
- 自然语言模式(),即通过MATCH AGAINST 传递某个特定的字符串来进行检索。
布尔模式(IN BOOLEAN MODE),可以为检索的字符串增加操作符,例如“+”表示必须包含,“-”表示不包含,“*”表示通配符(这种情况, 即使传递的字符串较小或出现在停词中,也不会被过滤掉),其他还有很多特殊的布尔操作符,可以通过如下参数控制:
查询扩展模式(), 这种模式是自然语言模式下的一个变种,会执行两次检索,第一次使用给定的短语进行检索,第二次是结合第一次相关性比较高的行进行检索。
目前MySQL支持在CHAR、VARCHAR、TEXT类型的列上定义全文索引。
本文只是简单的分析了全文索引涉及到的代码模块以及5.7的一些新特性,源码部分基于MySQL5.7.8-rc版本,更细节的部分并未深入。
创建全文索引
如下例所示,一个简单的创建带全文索引表的SQL:
磁盘上会产生多个文件:
$ls -lh /u01/my57/data/test/total 1.3MFTS_000000000000010b_0000000000000154_INDEX_1.ibdFTS_000000000000010b_0000000000000154_INDEX_2.ibdFTS_000000000000010b_0000000000000154_INDEX_3.ibdFTS_000000000000010b_0000000000000154_INDEX_4.ibdFTS_000000000000010b_0000000000000154_INDEX_5.ibdFTS_000000000000010b_0000000000000154_INDEX_6.ibdFTS_000000000000010b_BEING_DELETED_CACHE.ibdFTS_000000000000010b_BEING_DELETED.ibdFTS_000000000000010b_CONFIG.ibdFTS_000000000000010b_DELETED_CACHE.ibdFTS_000000000000010b_DELETED.ibdt1.frmt1.ibd
除了t1.frm和t1.ibd外,共分为以下几类表
FTS_000000000000010b_0000000000000154_INDEX_1~6.ibd这6个文件用于存储倒排索引,存储的是分词和位置以及document ID,根据分词的第一个字符值进行分区,映射到不同的文件中; 文件的命名规则为FTS_{TABLE_ID}_{INDEX_ID}_INDEX_{N}.ibd
FTS_000000000000010b_DELETED.ibd 包含已经被删除的DOC_ID,但还没从全文索引数据中删掉; FTS_000000000000010b_DELETED_CACHE.ibd 是前者的内存缓存(但是搜索了下代码,只有当
fts_cache_t::deleted_doc_ids被使用时,才会在sync时转储到该表中,但并没有发现任何地方使用这个对象)FTS_000000000000010b_BEING_DELETED_CACHE.ibd 和 FTS_000000000000010b_BEING_DELETED.ibd,包含了已经被删除索引记录并且正在从全文索引中移除的DOC ID,前者是后者的内存版本,这两个表主要用于辅助进行OPTIMIZE TABLE时将DELETED/DELETED_CACHED表中的记录转储到其中。
FTS_000000000000010b_CONFIG.ibd,包含全文索引的内部信息,最重要的存储是FTS_SYNCED_DOC_ID,表示已经解析并刷到磁盘的doc id, 在崩溃恢复时,可以根据这个值判断哪些该重新解析并加入到索引cache中。
建全文索引辅助表函数参考:
ha_innobase::create|--> create_table_info_t::create_table|--> fts_create_common_tables
当对一个已经存在的表上创建全文索引时,InnoDB采用了fork多个线程进行并发构建全文索引项的方法,并发度由参数 innodb_ft_sort_pll_degree 控制。因此在restore一个全文索引表时,我们建议先建表、导入数据,再在表上创建全文索引。
参考函数:row_merge_read_clustered_index --> row_fts_start_psort 线程回调函数为fts_parallel_tokenization。
当表上存在全文索引时,就会隐式的建立一个名为FTS_DOC_ID的列,并在其上创建一个唯一索引,用于标识分词出现的记录行。你也可以显式的创建一个名为FTS_DOC_ID的列,但需要和隐式创建的列类型保持一致。
为了维护表上的全文索引信息,全文索引模块定义了大量的类来进行管理,总的来说如下图所示:
图1. 全文索引模块
普通DML及查询操作
我们可以通过INNODB_FT_INDEX_CACHE来检查插入记录的分词:
mysql> insert into t1 values (NULL, 'hello, welcome to mysql world');Query OK, 1 row affected (1.87 sec)mysql> set global innodb_ft_aux_table = 'test/t1';Query OK, 0 rows affected (0.00 sec)mysql> select * from INNODB_FT_INDEX_CACHE;+---------+--------------+-------------+-----------+--------+----------+| WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION |+---------+--------------+-------------+-----------+--------+----------+| hello | 2 | 2 | 1 | 2 | 0 || mysql | 2 | 2 | 1 | 2 | 18 || welcome | 2 | 2 | 1 | 2 | 7 |+---------+--------------+-------------+-----------+--------+----------+4 rows in set (0.00 sec)
在插入一条记录时,对应的堆栈如下:
row_insert_for_mysql|--> row_insert_for_mysql_using_ins_graph|--> fts_trx_add_op // state = FTS_INSERT
在向原表上插入完成记录后,会去判断表上是否有全文索引(DICT_TF2_FTS),如果有的话,则将插入记录对应的doc id提取出来(fts_get_doc_id_from_row),并缓存到事务对象中。
删除操作不会直接从全文索引里直接删除,因此依然可以从INNODB_FT_INDEX_CACHE中查到分词信息。
相关堆栈:
ha_innobase::delete_row|--> row_update_for_mysql|--> row_update_for_mysql_using_upd_graph|--> row_fts_update_or_delete|--> fts_trx_add_op // state = FTS_DELETE
更新非全文索引列,不会修改FTS_DOC_ID列的值。如果更新了全文索引列,在InnoDB的实现是删除老的DOC,并插入新的DOC。
堆栈为:
可见所有DML的操作,都走接口函数fts_trx_add_op,划分为两种操作: FTS_INSERT及FTS_DELETE;当前事务涉及的doc id被存储到trx->fts_trx中,在执行SQL的过程中并没有更新全文索引,而是在事务提交时进行的。
对于全文索引的查询,采用新的接口函数,分为两步:
根据检索词搜集符合条件的doc id。
JOIN::optimize|--> init_ftfuncs|--> Item_func_match::init_search|--> ha_innobase::ft_init_ext|--> fts_query
在搜集满足查询条件的doc id时,首先读取DELETED表中记录的doc id,这些doc id随后被用做过滤。
根据搜集到的doc id,找到对应的记录,使用的索引是
dict_table_t::fts_doc_id_index,也就是建立在隐藏列FTS_DOC_ID上的唯一索引。sub_select|--> join_ft_read_first|--> ha_innobase::ft_init|--> join_ft_read_next|--> ha_innobase::ft_read
通常查询返回的结果是根据rank排序的,InnoDB的全文检索排序规则和sphinx类似,基于 BM25 和 TF-IDF算法。
rank的计算算法如下:
${IDF} = log10( ${total_records} / ${matching_records} ) // total_records表示总的行记录数,matching_records表示匹配到检索字的行记录数${TF} 表示单词在文档中出现的次数${rank} = ${TF} * ${IDF} * ${IDF}
IDF的计算参阅函数:fts_query_calculate_idf ranking计算:fts_query_calculate_ranking
如果使用多个单词匹配,则把各个单词各自的rank累加起来。官方博客有一篇文章专门对此进行了介绍。
事务内回滚 正在事务内回滚某个语句,或者回滚到某个savepoint时,需要将对应的操作记录也要删除。维护了trx->fts_trx->last_stmt,在单条SQL结束时释放(trx_mark_sql_stat_end)。如果SQL回滚,就根据last_stmt中维护的doc id从全局savepoints中清理掉本条SQL的doc id。
相关堆栈:
innobase_rollback --> trx_rollback_last_sql_stat_for_mysql|--> fts_savepoint_rollback_last_stmt|--> fts_undo_last_stmt|--> trx_mark_sql_stat_end|--> fts_savepoint_laststmt_refresh
回滚到savepoint
innobase_rollback_to_savepoint|--> fts_savepoint_rollback
事务提交
相关堆栈:
trx_commit_low|--> fts_commit // 处理trx->fts_trx->savepoints中缓存的全文索引操作|--> fts_commit_table|--> fts_add|--> fts_add_doc_by_id|--> fts_delete|--> trx_commit_in_memory|--> trx_finalize_for_fts|--> trx_finalize_for_fts_table
在调用fts_commit时,会根据不同的操作类型,调用fts_add增加全文索引项,调用fts_delete删除全文索引项。
由于在插入记录时,先分词、分解成多个词插入辅助表中,因此一条insert可能产生多个小的插入,这种写入放大可能是不可承受的。InnoDB采用了一种优化的方案:创建一个内存cache,临时缓存插入操作,当cache满时再批量刷到磁盘,这样做的好处是:
- 避免重复存储相同的单词;
- cache size 通过参数
innodb_ft_cache_size控制; - 查询会将cache和磁盘数据进行merge。
在事务提交时,调用函数fts_add_doc_by_id:
- 首先根据doc id,使用doc_id所在的索引进行查询,找到刚刚插入的记录项对应的聚集索引记录;
- 遍历表上全部的聚集索引,根据全文索引对应的
fts_get_doc_t(fts_cache_t::get_docs)构建fts_doc_t,对文档根据选择的parser进行分词(fts_tokenize_document函数或者fts_tokenize_document_next),具体的文档存储到fts_doc_t::text中; - 将上一步获得的分词加入到cache中(
fts_cache_add_doc); - 如果当前cache的大小超过配置的
innodb_ft_cache_size,或者全局cache的大小超过innodb_ft_total_cache_size(fts_need_sync被设置为true),则进行一次sync,将该表缓存的数据刷到全文索引文件中(fts_sync),并清空cache。
和插入相似,删除操作也可能产生大量小的删除操作,为了避免这种情况,维持一个表,来记录被删除的doc id,但记录依然存在于原文件中。删除操作的提交函数为fts_delete,将被删除的记录doc_id插入到DELETED辅助表中。
事务模块涉及的几个关键类包括:
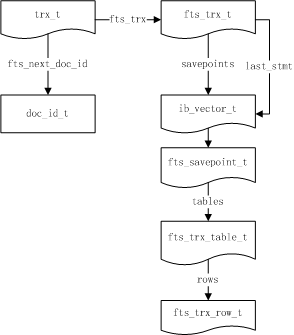
图2. 全文索引事务模块
同步缓存
在满足一定条件时,全文索引需要进行一次sync操作,将数据同步到全文索引文件中,大概包含以下集中情况需要sync:
- cache数据占用的内存超过限制;
- 后台线程
fts_optimize_thread在shutdown调用,将所有表进行一次sync; ha_innobase::optimize调用(执行optimize table);row_merge_read_clustered_index:创建一个新的临时表并读入数据后,进行一次sync调用。
同步操作的入口函数为fts_sync,大体流程为:
图3. 倒排索引结点存储结构
- 调用
fts_sync_commit提交sync操作:- 更新CONFIG表记录的最大SYNC的DOC ID(
fts_cmp_set_sync_doc_id); - 若
fts_cache_t::deleted_doc_ids不为空,将其加入到DELETED_CACHE辅助表中(fts_sync_add_deleted_cache); - 清空cache 并重新初始化。
- 更新CONFIG表记录的最大SYNC的DOC ID(
Optimize table
当你修改了某些配置(例如最小token size时),或者希望重组全文索引时,可以执行optimize table。由于原始optimize table操作会产生整个表的重建,耗时太久,因此InnoDB引入了一个参数innodb_optimize_fulltext_only来控制该行为。当开启该选项时,如果执行optimize table,就只优化全文索引,而不会去重建表,入口函数为ha_innobase::optimize:
首先调用函数fts_sync_table,将表上在内存中cache的数据刷到全文索引文件中; 然后调用函数fts_optimize_table,我们主要分析集中在第二步。
如果BEGING_DELETED表中没有数据(例如第一次调用optimized table),则将DELETED表中的数据转储到BEING_DELETED表中,相当于拿到了一个快照,执行的SQL操作为:
static const char* fts_init_delete_sql ="BEGIN\n""\n""INSERT INTO $BEING_DELETED\n""SELECT doc_id FROM $DELETED;\n""\n""INSERT INTO $BEING_DELETED_CACHE\n"
参考函数:fts_optimize_create_deleted_doc_id_snapshot
从BEING_DELETED/BEING_DELETED_CACHE表中读取已经被删除的doc id,这些doc id在随后的索引优化中将被忽略掉。 参考函数:
fts_optimize_read_deleted_doc_id_snapshot调用
fts_optimize_indexes对每个索引进行优化,相关堆栈如下:fts_optimize_indexes|--> fts_optimize_index|--> fts_optimize_index_read_words// 读入需要进行优化的分词,一轮优化的个数不超过innodb_ft_num_word_optimize的配置值// 缓存的分词数据采用zlib进行压缩|--> fts_optimize_words // 读取分词,将已经删除的doc id从其中清除,并回写到db|--> fts_index_fetch_nodes // 逐个读取分词对应的全文索引项|--> fts_optimize_compact|--> fts_optimize_word // 判断是否包含被删除的doc id,并重组记录|--> fts_optimize_write_word // 将记录写回索引,具体操作为先删除老的记录,再插入新的记录|--> fts_config_set_index_value //更新CONFIG表的FTS_LAST_OPTIMIZED_WORD列,记录最近重组优化的分词|--> fts_optimize_index_completed // 若上述步骤将读取的分词全部处理完了,则本轮optimize操作完成
当在所有索引上完成optimize后,调用fts_optimize_purge_snapshot,主要操作包括:
从DELETE和DELETE_CACHE表中将doc id删除,参考函数fts_optimize_purge_deleted_doc_ids
static const char* fts_delete_doc_ids_sql ="BEGIN\n""\n""DELETE FROM $DELETED WHERE doc_id = :doc_id1;\n""DELETE FROM $DELETED_CACHE WHERE doc_id = :doc_id2;\n";
从BEING_DELETED及BEING_DELETED_CACHE中删除对应的doc id。
static const char* fts_end_delete_sql ="BEGIN\n""\n""DELETE FROM $BEING_DELETED;\n""DELETE FROM $BEING_DELETED_CACHE;\n";
参考函数:
fts_optimize_purge_deleted_doc_id_snapshot
InnoDB启动时,会创建一个后台线程,线程函数为fts_optimize_thread,工作队列为fts_optimize_wq,其主要目的是在满足一定条件时,对表自动进行optimize操作。
在如下两种情况,会向fts_optimize_wq中增加元组:
fts_optimize_add_table: 创建或打开一个新的带全文索引的表时,创建一个类型为FTS_MSG_ADD_TABLE并包含表对象指针的MSG,加入到fts_optimize_wq中,这些表禁止被从数据词典中驱逐;fts_optimize_remove_table: 删除表、DDL、释放表对象(dict_mem_table_free)、删除全文索引(fts_drop_index)等操作时,会创建一个类型为FTS_MSG_DEL_TABLE的MEG,加入到fts_optimize_wq队列中。
fts optimize线程对于FTS_MSG_ADD_TABLE类型的会将相应的表加入到调度队列,对于FTS_MSG_DEL_TABLE,则从调度队列中删除。其调度队列的成员类型为fts_slot_t。
当表上删除的数据量超过一千万(FTS_OPTIMIZE_THRESHOLD)行时,就会触发一次自动optimize table,但两次optimize的间隔不应低于300秒(FTS_OPTIMIZE_INTERVAL_IN_SECS)。
监控
我们可以通过几个INFORMATION_SCHEMA下的全文索引表来监控全文索引状态。
mysql> show tables like '%ft%';+-------------------------------------+| Tables_in_information_schema (%ft%) |+-------------------------------------+| INNODB_FT_CONFIG || INNODB_FT_BEING_DELETED || INNODB_FT_DELETED || INNODB_FT_DEFAULT_STOPWORD || INNODB_FT_INDEX_TABLE || INNODB_FT_INDEX_CACHE |+-------------------------------------+6 rows in set (0.00 sec)
想要从information_schema表中查询信息,需要先设置变量innodb_ft_aux_table,值为你要查询表的”dbname/tablename”。
全文索引停词
停词(STOP WORD)用于在分词时忽略那些常见的不重要的单词,InnoDB目前内建的停词可以从information_schema.INNODB_FT_DEFAULT_STOPWORD读取,用户也可以自己定义停词列表,方法很简单:创建一个和nformation_schema.INNODB_FT_DEFAULT_STOPWORD一模一样的表,将你想要的停词加入到其中,然后设置innodb_ft_server_stopword_table值为你创建的表名:”dbname/tabname”。
你也可以使用会话级别的参数innodb_ft_user_stopword_table来指定你想要的停词表,和上述创建规则一致,具体的参阅。
另外配置项innodb_ft_min_token_size及innodb_ft_max_token_size 用于表示一个单词的字符长度范围,在这个范围的连续字符串才会被当作一个单词。然而如果使用ngram解析器的话,有效单词长度受参数ngram_token_size控制。
可以关闭参数innodb_ft_enable_stopword,这样在分词时也会把预设的停词考虑进去。
从MySQL 5.7.3开始InnoDB支持全文索引插件,用户可以以Plugin的模式来定义自己的分词规则,或是引入社区开发的全文索引解析器,例如某些专业领域的分词,可能具有不同的规则。
全文索引插件有两种角色:第一种是替换内建的parser,读取输入文档,进行解析后,将分词传送给server;另一种角色是作为内建parser的协作者,可以把输入文档处理过后,再传送给内建parser。
如果你已经有一个基于MYISAM的全文索引插件了,也可以根据这篇官方文档的介绍,将其修改成InnoDB全文索引插件。
InnoDB N-gram parser
从MySQL5.7.6版本开始提供了一种内建的全文索引ngram parser,可以很好的支持CJK字符集(中文、日文、韩文),CJK有个共同点就是单词不像英语习惯那样根据空格进行分解的,因此传统的内建分词方式无法准确的对类似中文进行分词。
ngram parser内建在代码中,该解析器默安装,你可以通过指定索引属性(WITH PARSER ngram)来利用该parser,例如:
Query OK, 0 rows affected (0.26 sec)
N-Gram使用一种特殊的方式来进行分词,举个简单的例子,假设要对单词’abcd’进行分词,那么其分词结果为:
N取决于ngram_token_size的设置,默认值为2。
对于停词的处理,N-Gram和默认的parser不同,即只要每个token包含了(而不是精确匹配)停词,就不对其进行索引;另外空格总是作为一个停词,因此在分词取token时,空格会被忽略掉。
除了N-gram parser外,官方也支持了另外一种名为的插件,主要用于日语分词,但需要手动安装。

