
框架类FAQ
- 答复:当训练时使用的数据集数据量较大或者预处理逻辑复杂时,如果串行地进行数据读取,数据读取往往会成为训练效率的瓶颈。这种情况下通常需要利用多线程或者多进程的方法异步地进行数据载入,从而提高数据读取和整体训练效率。
- DataLoader.from_generator,有限的异步加载
该API提供了单线程和单进程的异步加载支持。但由于线程和进程数目不可配置,所以异步加速能力是有限的,适用于数据读取负载适中的场景。
具体使用方法及示例请参考API文档:。
- DataLoader,灵活的异步加载
该API提供了多进程的异步加载支持,也是paddle后续主推的数据读取方式。用户可通过配置num_workers指定异步加载数据的进程数目从而满足不同规模数据集的读取需求。
具体使用方法及示例请参考API文档:fluid.io.DataLoader
问题:使用多卡进行并行训练时,如何配置DataLoader进行异步数据读取?
- 答复:paddle1.8中多卡训练时设置异步读取和单卡场景并无太大差别,动态图模式下,由于目前仅支持多进程多卡,每个进程将仅使用一个设备,比如一张GPU卡,这种情况下,与单卡训练无异,只需要确保每个进程使用的是正确的卡即可。
具体示例请参考飞桨API 和 fluid.io.DataLoader 中的示例。
问题:在动态图使用paddle.dataset.mnist.train()获得数据后,如何转换为可操作的Tensor?
- 答复:调用
fluid.dygraph.to_varibale(data),即可将data数据转化为可以操作的动态图Tensor。
问题:如何给图片添加一个通道数,并进行训练?
- 答复:如果是在进入paddle计算流程之前,数据仍然是numpy.array的形式,使用numpy接口
numpy.expand_dims为图片数据增加维度后,再通过numpy.reshape进行操作即可,具体使用方法可查阅numpy的官方文档。
如果是希望在模型训练或预测流程中完成通道的操作,可以使用paddle对应的API 和 paddle.fluid.layers.reshape。
问题:有拓展Tensor维度的Op吗?
- 答复:有,请参考API 。
问题:如何从numpy.array生成一个具有shape和dtype的Tensor?
- 答复:在动态图模式下,可以参考如下示例:
具体请参考API paddle.fluid.dygraph.to_variable
问题:如何初始化一个随机数的Tensor?
- 答复:使用
numpy.random生成随机的numpy.array,再参考上一个问题中的示例创建随机数Tensor即可。
模型搭建
问题:如何不训练某层的权重?
- 答复:在
ParamAttr里设置learning_rate=0或trainable设置为False。具体请参考文档:
问题:stop_gradient=True的影响范围?
- 答复:如果fluid里某一层使用
stop_gradient=True,那么这一层之前的层都会自动stop_gradient=True,梯度不再回传。
问题:请问fluid.layers.matmul和fluid.layers.mul有什么区别?
- 答复:
matmul支持broadcast和任意阶相乘。mul会把输入都转成两维去做矩阵乘。
问题:在模型组网时,inplace参数的设置会影响梯度回传吗?经过不带参数的op之后,梯度是否会保留下来?
- 答复:inplace 参数不会影响梯度回传。只要用户没有手动设置stop_gradient=True,梯度都会保留下来。
- 答复:在1.8版本的动态图模式下,CPU训练加速可以从以下两点进行配置:
使用多进程DataLoader加速数据读取:训练数据较多时,数据处理往往会成为训练速度的瓶颈,paddle提供了异步数据读取接口DataLoader,可以使用多进程进行数据加载,充分利用多处理的优势,具体使用方法及示例请参考API文档:fluid.io.DataLoader。
推荐使用支持MKL(英特尔数学核心函数库)的paddle安装包,MKL相比Openblas等通用计算库在计算速度上有显著的优势,能够提升您的训练效率。
问题:使用NVIDIA多卡运行Paddle时报错 Nccl error,如何解决?
- 答复:这个错误大概率是环境配置不正确导致的,建议您使用NVIDIA官方提供的方法参考检测自己的环境是否配置正确。具体地,可以使用 检测您的环境;如果检测不通过,请登录 NCCL官网 下载NCCl,安装后重新检测。
问题:多卡训练时启动失败,Error:Out of all 4 Trainers,如何处理?
