
TrainingHelper
TrainingHelper是 的子类。作为解码helper,它在每个解码时间步通过在完整序列输入 inputs 的相应位置切片作为各步的输入,并且使用 argmax 根据 cell.call() 的输出进行采样。 由于要求有完整的序列输入 inputs ,TrainingHelper主要用于以teach-forcing的方式进行最大似然训练,采样得到的内容通常不会使用。
参数:
inputs (Variable) - 单个tensor变量或tensor变量组成的嵌套结构。当
time_major == False时,tensor的形状应为;当
time_major == True时,tensor的形状应为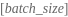
。在解码的每一步都要从中切片取出相应的数据。
sequence_length (Variable) - 形状为
的tensor。它存储了
inputs中每个样本的实际长度,可以据此来标识每个解码步中每个样本是否结束。
示例代码
initialize ( )
TrainingHelper初始化,其通过在完整序列输入 inputs 中首个时间步的位置上切片,以此作为第一个解码步的输入,并给出每个序列是否结束的初始标识。这是 BasicDecoder 初始化的一部分。
返回: 的二元组, initial_inputs 是单个tensor变量或tensor变量组成的嵌套结构,tensor的形状是
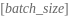
。 initial_finished 是一个bool类型且形状为
的tensor。
返回类型:tuple
sample ( time, outputs, states )
使用 argmax 根据 outputs 进行采样。由于使用完整序列中的切片作为下一解码步的输入,采样得到的内容通常不会使用。
参数:
outputs (Variable) - tensor变量,通常其数据类型为float32或float64,形状为 [batch_size,vocabulary_size][batch_size,vocabulary_size] ,表示当前解码步预测产生的logit(未归一化的概率),和由
BasicDecoder.output_fn(BasicDecoder.cell.call())返回的outputs是同一内容。
返回:数据类型为int64形状为 [batch_size][batch_size] 的tensor,表示采样得到的id。
返回类型:Variable
next_inputs ( time, outputs, states, sample_ids )
从完整序列输入中当前时间步的位置上切片,以此作为产生下一解码步的输入;同时直接使用输入参数中的 作为下一解码步的状态;并比较当前时间与每个序列的大小,依此产生每个序列是否结束的标识。
参数:
time (Variable) - 调用者提供的形状为[1]的tensor,表示当前解码的时间步长。其数据类型为int64。
outputs (Variable) - tensor变量,通常其数据类型为float32或float64,形状为 [batch_size,vocabulary_size][batch_size,vocabulary_size] ,表示当前解码步预测产生的logit(未归一化的概率),和由
BasicDecoder.output_fn(BasicDecoder.cell.call())返回的outputs是同一内容。sample_ids (Variable) - 数据类型为int64形状为 [batch_size][batch_size] 的tensor,和由
sample()返回的sample_ids是同一内容。
返回: (finished, next_inputs, next_states) 的三元组。 next_inputs, next_states 均是单个tensor变量或tensor变量组成的嵌套结构,tensor的形状是 [batch_size,…][batch_size,…] , next_states 和输入参数中的 相同; finished 是一个bool类型且形状为 [batch_size][batch_size] 的tensor。
返回类型:tuple

