
retinanet_target_assign
该OP是从输入anchor中找出训练检测模型 所需的正负样本,并为每个正负样本分配用于分类的目标值和位置回归的目标值,同时从全部anchor的类别预测值cls_logits、位置预测值bbox_pred中取出属于各正负样本的部分。
正负样本的查找准则如下:
若anchor与某个真值框之间的Intersection-over-Union(IoU)大于其他anchor与该真值框的IoU,则该anchor是正样本,且被分配给该真值框;
若anchor与某个真值框之间的IoU大于等于positive_overlap,则该anchor是正样本,且被分配给该真值框;
若anchor与某个真值框之间的IoU介于[0, negative_overlap),则该anchor是负样本;
不满足以上准则的anchor不参与模型训练。
在RetinaNet中,对于每个anchor,模型都会预测一个C维的向量用于分类,和一个4维的向量用于位置回归,因此各正负样本的分类目标值也是一个C维向量,各正样本的位置回归目标值也是一个4维向量。对于正样本而言,若其被分配的真值框的类别是i,则其分类目标值的第i-1维为1,其余维度为0;其位置回归的目标值由anchor和真值框之间位置差值计算得到。对于负样本而言,其分类目标值的所有维度都为0,因负样本不参与位置回归的训练,故负样本无位置回归的目标值。
分配结束后,从全部anchor的类别预测值cls_logits中取出属于各正负样本的部分,从针对全部anchor的位置预测值bbox_pred中取出属于各正样本的部分。
参数:
bbox_pred (Variable) – 维度为
的3-D Tensor,表示全部anchor的位置回归预测值。其中,第一维N表示批量训练时批量内的图片数量,第二维M表示每张图片的全部anchor的数量,第三维4表示每个anchor有四个坐标值。数据类型为float32或float64。
cls_logits (Variable) – 维度为
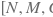
的3-D Tensor,表示全部anchor的分类预测值。 其中,第一维N表示批量训练时批量内的图片数量,第二维M表示每张图片的全部anchor的数量,第三维C表示每个anchor需预测的类别数量( 注意:不包括背景 )。数据类型为float32或float64。
anchor_var (Variable) – 维度为
的2-D Tensor,表示在后续计算损失函数时anchor坐标值的缩放比例。其中,第一维M表示每张图片的全部anchor的数量,第二维4表示每个anchor有四个坐标缩放因子。数据类型为float32或float64。anchor_var的生成请参考OP anchor_generator。
gt_boxes (Variable) – 维度为
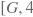
且LoD level必须为1的2-D LoDTensor,表示批量训练时批量内的真值框位置。其中,第一维G表示批量内真值框的总数,第二维表示每个真值框有四个坐标值。数据类型为float32或float64。
gt_labels (variable) – 维度为
且LoD level必须为1的2-D LoDTensor,表示批量训练时批量内的真值框类别,数值范围为
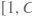
。其中,第一维G表示批量内真值框的总数,第二维表示每个真值框只有1个类别。数据类型为int32。
is_crowd (Variable) – 维度为
且LoD level必须为1的1-D LoDTensor,表示各真值框是否位于重叠区域,值为1表示重叠,则不参与训练。第一维G表示批量内真值框的总数。数据类型为int32。
im_info (Variable) – 维度为
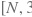
的2-D Tensor,表示输入图片的尺寸信息。其中,第一维N表示批量训练时批量内的图片数量,第二维3表示各图片的尺寸信息,分别是网络输入尺寸的高和宽,以及原图缩放至网络输入尺寸的缩放比例。数据类型为float32或float64。
num_classes (int32) – 分类的类别数量,默认值为1。
返回:
predict_scores (Variable) – 维度为
的2-D Tensor,表示正负样本的分类预测值。其中,第一维F为批量内正样本的数量,B为批量内负样本的数量,第二维C为分类的类别数量。数据类型为float32或float64。
predict_location (Variable) — 维度为
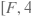
的2-D Tensor,表示正样本的位置回归预测值。其中,第一维F为批量内正样本的数量,第二维4表示每个样本有4个坐标值。数据类型为float32或float64。
target_label (Variable) — 维度为
的2-D Tensor,表示正负样本的分类目标值。其中,第一维F为正样本的数量,B为负样本的数量,第二维1表示每个样本的真值类别只有1类。数据类型为int32。
target_bbox (Variable) — 维度为
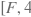
的2-D Tensor,表示正样本的位置回归目标值。其中,第一维F为正样本的数量,第二维4表示每个样本有4个坐标值。数据类型为float32或float64。
bbox_inside_weight (Variable) — 维度为
的2-D Tensor,表示位置回归预测值中是否属于假正样本,若某个正样本为假,则bbox_inside_weight中对应维度的值为0,否则为1。第一维F为正样本的数量,第二维4表示每个样本有4个坐标值。数据类型为float32或float64。
返回类型:元组(tuple),元组中的元素predict_scores,predict_location,target_label,target_bbox,bbox_inside_weight,fg_num都是Variable。
代码示例

