OrderID] [int] IDENTITY(1,1) NOT NULL,[OrderDate] [datetime] NULL,CONSTRAINT [PK_Orders_2010] PRIMARY KEY CLUSTERED([OrderID] ASC) ON [PRIMARY]) ON [FG2010]GOCREATE NONCLUSTERED INDEX IX_OrderDateON [dbo].[Orders_2010] (OrderDate)ON [FG2010];
方案设计
文件组的基本知识点介绍完毕后,根据场景引入中的内容,我们将利用SQL Server文件组技术来实现冷热数据隔离备份的方案设计介绍如下。
设计分析
由于payment数据库过大,超过10TB,单次全量备份超过20小时,如果按照常规的完全备份,会导致备份文件过大、耗时过长、甚至会因为备份操作对I/O能力的消耗影响到正常业务。我们仔细想想会发现,虽然数据库本身很大,但是,由于只有当前年表数据会不断变化(热数据),历史年表数据不会修改(冷数据),因此正真有数据变化操作的数据量相对整个库来看并不大。那么,我们将数据库设计为历史年表数据放到Read only的文件组上,把当前年表数据放到Read write的文件组上,备份系统仅仅需要备份Primary和当前年表所在的文件组即可(当然首次还是需要对数据库做一次性完整备份的)。这样既可以大大节约备份对I/O能力的消耗,又实现了冷热数据的隔离备份操作,还达到了分散了文件的I/O压力,最终达到数据库设计和备份系统优化的目的,可谓一箭多雕。
以上文字分析,画一个漂亮的设计图出来,直观展示如下: 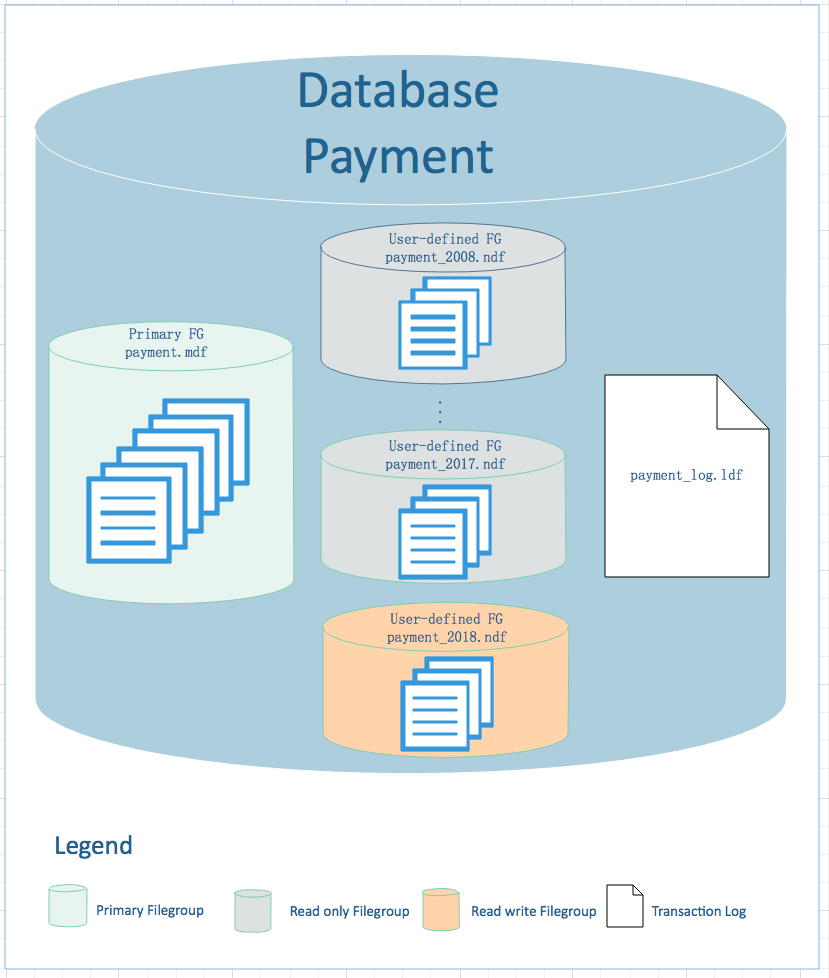
设计图说明
1个主文件组(Primary File Group):用户存放数据库系统表、视图等对象信息,文件组可读可写。
10个用户自定义只读文件组(User-defined Read Only File Group):用于存放历史年表的数据及相应索引数据,每一年的数据存放到一个文件组中。
1个用户自定义可读写文件组(User-defined Read Write File Group):用于存放当前年表数据和相应索引数据,该表数据必须可读可写,所以文件组必须可读可写。
1个数据库事务日志文件:用于数据库事务日志,我们需要定期备份数据库事务日志。
设计方案完成以后,接下来就是方案的集体实现了,具体实现包括:
创建数据库
创建年表
文件组设置
冷热备份实现
创建数据库的同时,我们创建了Primary文件组和2008 ~ 2017的文件组,这里需要特别提醒,请务必保证所有文件组中文件的初始大小和增长量相同,代码如下:
USE masterGOEXEC sys.xp_create_subdir 'C:\DATA\Payment\Data\'EXEC sys.xp_create_subdir 'C:\DATA\Payment\Log\'CREATE DATABASE [Payment]ON PRIMARY( NAME = N'Payment', FILENAME = N'C:\DATA\Payment\Data\Payment.mdf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2008]( NAME = N'FGPayment2008', FILENAME = N'C:\DATA\Payment\Data\Payment_2008.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2009]( NAME = N'FGPayment2009', FILENAME = N'C:\DATA\Payment\Data\Payment_2009.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2010]( NAME = N'FGPayment2010', FILENAME = N'C:\DATA\Payment\Data\Payment_2010.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2011]( NAME = N'FGPayment2011', FILENAME = N'C:\DATA\Payment\Data\Payment_2011.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2012]( NAME = N'FGPayment2012', FILENAME = N'C:\DATA\Payment\Data\Payment_2012.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),( NAME = N'FGPayment2013', FILENAME = N'C:\DATA\Payment\Data\Payment_2013.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2014]( NAME = N'FGPayment2014', FILENAME = N'C:\DATA\Payment\Data\Payment_2014.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2015]( NAME = N'FGPayment2015', FILENAME = N'C:\DATA\Payment\Data\Payment_2015.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2016]( NAME = N'FGPayment2016', FILENAME = N'C:\DATA\Payment\Data\Payment_2016.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB ),FILEGROUP [FGPayment2017]( NAME = N'FGPayment2017', FILENAME = N'C:\DATA\Payment\Data\Payment_2017.ndf' , SIZE = 5MB ,FILEGROWTH = 50MB )LOG ONGO
考虑到每年我们都要添加新的文件组到数据库中,因此2018年的文件组单独创建如下:
最终再次确认数据库文件组信息,代码如下:
USE [Payment]GOSELECT file_name = mf.name, filegroup_name = fg.name, mf.physical_name,mf.size,mf.growthFROM sys.master_files AS mfINNER JOIN sys.filegroups as fgON mf.data_space_id = fg.data_space_idWHERE mf.database_id = db_id('Payment')ORDER BY mf.type;
结果展示如下图所示:
创建年表
数据库以及相应文件组创建完毕后,接下来我们创建对应的年表并插入一些测试数据,如下:
USE [Payment]GOCREATE TABLE [dbo].[Payment_2008]([Payment_ID] [bigint] IDENTITY(12008,100) NOT NULL,[OrderID] [bigint] NOT NULL,CONSTRAINT [PK_Payment_2008] PRIMARY KEY CLUSTERED([Payment_ID] ASC) ON [FGPayment2008]) ON [FGPayment2008]GOCREATE NONCLUSTERED INDEX IX_OrderIDON [dbo].[Payment_2008] ([OrderID])ON [FGPayment2008];CREATE TABLE [dbo].[Payment_2009]([Payment_ID] [bigint] IDENTITY(12009,100) NOT NULL,[OrderID] [bigint] NOT NULL,CONSTRAINT [PK_Payment_2009] PRIMARY KEY CLUSTERED([Payment_ID] ASC) ON [FGPayment2009]) ON [FGPayment2009]GOCREATE NONCLUSTERED INDEX IX_OrderIDON [dbo].[Payment_2009] ([OrderID])ON [FGPayment2009];--这里省略了2010-2017的表创建,请参照以上建表和索引代码,自行补充CREATE TABLE [dbo].[Payment_2018]([Payment_ID] [bigint] IDENTITY(12018,100) NOT NULL,[OrderID] [bigint] NOT NULL,CONSTRAINT [PK_Payment_2018] PRIMARY KEY CLUSTERED([Payment_ID] ASC) ON [FGPayment2018]) ON [FGPayment2018]GOCREATE NONCLUSTERED INDEX IX_OrderIDON [dbo].[Payment_2018] ([OrderID])ON [FGPayment2018];
这里需要特别提醒两点:
限于篇幅,建表代码中省略了2010 - 2017表创建,请自行补充
每个年表的Payment_ID字段初始值是不一样的,以免查询所有payment信息该字段值存在重复的情况
其次,我们检查所有年表的文件组分布情况如下:
GOSELECT table_name = tb.[name], index_name = ix.[name], located_filegroup_name = fg.[name]FROM sys.indexes ixINNER JOIN sys.filegroups fgON ix.data_space_id = fg.data_space_idON ix.[object_id] = tb.[object_id]WHERE ix.data_space_id = fg.data_space_idGO
