
简介
MySQL 的语法分析器采用的工具是 bison,对应的语法文件是 sql/sql_yacc.yy。bison 处理语法文件的输出是 sql/sql_yacc.cc 和 sql/sql_yacc.h。对应的 sql/CMakeLists.txt 中有相关的 make 规则:
实际在 make 的时候,这个过程比较复杂。也可以单独 make 词法语法分析的部分,例如:
阅读代码的时候,可以查找 MYSQLparse,以找到语法分析的代码路径。下面是清除掉生成的 yacc 代码再查找的结果:
MySQL 手工打造的词法分析器对应的源代码文件是 sql/sql_lex.h 和 sql/sql_lex.cc。词法分析的入口函数是 MYSQLlex()。解析出一个 token 的函数为 lex_one_token()。词法分析出来的每个 token 都会对应一个语法分析器中的终结符,它们的字符串表示在 sql/lex.h 中。这些符号被分为两组,SQL 关键字以及 SQL 函数,在代码中对应数组 symbols[] 和 sql_functions[]。通常而言,在语法/词法分析过程中为了判断某个 token 是否为 SQL 的关键字,可以直接二分查找字符串数组。考虑到关键字列表是固定的一个集合,MySQL 对此作了专门的优化,用 Trie 树来进一步提高效率。下一节介绍这部分代码的实现。
查找树的实现
查找树的产生用的是一个独立的小程序 gen_lex_hash[.cc]。CMake 产生的 Makefile 规则为在文件 sql/CMakeFiles/sql.dir/build.make 中:
可以看到,它产生的代码在 sql/lex_hash.h 中。里头包含了两个大数组:sql_functions_map[] 和 symbols_map[],以及一个函数 get_hash_symbol()。
具体的实现自然分为两个部分,一个是产生树,另一个是查找产生的树。
注:上图是使用 Graphviz 产生的。
文件 gen_lex_hash.cc 的代码注释中有一个树的示例:
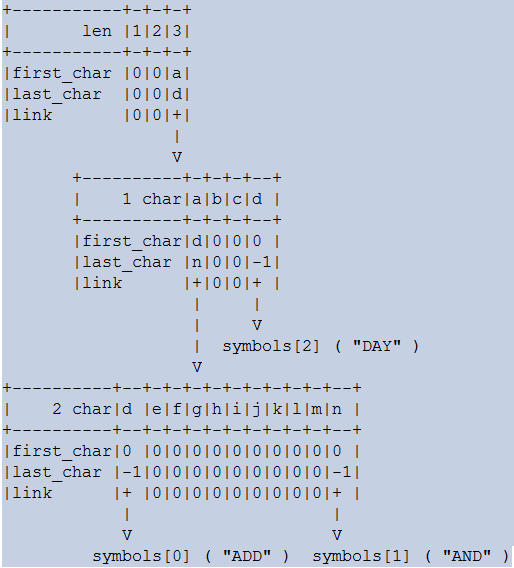
可以看出,根节点是按照字符串长度从小到大排序组织的。对于每种长度的字符串,要记录首字母和尾字母以及下一层节点的指针。中间节点除了是按照字符从小到大排序外,其它部分与根节点相同。叶子节点就是 symbols 数组的成员。树的查找就是一个自然的遍历过程。
树的产生
理解了上面的树的结构,就很好理解树的产生逻辑了。它的做法是读取关键字数组,产生一个原始的查找树(参看函数 generate_find_structs);然后,调整这个树,产生一个数组,也就是不用链表表示的树(参看函数 print_find_structs)。主要的函数和调用关系如下:
为了更好的理解,可以在处理到输入数组不同位置时,查看当时对应的树。例如:
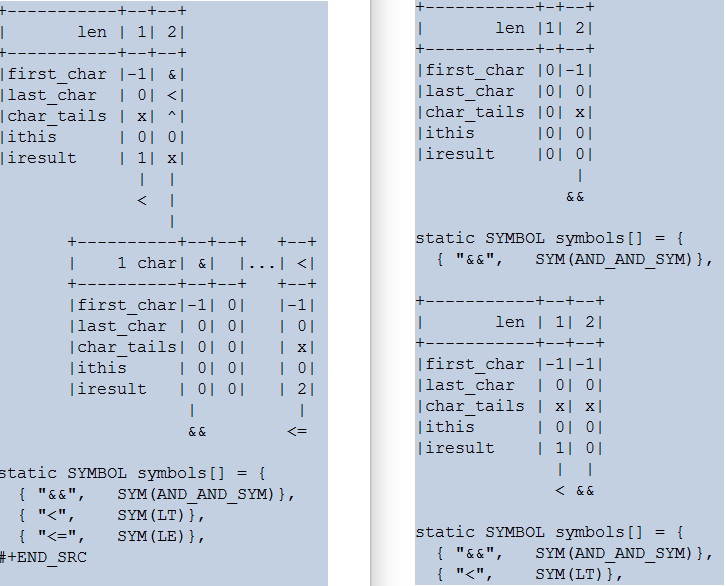
如果要验证一下这个优化与普通的折半查找的性能差异,需要做一些适当的修改才行。测试中用 perf 之类的工具会发现比较函数会成为热点。在修改代码时需要注意:
- symbols、sql_functions 这两个数组不一定是按照顺序排列的,需要认真确认。
- 查找符号时,字符串并没有以 ‘\0’ 结尾,做比较要注意。
总结
本文是基于 MySQL 5.6 做的分析。可以看到 MySQL 对词法分析中的关键字查找热点做了性能改进。也可以发现代码的结构不是特别清晰,存在一些代码冗余和明显的可改进之处。 WL#8016: Parser for optimizer hints 在重构的过程中顺便将其改掉了。
1 MySQL: Query Parsing
2 MySQL Download
3 Graphviz

