
在并行复制之前,SQL线程的恢复很简单,从 relay-log.info 中取得上次执行到的位点,然后从这个位点开始执行即可。有了并行复制之后,情况就变得稍微复杂了些,worker 线程各自执行自己队列的事务,在或者 mysqld crash的时候,队列中的事务很可能没有执行完,比如crash时GAQ的状态如下图1所示,中间存在空隙(gap),先分发给 worker a 的事务还未完成,而后分发给 worker b 的事务已经完成,对应就是 relay log 中间有一部分event没执行。我们知道,SQL执行或者分发是顺序读relay log的,如果恢复时从 2 开始执行,3 和 4就会重复执行,如果从4开始执行,2就会被跳过,都不行。并行复制恢复的逻辑就是把 2 找出来执行,把空隙给填上,然后SQL线程就可以 5 开始愉快地跑下去了。
图1. GAQ中的空隙
恢复离不开信息的持久化,每个worker线程对应一个worker.info,定期将执行位点信息刷入worker.info。类似于relay-log.info,worker.info 可以存在表中,也可以存在文件中,取决于配置relay_log_info_repository,刷写频率由 sync_relay_log_info 控制。
下面是relay-log.info中存的信息:
下面是worker.info中存的信息:
本节介绍对 Slave_worker::group_executed 这个bitmap的操作,在此之前需要介绍另一个变量 Relay_log_info::checkpoint_seqno,对 Coordinator 线程来说,表示从上次checkpoint调整后,下一个分发的事务编号,同时对应GAQ中事务(Slave_job_group)的个数,我们在上期介绍过,GAQ中存的是Coordinator 线程分发的、尚未被checkpoint出队的事务(可能已经被worker执行完了);对woker线程来说,这个对应当前worker执行到的事务编号。
Coordinator 线程每分发一个事务,checkpoint_seqno 加 1;每次checkpoint后,会将 checkpoint_seqno 减去cnt(cnt为checkpoint时GAQ中出队的事务的个数)。worker 线程每执行完一个事务,会将 group_executed 的 checkpoint_seqno 位置1;如果遇到checkpoint,会将bitmap向左移位。
如下图所示,GAQ中第0、2、5个事务分发给了worker a,第0个已经执行完成,所以 worker a 的 bitmap 中,第0位置1;worker b 和 worker c 的 bitmap 同理,标识已经执行的事务。
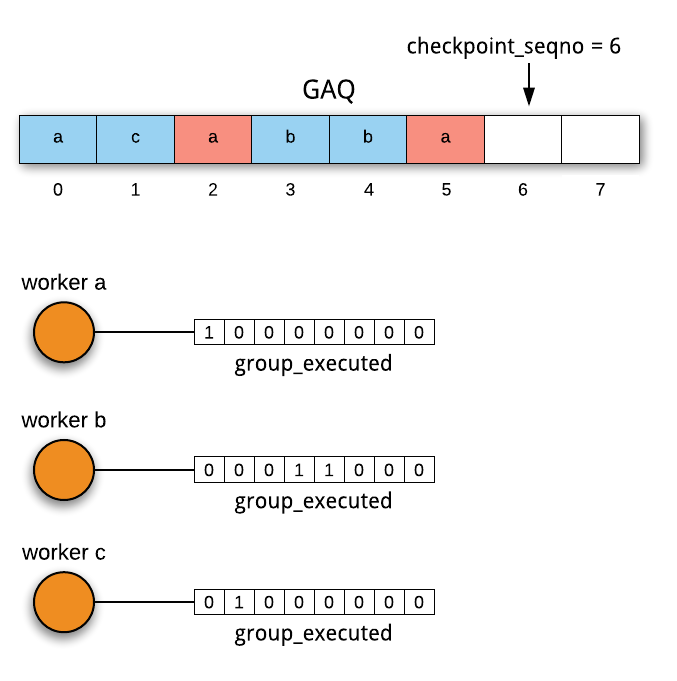
图2. worker的bitmap
假设这个时候 Coordinator 线程做了一次 checkpoint,将队列头部2个已经完成的事务出队,然后将rli->checkpoint_seqno减2,同时将2累加到每个 worker->bitmap_shifted 中,当Coordinator 线程将新的事务分给worker的时候,会将 worker->bitmap_shifted 取出,存人当前 中,当worker执行到这个group,就开始对 group_executed 进行偏移,偏移量就是Slave_job_group.shitfed (再一次说明了GAQ中的Slave_job_group,充当了Coordinator 线程和worker线程通信的角色)。bitmap的变化就如下图所示,checkpoint后,原来的0和1出队,然后新的4、5、6加入进来,新分发给worker b 和 worker c 的 4 和 6 已经执行完成,所以bitamp和上图相比,已经向左路偏移了2位,而新分发worker a的5并示执行,所以worker a 的bitmap还未偏移。
图3. checkpoint后worker的bitmap
group_executed bitmap的长度和GAQ大小一样,由配置slave_checkpoint_group决定。
恢复的主要逻辑是mts_recovery_groups() 这个函数。
在启动slave的时候,如果relay-log.info中存的Number_of_workers不为0,就说明之前是并行复制,然后调用 mts_recovery_groups(),进入恢复逻辑。如前所述,mts_recovery_groups() 的目的就是根据 slave_worker_info 和 slave_info 中信息,把空隙事务找出来。
首先会创建 Number_of_workers 个 worker,依次把每个worker.info的信息读出来,然后把worker执行位点信息和relay-log.info中记录的位点信息(低水位)相比,如果比后者小,说明崩溃前已经被checkpoint出队,不可能造成空隙,直接跳过;如果比后者大,就把worker存入 above_lwm_jobs 数组。 above_lwm_jobs收集完成后,初始化bitmap ,用来汇总每个worker的bitmap。对 above_lwm_jobs 中的每个worker,设置一个计数器recovery_group_cnt,从低水位位点开始扫relay log,每扫完一个事务,recovery_group_cnt加1,直到扫到worker.info中记录的位点为止,之后把worker的bitmap汇总到rli->recovery_groups中,其间会统计一个最大的 recovery_group_cnt,记入rli->mts_recovery_group_cnt,这个对应高水位。 bitmap 汇总逻辑如下:
之后SQL线程就可以从低水位往高水位扫relay log,对于每个事务,如果 rli->recovery_groups 对应bit为1,说明崩溃前已经执行过,就跳过;反之,就对事务中的每个event调用 执行。扫描到高水位后整个恢复逻辑结束,后面SQL线程就进入正常的执行逻辑,执行(串行)或者分发(并行)event。

