
dynamic_gru
注意:该OP的输入只能是LoDTensor,如果您需要处理的输入是Tensor类型,请使用StaticRNN(fluid.layers. )。
该OP用于在完整序列上逐个时间步的进行单层Gated Recurrent Unit(GRU)的计算,单个时间步内GRU的计算支持以下两种计算方式:
如果origin_mode为True,则使用的运算公式来自论文 Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation 。
如果origin_mode为False,则使用的运算公式来自论文 。
公式如下:
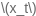
其中,
为当前时间步的输入,这个输入并非 input,该OP不包含

的计算, 注意 要在该OP前使用大小为 的3倍的全连接层并将其输出作为 input;
为前一时间步的隐状态 ;
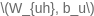
、

和
分别代表了GRU单元中update gate(更新门)、reset gate(重置门)、candidate hidden(候选隐状态)和隐状态输出;

为逐个元素相乘;
、

和
分别代表更新门、重置门和候选隐状态在计算时使用的权重矩阵和偏置。在实现上,三个权重矩阵合并为一个

形状的Tensor存放,其中
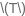
为隐单元的数目;权重Tensor存放布局为: WuhWuh 和 WrhWrh 拼接为 [D,D×2][D,D×2] 形状位于前半部分,WchWch 以 [D,D][D,D] 形状位于后半部分。
参数:
input (Variable) – LoD level为1的LoDTensor,表示经线性变换后的序列输入,形状为 [T,D×3][T,D×3] ,其中 TT 表示mini-batch中所有序列长度之和, DD 为隐状态特征维度的大小。数据类型为float32或float64。
size (int) – 隐状态特征维度的大小
bias_attr (ParamAttr,可选) - 指定偏置参数属性的对象。默认值为None,表示使用默认的偏置参数属性。具体用法请参见 ParamAttr 。
is_reverse (bool,可选) – 指明是否按照和输入相反的序列顺序计算,默认为False。
candidate_activation (str,可选) – 公式中 actcactc 激活函数的类型。支持identity、sigmoid、tanh、relu四种激活函数类型,默认为tanh。
h_0 (Variable,可选) – 表示初始隐状态的Tensor,若未提供,则默认为0。其形状为 [N,D][N,D] , 其中 NN 为输入mini-batch中序列的数目, DD 为隐状态特征维度的大小。数据类型与
input相同。默认值为None。
返回: 形状为 [T,D][T,D] 、LoD level为1的LoDTensor,其中 TT 表示mini-batch中所有序列长度之和, DD 为隐状态特征维度的大小。表示经过GRU变换的输出特征序列,和 具有相同的LoD(序列长度)和数据类型。
代码示例