最后,为了测试,我们在对应年表中放入一些数据:
文件组设置
年表创建完完毕、测试数据初始化完成后,接下来,我们做文件组读写属性的设置,代码如下:
USE masterGOALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2008] READ_ONLY;ALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2009] READ_ONLY;--这里省略了2010 - 2017文件组read only属性的设置,请自行补充ALTER DATABASE [Payment] MODIFY FILEGROUP [FGPayment2018] READ_WRITE;
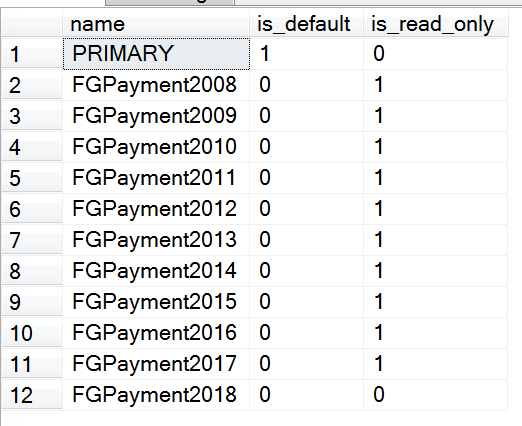
最终我们的文件组读写属性如下:
USE [Payment]GOSELECT name, is_default, is_read_only FROM sys.filegroupsGO
截图如下:
所有文件组创建成功,并且读写属性配置完毕后,我们需要对数据库可读写文件组进行全量备份、差异备份和数据库级别的日志备份,为了方便测试,我们会在两次备份之间插入一条数据。备份操作的大体思路是:
首先,对整个数据库进行一次性全量备份
其次,对可读写文件组进行周期性全量备份
接下来,对可读写文件组进行周期性差异备份
最后,对整个数据库进行周期性事务日志备份
--Take a one time full backup of payment databaseUSE [master];GOBACKUP DATABASE [Payment]TO DISK = N'C:\DATA\Payment\BACKUP\Payment_20180316_full.bak'WITH COMPRESSION, Stats=5;GO-- for testing, init one recordUSE [Payment];GOINSERT INTO [dbo].[Payment_2018] SELECT 201801;GO--Take a full backup for each writable filegoup (just backup FGPayment2018 as an example)BACKUP DATABASE [Payment]FILEGROUP = 'FGPayment2018'TO DISK = 'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_full.bak'WITH COMPRESSION, Stats=5;GO-- for testing, insert one recordINSERT INTO [dbo].[Payment_2018] SELECT 201802;GO--Take a differential backup for each writable filegoup (just backup FGPayment2018 as an example)BACKUP DATABASE [Payment]FILEGROUP = N'FGPayment2018'TO DISK = N'C:\DATA\Payment\BACKUP\Payment_FGPayment2018_20180316_diff.bak'WITH DIFFERENTIAL, COMPRESSION, Stats=5;GO-- for testing, insert one recordINSERT INTO [dbo].[Payment_2018] SELECT 201803;GO-- Take a transaction log backup of database paymentBACKUP LOG [Payment]TO DISK = 'C:\DATA\Payment\BACKUP\Payment_20180316_log.trn';GO
这样备份的好处是,我们只需要对可读写的文件组(FGPayment2018)进行完整和差异备份(Primary中包含系统对象,变化很小,实际场景中,Primary文件组也需要备份),而其他的9个只读文件组无需备份,因为数据不会再变化。如此,我们就实现了冷热数据隔离备份的方案。 接下来的一个问题是,万一Payment数据发生灾难,导致数据损失,我们如何从备份集中将数据库恢复出来呢?我们可以按照如下思路来恢复备份集:
首先,还原整个数据库的一次性全量备份
其次,还原所有可读写文件组最后一个全量备份
接下来,还原可读写文件组最后一个差异备份
最后,还原整个数据库的所有事务日志备份
最后检查数据还原的结果,按照我们插入的测试数据,应该会有四条记录。
USE [Payment_Dev]GO
展示执行结果,有四条结果集,符合我们的预期,截图如下:

