
RMSProp
该接口实现均方根传播(RMSProp)法,是一种未发表的,自适应学习率的方法。原演示幻灯片中提出了RMSProp:[]中的第29张。等式如下所示:
第一个等式计算每个权重平方梯度的移动平均值,然后将梯度除以
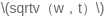
。
如果居中为真:
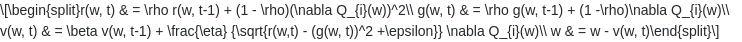
其中,
是超参数,典型值为0.9,0.95等。

是动量术语。
是一个平滑项,用于避免除零,通常设置在1e-4到1e-8的范围内。
参数:
learning_rate (float) - 全局学习率。
rho (float,可选) - rho是等式中的

,默认值0.95。
momentum (float,可选) - 方程中的β是动量项,默认值0.0。
centered (bool,可选) - 如果为True,则通过梯度的估计方差,对梯度进行归一化;如果False,则由未centered的第二个moment归一化。将此设置为True有助于模型训练,但会消耗额外计算和内存资源。默认为False。
parameters (list, 可选) - 指定优化器需要优化的参数。在动态图模式下必须提供该参数;在静态图模式下默认值为None,这时所有的参数都将被优化。
weight_decay (float|WeightDecayRegularizer,可选) - 正则化方法。可以是float类型的L2正则化系数或者正则化策略: L1Decay 、 。如果一个参数已经在 ParamAttr 中设置了正则化,这里的正则化设置将被忽略; 如果没有在 中设置正则化,这里的设置才会生效。默认值为None,表示没有正则化。
grad_clip (GradientClipBase, 可选) – 梯度裁剪的策略,支持三种裁剪策略: cn_api_fluid_clip_GradientClipByGlobalNorm 、 cn_api_fluid_clip_GradientClipByNorm 、 cn_api_fluid_clip_GradientClipByValue 。 默认值为None,此时将不进行梯度裁剪。
name (str, 可选) - 可选的名称前缀,一般无需设置,默认值为None。
抛出异常:
ValueError-如果learning_rate,rho,epsilon,momentum为None。
示例代码
step ( )
注意:
执行一次优化器并进行参数更新。
返回:None。
代码示例
import paddlea = paddle.rand([2,13], dtype="float32")linear = paddle.nn.Linear(13, 5)rmsprop = paddle.optimizer.RMSProp(learning_rate = 0.01,parameters = linear.parameters())out = linear(a)out.backward()rmsprop.step()rmsprop.clear_grad()
minimize ( loss, startup_program=None, parameters=None, no_grad_set=None )
为网络添加反向计算过程,并根据反向计算所得的梯度,更新parameters中的Parameters,最小化网络损失值loss。
参数:
loss (Tensor) – 需要最小化的损失值变量
parameters (list, 可选) – 待更新的Parameter或者Parameter.name组成的列表, 默认值为None,此时将更新所有的Parameter
返回: tuple(optimize_ops, params_grads),其中optimize_ops为参数优化OP列表;param_grads为由(param, param_grad)组成的列表,其中param和param_grad分别为参数和参数的梯度。在静态图模式下,该返回值可以加入到 Executor.run() 接口的 fetch_list 参数中,若加入,则会重写 use_prune 参数为True,并根据 feed 和 fetch_list 进行剪枝,详见 的文档。
示例代码
clear_gradients ( )
注意:
清除需要优化的参数的梯度。
代码示例
import paddlea = paddle.rand([2,13], dtype="float32")linear = paddle.nn.Linear(13, 5)rmsprop = paddle.optimizer.RMSProp(learning_rate=0.02,parameters=linear.parameters())out = linear(a)out.backward()rmsprop.step()rmsprop.clear_gradients()
set_lr ( value )
注意:
手动设置当前 optimizer 的学习率。当使用_LRScheduler时,无法使用该API手动设置学习率,因为这将导致冲突。
参数:
value (float) - 需要设置的学习率的值。
返回:None
代码示例
get_lr ( )
注意:
获取当前步骤的学习率。当不使用_LRScheduler时,每次调用的返回值都相同,否则返回当前步骤的学习率。
返回:float,当前步骤的学习率。
import paddleimport numpy as np# example1: _LRScheduler is not used, return value is all the sameemb = paddle.nn.Embedding(10, 10, sparse=False)rmsprop = paddle.optimizer.RMSProp(0.001, parameters = emb.parameters())lr = rmsprop.get_lr()print(lr) # 0.001linear = paddle.nn.Linear(10, 10)inp = paddle.rand([10,10], dtype="float32")out = linear(inp)loss = paddle.mean(out)bd = [2, 4, 6, 8]value = [0.2, 0.4, 0.6, 0.8, 1.0]scheduler = paddle.optimizer.lr.StepDecay(learning_rate=0.5, step_size=2, gamma=0.1)rmsprop = paddle.optimizer.RMSProp(scheduler,parameters=linear.parameters())# first step: learning rate is 0.2np.allclose(rmsprop.get_lr(), 0.2, rtol=1e-06, atol=0.0) # True# learning rate for different stepsret = [0.2, 0.2, 0.4, 0.4, 0.6, 0.6, 0.8, 0.8, 1.0, 1.0, 1.0, 1.0]for i in range(12):rmsprop.step()lr = rmsprop.get_lr()scheduler.step()