- 问题描述:多卡训练时启动失败,显示如下信息:
报错分析:主进程发现一号卡(逻辑)上的训练进程退出了。
解决方法:查看一号卡上的日志,找出具体的出错原因。
paddle.distributed.launch启动多卡训练时,设置--log_dir参数会将每张卡的日志保存在设置的文件夹下。
问题:训练时报错提示显存不足,如何解决?
- 答复:可以尝试按如下方法解决:
检查是当前模型是否占用了过多显存,可尝试减小
batch_size;开启以下三个选项:
详细请参考官方文档 调整相关配置。
此外,建议您使用AI Studio 学习与 实训社区训练,获取免费GPU算力,提升您的训练效率。
问题:如何提升模型训练时的GPU利用率?
-
如果数据预处理耗时较长,可使用DataLoader加速数据读取过程,具体请参考API文档:。
如果提高GPU计算量,可以增大
batch_size,但是注意同时调节其他超参数以确保训练配置的正确性。
以上两点均为比较通用的方案,其他的优化方案和模型相关,可参考官方模型库 models 中的具体示例。
问题:如何处理变长ID导致程序内存占用过大的问题?
答复:请先参考 开启存储优化开关,包括显存垃圾及时回收和Op内部的输出复用输入等。若存储空间仍然不够,建议:
降低
batch_size;对index进行排序,减少padding的数量。
问题:训练过程中如果出现不收敛的情况,如何处理?
问题:Loss为NaN,如何处理?
- 答复:可能由于网络的设计问题,Loss过大(Loss为NaN)会导致梯度爆炸。如果没有改网络结构,但是出现了NaN,可能是数据读取导致,比如标签对应关系错误。还可以检查下网络中是否会出现除0,log0的操作等。
问题:使用GPU训练时报错,Error:incompatible constructor arguments.,如何处理?
问题描述:

报错分析:
CUDAPlace()接口没有指定GPU的ID编号导致。
问题:增量训练中,如何保存模型和恢复训练?
- 答复:在增量训练过程中,不仅需要保存模型的参数,也需要保存优化器的参数。
具体地,在1.8版本中需要使用Layer和Optimizer的state_dict和set_dict方法配合fluid.save_dygraph/load_dygraph使用。简要示例如下:
更多介绍请参考以下API文档:
- 答复:报错是由于没有安装GPU版本的PaddlePaddle,CPU版本默认不包含CUDA检测功能。使用
pip install paddlepaddle-gpu -U即可。
问题:训练后的模型很大,如何压缩?
- 答复:建议您使用飞桨模型压缩工具PaddleSlim。PaddleSlim是飞桨开源的模型压缩工具库,包含模型剪裁、定点量化、知识蒸馏、超参搜索和模型结构搜索等一系列模型压缩策略,专注于模型小型化技术。
模型保存与加载
答复:主要差别在于保存结果的应用场景:
save接口(2.0的
paddle.static.save或者1.8的fluid.io.save)该接口用于保存训练过程中的模型和参数,一般包括
*.pdmodel,*.pdparams,*.pdopt三个文件。其中*.pdmodel是训练使用的完整模型program描述,区别于推理模型,训练模型program包含完整的网络,包括前向网络,反向网络和优化器,而推理模型program仅包含前向网络,*.pdparams是训练网络的参数dict,key为变量名,value为Tensor array数值,*.pdopt是训练优化器的参数,结构与*.pdparams一致。save_inference_model接口(2.0的
paddle.static.save_inference_model或者1.8的fluid.io.save_inference_model)该接口用于保存推理模型和参数,2.0的
paddle.static.save_inference_model保存结果为*.pdmodel和*.pdiparams两个文件,其中*.pdmodel为推理使用的模型program描述,*.pdiparams为推理用的参数,这里存储格式与*.pdparams不同(注意两者后缀差个i),*.pdiparams为二进制Tensor存储格式,不含变量名。1.8的fluid.io.save_inference_model默认保存结果为__model__文件,和以参数名为文件名的多个分散参数文件,格式与2.0一致。关于更多2.0动态图模型保存和加载的介绍可以参考教程:
问题:如何将本地数据传入fluid.dygraph.Embedding的参数矩阵中?
- 答复:需将本地词典向量读取为NumPy数据格式,然后使用这个op初始化
fluid.dygraph.Embedding里的param_attr参数,即可实现加载用户自定义(或预训练)的Embedding向量。
问题:如何实现网络层中多个feature间共享该层的向量权重?
- 答复:将所有网络层中
param_attr参数里的name设置为同一个,即可实现共享向量权重。如使用embedding层时,可以设置param_attr=fluid.ParamAttr(name="word_embedding"),然后把param_attr传入embedding中。
问题:使用optimizer或ParamAttr设置的正则化和学习率,二者什么差异?
- 答复:ParamAttr中定义的
regularizer优先级更高。若ParamAttr中定义了regularizer,则忽略Optimizer中的regularizer;否则,则使用Optimizer中的regularizer。ParamAttr中的学习率默认为1,在对参数优化时,最终的学习率等于optimizer的学习率乘以ParamAttr的学习率。
问题:如何导出指定层的权重,如导出最后一层的weights和bias?
- 答复:使用
save_vars保存指定的vars,然后使用load_vars加载对应层的参数值。具体示例请见API文档:load_vars 和 。
问题:训练过程中如何固定网络和Batch Normalization(BN)?
- 答复:
对于固定BN:设置
use_global_stats=True,使用已加载的全局均值和方差:global mean/variance,具体内容可查看官网文档BatchNorm。对于固定网络层:如: stage1→ stage2 → stage3 ,设置stage2的输出,假设为y,设置
y.stop_gradient=True,那么, stage1→ stage2整体都固定了,不再更新。
问题:优化器设置时报错AttributeError: parameter_list argument given to the Optimizer should not be None in dygraph mode.,如何处理?
错误分析:必选参数缺失导致。
答复:飞桨框架1.7版本之后,动态图模式下,需要在optimizer的设置中加入必选项
parameter_list。
问题:fluid.layer.pool2d的全局池化参数和设置参数有关系么?
- 答复:如果设置
global_pooling,则设置的pool_size将忽略,不会产生影响。
问题:训练的step在参数优化器中是如何变化的?
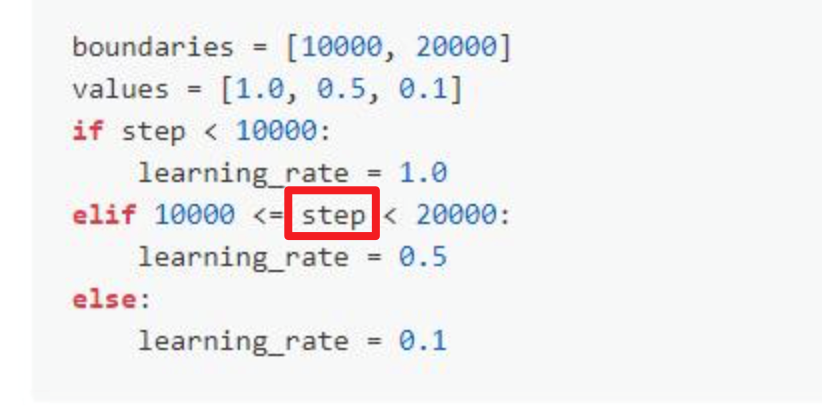
-
step表示的是经历了多少组mini_batch,其统计方法为exe.run(对应Program)运行的当前次数,即每运行一次exe.run,step加1。举例代码如下:
问题:如何修改全连接层参数,比如weight,bias?
- 答复:可以通过
param_attr设置参数的属性,fluid.ParamAttr( initializer=fluid.initializer.Normal(0.0, 0.02), learning_rate=2.0),如果learning_rate设置为0,该层就不参与训练。也可以构造一个numpy数据,使用fluid.initializer.NumpyArrayInitializer来给权重设置想要的值。
应用预测
问题:load_inference_model在加载预测模型时能否用py_reader读取?
- 答复:目前
load_inference_model加载进行的模型还不支持py_reader输入。
- 答复:可以在设置config时使用
config.enable_profile()统计预测时每个算子和数据搬运的耗时。对于推理api的使用,可以参考官网文档。示例代码:

