
Bottom-up解析是从parse tree底层开始向上构造,然后将每个token移进(shift),进而规约(reduce)为较大的token,最终按照语法规则的定义将所有token规约(reduce)成为一个token。移进过程是有先后顺序的,如果按照某种顺序不能将所有token规约为一个token,解析器将会回溯重新选定规约顺序。如果在规约(reduce)的过程中出现了既可以移进生成一个新的token,也可以规约为一个token,这种情况就是我们通常所说的shift/reduce conflicts.
Top-down解析是从parse tree的顶层开始向下构造历。这种解析的方法是假定输入的解析字符串是符合当前定义的语法规则,按照规则的定义自顶开始逐渐向下遍历。遍历的过程中如果出现了不满足语法内部的逻辑定义,解析器就会报出语法错误。
如果愿意详细了解这两种parser的却别,可以参考https://qntm.org/top。
Bison是一个bottom-up的parser。但是由于历史原因,MySQL的语法输入是按照Top-down的方式来书写的。这样的方式导致MySQL的parser语法上有包含了很多的reduce/shift conflicts;另外由于一些空的或者冗余的规则定义也使得的MySQL parser越来越复杂。为了应对未来越来越多的语法规则,以及优化MySQL parser的解析性能,MySQL 8.0对MySQL parser做了非常大的改进。当前的MySQL 8.0.1 Milestone release的代码中对于Parser的改进仍未全部完成,还有几个相关的worklog在继续。
改进之后,MySQL parser可以达到如下状态:
- 减少parse tree上的中间节点,减少冗余规则
- 更少的reduce/shift conflicts
- 语法解析阶段,只包含以下简单操作:
- 返回解析的最终状态信息
- 有限的访问系统变量
- MySQL parser执行流程将会由
变成
SQL input -> lex. scanner -> parser -> parse tree -> AST -> executor
下面我们通过看一个MySQL 8.0 中对SELECT statement所做的修改来看一下MySQL parser的改进。
SELECT statement可以说是MySQL中用处非常广泛的一个语句,比如CREATE VIEW, SELECT, CREATE TABLE, UNION, SUBQUERY等操作。 通过下图我们看一下MySQL8.0之前的版本是如何支持这些语法规则的。
MySQL8.0中对于这些语法规则的支持如下图: 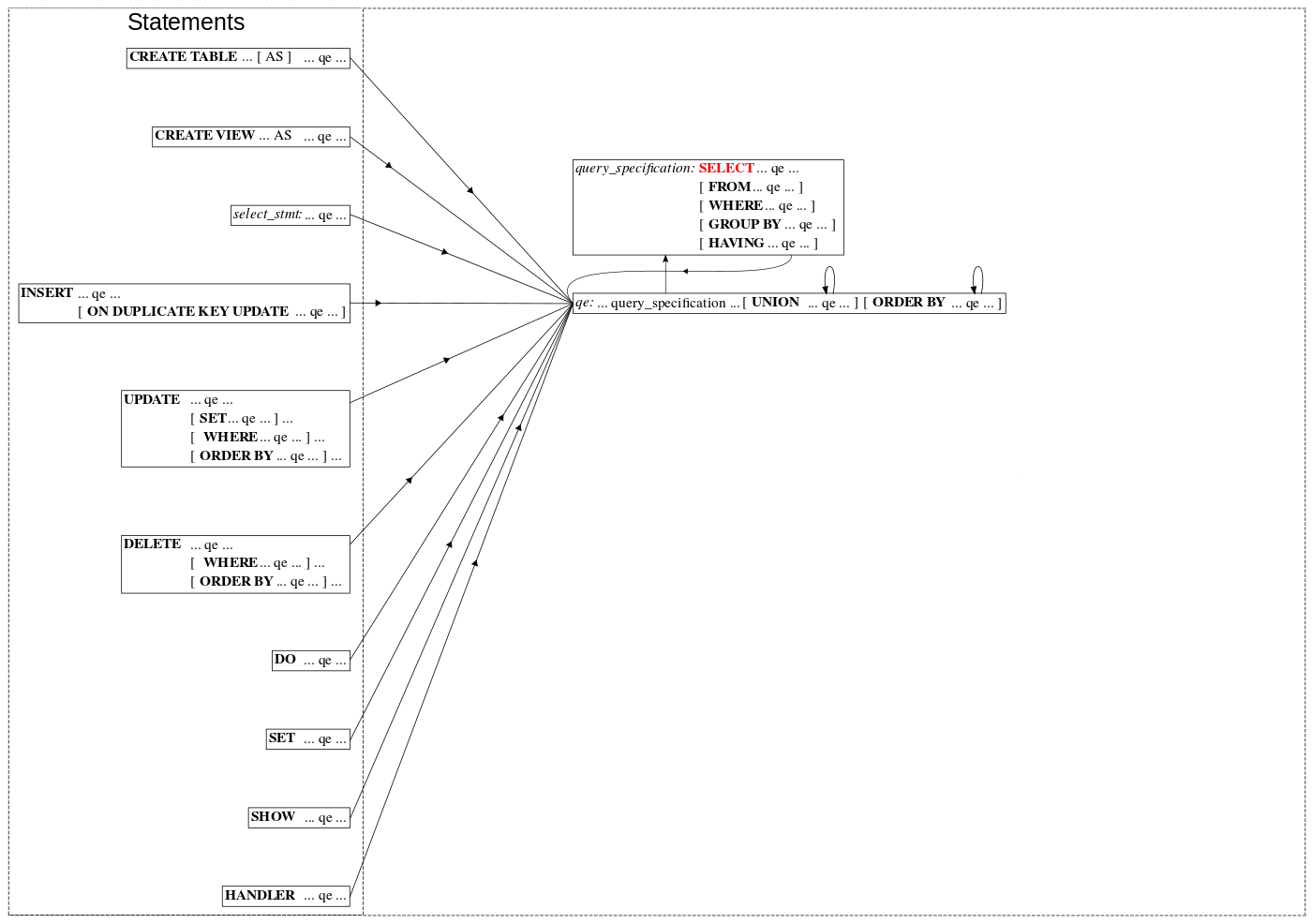
下面我们看看MySQL 8.0是如何将所有的SELECT statement操作定义为一个Query specification,并为所有其他操作所引用的:
Parse tree上所有的node都定义为Parse_tree_node的子类。Parse_tree_node的结构体定义如下:
当前MySQL8.0的源码中执行流程为:
接下来我们以SELECT statement来看一下PT_SELECT_STMT::contexualize()做些什么工作:
综上我们以SELECT statement为例对MySQL8.0在MySQL parser方面所做的改进进行了简单介绍。这样的改进对于MySQL parser也许是一小步,但对于MySQL未来的可扩展确实是迈出了一大步。Parse tree独立出来,通过Parse tree再来构建AST,这样的方式下将简化MySQL对于Parse tree的操作,最大的受益者就是Prepared statement。等到MySQL parse的所有worklog完成之后,MySQL用户期盼多年的global prepared statement也就顺其自然实现了。

